论文翻译-A Comprehensive Survey on Graph Neural Networks《图神经网络GNN综述》
文章目录
- 1 简介
- 1.1 GNN简史
- 1.2 GNN的相关研究
- 1.3 GNN vs 网络嵌入
- 1.4 文章的创新性
- 2 基本的图概念的定义
- 3 GNN分类和框架
- 3.1 GNNs分类
- 3.2 框架
- 4 图卷积网络
- 4.1 基于图谱的GCN
- 4.1.1 图信号处理
- 4.1.2 基于谱的GCN方法
- 4.1.3 总结
- 4.2 基于空间的GCN
- 4.2.1 基于循环的空间GCNs
- 4.2.2 基于组合的空间GCNs
- 4.2.3 空间GCNs的其他变体
- 4.2.4 总结
- 4.3 图池模块
- 4.4 基于光谱和空间的GCNs的对比
- 5 超GCNs架构
- 5.1 图注意力网络
- 5.1.1 GAN方法
- 5.1.2 总括
- 5.2 图自编码
- 5.2.1 基于GCN的自编码器
- 5.2.2 图自编码的其他变体
- 5.2.3 总结
- 5.3 图生成网络(GGN)
- 5.3.1基于GCN的图生成网络
- 5.3.2 GGN的其他变体
- 5.3.3 总结
- 5.4 图时空网络
- 5.4.1 基于GCN的图时空网络
- 5.4.2 其他变体
- 5.4.3 总结
- 6 应用
- 6.1 基准数据集
- 6.2 开源项目
- 6.3 实际应用
- 6.3.1计算机视觉
- 6.3.2推荐系统
- 6.3.3交通
- 6.3.4生物化学
- 6.3.5其他
- 7 未来发展方向
- 7.1 Go Deep
- 7.2 Receptive Filed
- 7.3 Scalability
- 7.4 Dynamics and Heterogeneity
- 8 总括
近年来,深度学习彻底改变了很多机器学习任务,从图像分类,视频处理到语音识别,自然语言处理等,但是通常来说,这些任务的数据都是欧式数据。现实中,很多数据都是非线性的,不是欧式数据,因此被表示为数据之间复杂关系和相互依赖的图结构。
图数据的复杂性给现有的机器学习算法带来了重大挑战。最近,出现了许多关于扩展图数据的深度学习方法的研究。本文对图神经网络(GNNs)在数据挖掘和机器学习方面的应用做了全面概述。
提出一种新的分类方法对GNNs各种方法进行分类。着眼于图卷积网络(GCN),回顾了一些最近提出来的新的架构,包括Graph attention networks(图注意力网络),Graph autoencoders(图自编码),Graph generative networks(图生成网络)以及Graph spatial-temporal networks(图时空网络)。
另外,进一步讨论了图神经网络在各个领域的应用,总结了现有算法在不同任务中的开源代码,并提出了领域的潜在研究方向。
1 简介
神经网络近期的成功推动了模式识别和数据挖掘的研究,许多机器学习任务,例如目标检测,机器翻译,语音识别,曾经都严重依赖棘手的特征工程提取数据集的特征,现在已经被端到端的学习模式彻底改变,也就是卷积神经网络(CNN),长短时记忆网络(LSTM),和自编码(AE)。深度学习在许多领域的成功部分归功于快速发展的计算资源(如GPU)和大量训练数据,部分归功于深度学习从欧氏数据(如图像、文本和视频)中提取有效的数据表示。以图像分析为例,图像为欧式空间的规则表示,CNN能够利用图像数据的平移不变性,局部连结性和组合性,也就是CNN能够为各种图像分析任务提取整个数据集共享的局部特征。
深度学习在欧式数据上取得了巨大的成功,但是,越来越多的应用需要对非欧式数据进行分析。例如,在电子商务中,一个基于图的学习系统能够利用用户与商品之间的交互做出非常准确的推荐;在化学中,需要识别被建模为图结构的分子的生物活性以发现新的药物;在引文网络中,论文需要通过被引用的关系相互连接,然后通过挖掘关系被分成不同的组。图数据不规则,每个图的无序节点大小是可变的,且每个结点有不同数量的邻居结点,因此一些重要的操作如卷积能够在图像数据上轻易计算,但是不适用于图数据,可见图数据的复杂性给现有的机器学习算法带来了巨大的挑战 。此外,现有的机器学习算法假设数据之间是相互独立的,但是,图数据中每个结点都通过一些复杂的连接信息与其他邻居相关,这些连接信息用于捕获数据之间的相互依赖关系,包括,引用,关系,交互。
