Andrew NG 深度学习课程笔记:梯度下降与向量化操作从属于笔者的Deep Learning Specialization 课程笔记系列文章,本文主要记述了笔者学习 Andrew NG Deep Learning Specialization 系列课程的笔记与代码实现。注意,本篇有大量的数学符号与表达式,部分网页并不支持;可以前往源文件查看较好的排版或者在自己的编辑器中打开。
梯度下降与向量化操作
我们在前文二元分类与 Logistic 回归中建立了 Logistic 回归的预测公式:
$$
hat{y} = sigma(w^Tx + b), , sigma(z) = frac{1}{1+e^{-z}}
$$
整个训练集的损失函数为:
$$
J(w,b) =
frac{1}{m}sum_{i=1}^mL(hat{y}^{(i)} - y^{(i)}) = \
-frac{1}{m} sum_{i=1}^m [y^{(i)}loghat{y}^{(i)} + (1-y^{(i)})log(1-hat{y}^{(i)})]
$$
模型的训练目标即是寻找合适的 $w$ 与 $b$ 以最小化代价函数值;简单起见我们先假设 $w$ 与 $b$ 都是一维实数,那么可以得到如下的 $J$ 关于 $w$ 与 $b$ 的图:
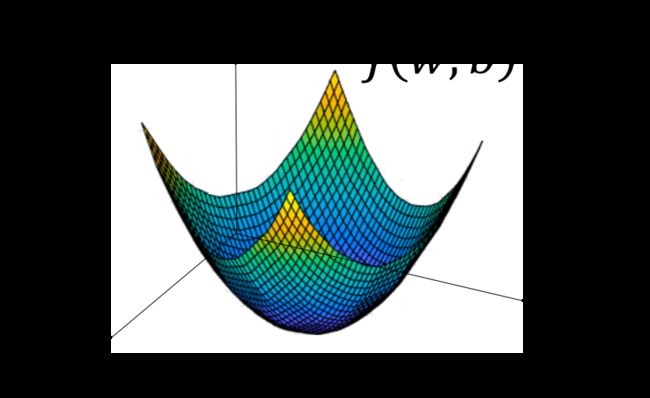
上图所示的函数 $J$ 即是典型的凸函数,与非凸函数的区别在于其不含有多个局部最低点;选择这样的代价函数就保证了无论我们初始化模型参数如何,都能够寻找到合适的最优解。如果我们仅考虑对于 $w$ 参数进行更新,则可以得到如下的一维图形:
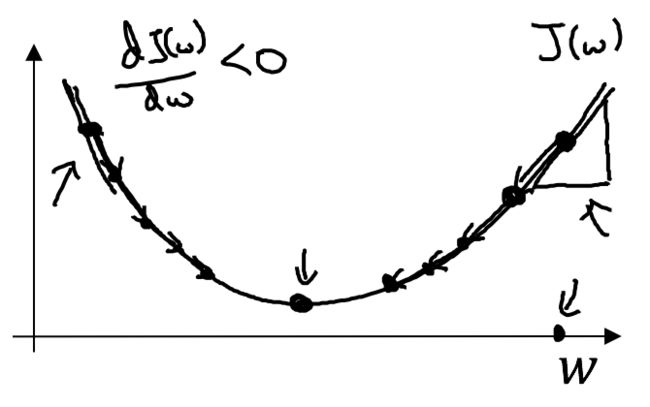
参数 $w$ 的更新公式为:
$$
w := w - alpha frac{dJ(w)}{dw}
$$
其中 $alpha$ 表示学习速率,即每次更新的 $w$ 的步伐长度;当 $w$ 大于最优解 $w'$ 时,导数大于0;即 $frac{dJ(w)}{dw}$ 的值大于 0,那么 $w$ 就会向更小的方向更新。反之当 $w$ 小于最优解 $w'$ 时,导数小于 0,那么 $w$ 就会向更大的方向更新。
导数
本部分是对于微积分中导数(Derivative)相关理论进行简单讲解,熟悉的同学可以跳过。
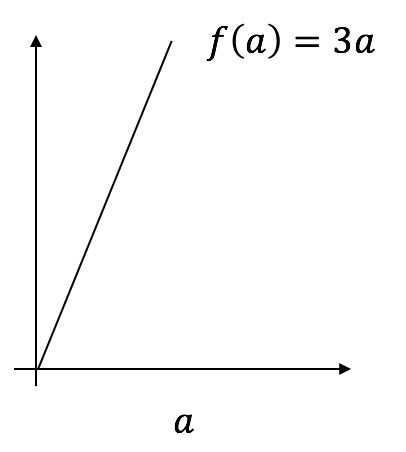
上图中,$a = 2$ 时,$f(a) = 6$;$a = 2.001$ 时,$f(a) = 6.003$,导数为 $frac{6.003 - 6}{2.001 - 2} = 3$;在某个直线型函数中,其导数值是恒定不变的。我们继续考虑下述二次函数:
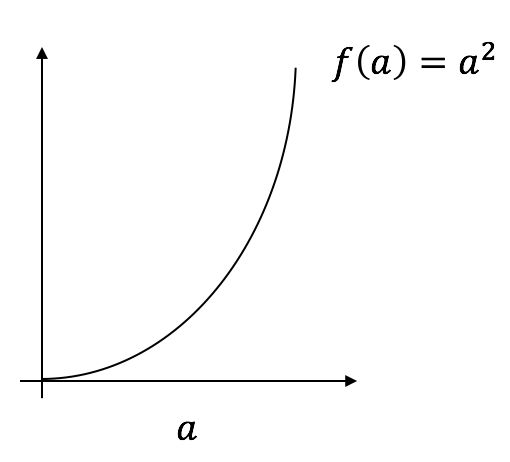
上图中,$a = 2$ 时,$f(a) = 4$;$a = 2.001$ 时,$f(a) approx 4.004$,此处的导数即为 4。而当 $a = 5$ 时,此处的导数为 10;可以发现二次函数的导数值随着 $x$ 值的变化而变化。下表列举出了常见的导数:

下表列举了常用的导数复合运算公式:

计算图(Computation Graph)
神经网络中的计算即是由多个计算网络输出的前向传播与计算梯度的后向传播构成,我们可以将复杂的代价计算函数切割为多个子过程:
$$
J(a, b, c) = 3 times (a + bc)
$$
定义 $u = bc$ 以及 $v = a + u$ 和 $J = 3v$,那么整个计算图可以定义如下:
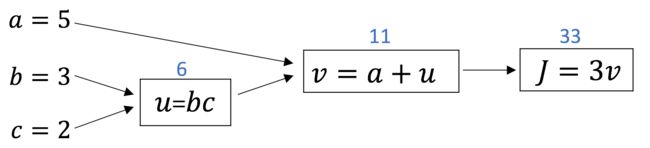
根据导数计算公式,我们可知:
$$
frac{dJ}{dv} = 3, ,
frac{dJ}{da} = frac{dJ}{dv} frac{dv}{da} = 3
$$
在复杂的计算图中,我们往往需要经过大量的中间计算才能得到最终输出值与原始参数的导数 $dvar = frac{dFinalOutputVar}{d{var}'}$,这里的 $dvar$ 即表示了最终输出值相对于任意中间变量的导数。而所谓的反向传播(Back Propagation)即是当我们需要计算最终值相对于某个特征变量的导数时,我们需要利用计算图中上一步的结点定义。
Logistic 回归中的导数计算
我们在上文中讨论过 Logistic 回归的损失函数计算公式为:
$$
z = w^Tx + b \
hat{y} = a = sigma(z) \
L(a,y) = -( ylog(a) + (1-y)log(1-a) )
$$
这里我们假设输入的特征向量维度为 2,即输入参数共有 $x_1, w_1, x_2, w_2, b$ 这五个;可以推导出如下的计算图:
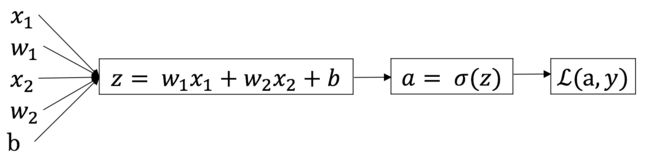
首先我们反向求出 $L$ 对于 $a$ 的导数:
$$
da = frac{dL(a,y)}{da} = -frac{y}{a} + frac{1-y}{1-a}
$$
然后继续反向求出 $L$ 对于 $z$ 的导数:
$$
dz = frac{dL}{dz}
=frac{dL(a,y)}{dz}
= frac{dL}{da} frac{da}{dz}
= a-y
$$
依次类推求出最终的损失函数相较于原始参数的导数之后,根据如下公式进行参数更新:
$$
w_1 := w_1 - alpha dw_1 \
w_2 := w_2 - alpha dw_2 \
b := b - alpha db
$$
接下来我们需要将对于单个用例的损失函数扩展到整个训练集的代价函数:
$$
J(w,b) = frac{1}{m} sum_{i=1}^m L(a^{(i)},y) \
a^{(i)} = hat{y}^{(i)} = sigma(z^{(i)}) = sigma(w^Tx^{(i)} + b)
$$
我们可以对于某个权重参数 $w_1$,其导数计算为:
$$