近年来,人们对扩展基于图数据的深度学习越来越感兴趣。在深度学习的驱动下,研究人员借鉴CNN,LSTM,深度AE的思想设计了图神经网路的架构。为了处理复杂的图数据,在过去几年中,对重要算子的泛化和定义发展越来越快。例如,图1说明了图卷积算子是如何受标准2-D卷积算子的启发的。本文对图神经网络进行了一个全面的概述。
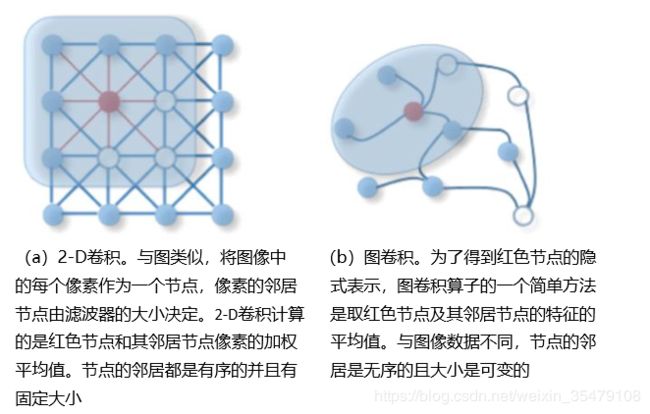
图 1 2-D卷积和图卷积
1.1 GNN简史
图神经网络的表示法最早在Gori等(2005)[16]中提出,在Scarselli等(2009)[17]中进一步阐述。这些早期的研究通过迭代的方式,利用循环神经结构传播邻居信息,直到达到一个稳定的不动点,来学习目标节点的表示。这些过程计算代价大,因此很多研究在克服这些困难[18],[19].本文推广图神经网络术语表示所有的针对图数据的深度学习方法。
受CNN在计算机视觉领域巨大成功的启发,很多方法致力于重新定义卷积算子,这些方法都属于图卷积网络(GCN)。Bruna et al.(2013)首次基于谱图理论[20]设计了一种图卷积的变体,自此,基于谱图的卷积网络[12]、[14]、[21]、[22]、[23]的改进、扩展和逼近越来越多。但是谱图方法一般同时处理整个图,而且难以并行处理或缩放,所以近年来基于空间的图卷积[24], [25], [26], [27]发展越来越快。这些方法通过聚集节点信息直接在图域进行卷积。结合抽样策略,计算可以在批节点而不是整个图[24],[27]上进行,能够减少计算复杂度。
近年来,除了图形卷积网络外,还出现了许多新的图形神经网络。这些方法包括图注意网络(GAN)、图的自动编码器(GAE)、图的生成网络(GGN)和图时空网络(GSTN)。
1.2 GNN的相关研究
相关的GNN综述很少,Bronstein et al.[8]使用几何深度学习的符号,概述了非欧式域的深度学习方法,包括图形和流形。因为是先驱性工作,所以漏掉了几个重要的基于空间的方法,包括[15]、[19]、[24]、[26]、[27]、[28]。此外,本研究未涵盖一些新开发的架构,而这些架构对于GCN同样重要。本文对图注意网络(GAN)、图的自动编码器(GAE)、图的生成网络(GGN)和图时空网络(GSTN)等学习范式进行了综合评述。 Battaglia等人[29]将位置图网络作为构建块学习关系数据,使用统一的框架对部分神经网络做了回顾。但是,这个泛化的网络高度抽象,对原始论文中的方法阐述不足。Lee等人[30]对GNN的分支GAT部分进行了总结。最近,张[31]等对GNN做了一个最近的研究,但是缺少对GGN和GSTN的研究。综上,现有GNN方面的综述都不完整。
1.3 GNN vs 网络嵌入
GNN的研究与图嵌入或网络嵌入密切相关,是数据挖掘和机器学习[32],[33],[34],[35],[36],[37]日益关注的另一个课题。网络嵌入致力于在一个低维向量空间进行网络节点表示,同时保护网络拓扑结构和节点的信息,便于后续的图像分析任务,包括分类,聚类,推荐等,能够使用简单现成的机器学习算法(例如,使用SVM分类)。许多网络嵌入算法都是典型的无监督算法,它们可以大致分为三种类型[32],即,矩阵分解[38]、[39]、随机游走[40]、深度学习。基于深度学习的网络嵌入属于GNN,包括图自编码算法,基于无监督训练的图卷积神经网络。图2描述了网络嵌入和GNN的区别。
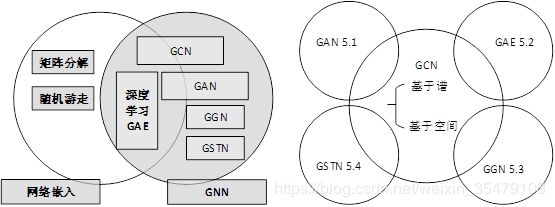
图2 网络嵌入 VS GNN 图3 GNN分类
1.4 文章的创新性
- 新的分类方法
提出新的GNN算法分类,分为五种类型GCN,GAN,GAE,GGN,GSTN。同时文章分析了网络嵌入和GNN的区别,并展示了GNN架构之间的联系。 - 综合性调研