frac{partial J(w,b)}{partial w_1} = frac{1}{m} sum_{i=1}^m frac{partial}{partial w_1}L(a^{(i)},y^{(i)})
$$
完整的 Logistic 回归中某次训练的流程如下,这里仅假设特征向量的维度为 2:
向量化操作
在上述的 $m$ 个训练用例的 Logistic 回归中,每次训练我们需要进行两层循环,外层循环遍历所有的特征,内层循环遍历所有的训练用例;如果特征向量的维度或者训练用例非常多时,多层循环无疑会大大降低运行效率,因此我们使用向量化(Vectorization)操作来进行实际的训练。我们首先来讨论下何谓向量化操作。在 Logistic 回归中,我们需要计算 $z = w^Tx + b$,如果是非向量化的循环方式操作,我们可能会写出如下的代码:
z = 0;
for i in range(n_x):
z += w[i] * x[i]
z += b而如果是向量化的操作,我们的代码则会简洁很多:
z = np.dot(w, x) + b在未来的章节中我们会实际比较循环操作与向量化操作二者的性能差异,可以发现向量化操作能够带来近百倍的性能提升;目前无论 GPU 还是 CPU 环境都内置了并行指令集, SIMD(Single Instruction Multiple Data),因此无论何时我们都应该尽可能避免使用显式的循环。Numpy 还为我们提供了很多便捷的向量转化操作,譬如 np.exp(v) 用于进行指数计算,np.log(v) 用于进行对数计算,np.abs(v) 用于进行绝对值计算。
下面我们将上述的 Logistic 回归流程转化为向量化操作,其中输入数据可以变为 $n_x times m$ 的矩阵,即共有 $m$ 个训练用例,每个用例的维度为 $n_x$:
$$
Z = np.dot(W^TX) + b \
A = [a^{(1)},a^{(2)},...,a^{(m)}] = sigma(z)
$$
我们可以得到各个变量梯度计算公式为:
$$
dZ = A - Y = [a^{(1)} y^{(1)}...] \
db = frac{1}{m}sum_{i=1}^mdz^{(i)}=frac{1}{m}np.sum(dZ) \
dW = frac{1}{m} X dZ^{T}=
frac{1}{m}
begin{bmatrix}
vdots \
x^{(i1)} ... x^{(im)} \
vdots \
end{bmatrix}
begin{bmatrix}
vdots \
dz^{(i)} \
vdots \
end{bmatrix} \
= frac{1}{m}
begin{bmatrix}
vdots \
x^{(1)}dz^{(1)} + ... + x^{(m)}dz^{(m)} \
vdots \
end{bmatrix} \
$$
延伸阅读
机器学习、深度学习与自然语言处理领域推荐的书籍列表
Andrew NG 深度学习课程笔记:神经网络、有监督学习与深度学习
基于 Python 的简单自然语言处理实践