对每种具有代表性的算法进行详细的描述,并进行相应的比较和总结,是目前为止最详细的概述。 - 丰富的资源
提供了丰富的GNN资源,包括最先进的算法,基准数据集,公开源码,实际应用。 - 未来方向
对现有算法的局限性进行了研究,并提出该领域可能的发展方向。
2 基本的图概念的定义
本文中和GNN有关的符号定义如下:
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| | ⋅ \cdot ⋅| | 集合大小 | e i j e_{ij} eij | 边 |
| ⊙ \odot ⊙ | 元素乘 | X ∈ R N × D X\in R^{N\times D} X∈RN×D | 图的特征矩阵 |
| A T A^T AT | 矩阵A的转置 | x ∈ R N x\in R^{N} x∈RN | D=1,特征向量 |
| [ A , B ] [A,B] [A,B] | 矩阵连接 | N N N | 节点的数量 N N N=| V V V| |
| G G G | 图 | M M M | 边的数量 M M M=| E E E| |
| V V V | 图上点的集合 | D D D | 节点向量的维度 |
| v i v_i vi | 点 | T T T | centered |
| N ( v ) N(v) N(v) | 点 v v v的邻居节点 | E E E | 图的边集合 |
图:图 G = ( V , E , A ) G=(V,E,A) G=(V,E,A),其中 V V V节点集合, E E E边集合, A A A邻接矩阵。 v i ∈ V v_i\in V vi∈V描述一个点, e i j = ( v i , v j ) ∈ E e_{ij} = (v_i,v_j)\in E eij=(vi,vj)∈E描述两个节点之间的边, A A A是一个 N × N N\times N N×N的矩阵,其中 A i j = { w i j i f e i j = ( v i , v j ) ∈ E 0 i f e i j ∉ E A_{ij} = \left\{ \begin{aligned} w_{ij} \quad \quad if \quad e_{ij} = (v_i,v_j)\in E\\ 0\quad \quad \quad \quad \quad \quad \quad if \quad e_{ij}\notin E\\ \end{aligned} \right. Aij={wijifeij=(vi,vj)∈E0ifeij∈/E连接一个节点的边是一个节点的度, d e g r e e ( v i ) = ∑ A i degree(v_i) = \sum A_i degree(vi)=∑Ai。
图与节点属性 X X X关联, X ∈ R N × D X\in R^{N\times D} X∈RN×D是一个特征矩阵,且 X i ∈ R D X_i\in R^D Xi∈RD表示节点 v i v_i vi的特征向量。当 D = 1 D=1 D=1时, X ∈ R N X\in R^N X∈RN表示图的特征向量。
有向图:
有向图中所有边都是从一个节点指向另一个节点。对于有向图, A i j ≠ A j i Aij \ne Aji Aij̸=Aji。无向图是所有边都无方向的图。对于无向图, A i j = A j i Aij = Aji Aij=Aji。
时空图:时空图是一种特征矩阵 X X X随时间变化的图, G = ( V , E , A , X ) G=(V,E,A,X) G=(V,E,A,X),其中 X ∈ R T × N × D X\in R^{T\times N \times D} X∈RT×N×D, T T T是时间步长。
3 GNN分类和框架
本节介绍文章对GNN分类的方法,将任何可微分模型(包含了神经结构)作为GNN。将GNN分为五种类型GCN,GAN,GAE,GGN,GSTN。其中GCN在捕获结构依赖性方面起到了重要作用,如图3所示,其他的方法都部分利用了GCN作为构建模型的块。表2总结了每一类方法的代表性方法。
表2 GNN分类的代表性方法
| 分类 | 文献 | |
| GCN | Spectral-based | [12], [14], [20], [21], [22], [23], [43] |
| Spatial-based | [13], [17], [18], [19], [24], [25], [26], [27], [44], [45] [46], [47], [48], [49], [50], [51], [52], [53], [54] | |
| Polling Modeles | [12], [21], [55], [56] | |
| GAT | [15], [28], [57], [58] | |
| GAE | [41], [42], [59], [60], [61], [62], [63] | |
| GGN | [64], [65], [66], [67], [68] | |
| GSTN | [69], [70], [71], [72], [73] |
3.1 GNNs分类
GCNs:GCNs将传统数据的卷积算子泛化到图数据,这个算法的关键是学习一个函数 f f f,能够结合 v i v_i vi邻居节点的特征 X j X_j Xj和其本身特征 X i X_i Xi生成 v i v_i vi的新表示, j ∈ N ( v i ) j\in N(v_i) j∈N(vi)。图4展示了GCNs的节点表示学习。图5展示了一些基于GCN的图神经网络模型。
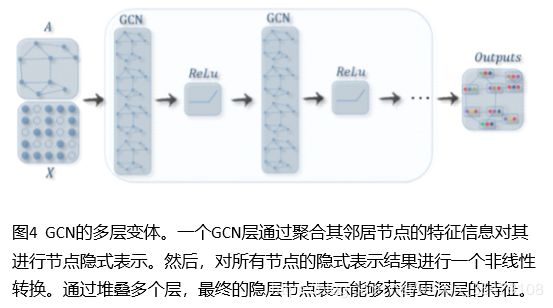
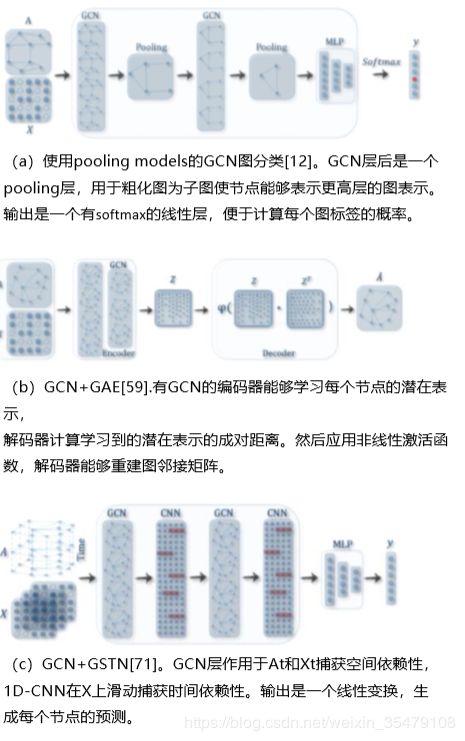
图5 基于GCN构建的不同网络
GAN:GAN与GCN类似,致力于寻找一个聚合函数,融合图中相邻的节点,随机游动和候选模型,学习一种新的表示。关键区别是:GAN使用注意力机制为更重要的节点,步或者模型分配更大的权重,权重个网络一起学习。图6展示了GCN和GAN在聚合邻居节点信息时候的不同。
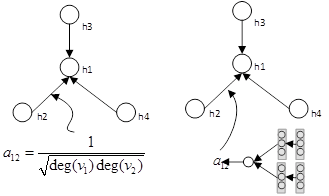
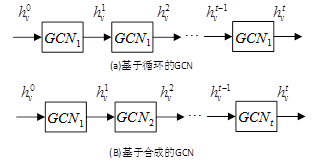
图6 GCN和GAN的不同 图7 基于循环和基于组合的GCN
(GCN边的权重是一个固定的值,GAN是通过端到端的网络结构学习,因此重要的点权重更大)
GAE:GAE是一种无监督学习框架,通过编码器学习一种低维点向量,然后通过解码器重构图数据。GAE是一种常用的学习图嵌入的方法,既适用于无属性信息[41]、[42]的普通图,还适用于是有属性图[61]、[62]。对于普通的图,大多数算法直接预先得到一个邻接矩阵,或者构建一个信息丰富的矩阵,也就是点对互信息矩阵,或者邻接矩阵填充自编码模型,并捕获一阶和二阶信息[42]。对于属性图,图自编码模型利用GCN[14]作为一个构建块用于编码,并且通过链路预测解码器[59],[61]重构结构信息。
GGN:GGN旨在从数据中生成可信的信息,生成给定图经验分布的图从根本上来说是具有挑战性的,主要因为图是复杂的数据结构。为了解决这个问题,研究员探索了将交替形成节点和边作为生成过程的因素,并借助[66],[67]作为训练过程。GGN一个很有前途的应用领域是化合物合成。在化学图中,视原子为节点,化学键为边,任务是发现具有一定化学和物理性质的可合成的新分子。
GSTN:GSTN从时空图中学习不可见的模式,在交通预测和人类活动预测等应用中越来越重要。例如,底层道路交通网络是一个自然图,其中每个关键位置是一个节点,它的交通数据是被连续监测的。通过建立有效的GSTN,能够准确预测整个交通的系统的交通状态[70],[71]。GSTN的核心观点是,同时考虑空间依赖性和时间依赖性。目前很多方法使用GCNs捕获依赖性,同时使用RNN[70],或者CNN[71]建模时间依赖关系。
3.2 框架
GNN,尤其是GCN,通过用谱图理论和空间局部性重新定义图卷积,试图在图数据上重复CNN的成功。使用图结构和节点信息作为输入,GCN的输出能够利用以下的一种机制用于不同的图分析任务:
- Node-level输出用于点回归和分类任务。图卷积模型直接给定节点的潜在表示,然后一个多层感知机或者softmax层用作GCN最后一层。
- Edge-level输出与边分类和链路预测任务相关。为了预测一条边的便签或者连接强度,附加函数从图卷积模型中提取两个节点的潜在表示作为输入。
- Graph-level输出和图分类任务相关,池化模块用于粗话一个图为子图或者对节点表示求和/求平均,以获得图级别上的紧凑表示。
表3列出了主要GCNs方法的输入和输出。特别对每种方法的GCN层和最后一层之间的输出机制进行了总结。输出机制可能涉及几个池化操作,建在后面讨论。
表3 GCN 总结
| 分类 | 方法 | 输入(是否允许边特征) | 输出 | 输出机制 | |
| 中间层 | 最终层 | ||||
| Spectral-based | Spectral CNN(2014)[20] | N | Graph-level | cluster+max_pooling | softmax |
| ChebNet(2016)[12] | N | Graph-level | efficient pooling | mlp +softmax | |
| 1stChebNet (2017) [14] | N | Node-level | activation function | softmax | |
| AGCN (2018) [22] | N | Graph-level | max_pooling | sum pooling | |
| Spatial-based | GNN (2009) [17] | Y | Node-level | ~ | mlp +softmax |
| Graph-level | ~ | add a dummy super node | |||
| GGNNs (2015) [18] | N | Node-level | ~ | mlp /softmax | |
| Graph-level | ~ | sum pooling | |||
| SSE (2018) [19] | N | Node-level | ~ | softmax | |
| MPNN (2017) [13] | Y | Node-level | ~ | softmax | |
| Graph-level | ~ | sum pooling | |||
| GraphSage (2017) [24] | N | Node-level | activation function | softmax | |
| DCNN (2016) [44] | Y | Node-level | activation function | softmax | |
| Graph-level | ~ | mean pooling | |||
| PATCHY-SAN (2016) [26] | Y | Graph-level | ~ | mlp +softmax | |
| LGCN (2018) [27] | N | Node-level | skip connections | mlp +softmax | |
端到端训练框架:GCN可以在端到端学习框架中进行(半)监督或无监督的训练,取决于学习任务和标签信息的可用性。
- node-level 半监督分类。给定一个部分节点被标记而其他节点未标记的网络,GCN可以学习一个鲁棒的模型,有效地识别未标记节点[14]的类标签。为此,可以构建一个端到端的多分类框架,通过叠加几个图形卷积层,紧跟着一个softmax层。
- graph-level 监督分类。给定一个图数据集,图级分类旨在预测整个图[55],[56],[74],[75]的类标签(s),端到端学习框架,通过结合GCN和池化过程[55,56]实现。具体的,通过GCN获得每个图里每个节点固定维数的特征表示,然后,通过池化求图中所有节点的表示向量的和,以得到整个图的表示。最后,加上多层感知机和softmax层,可以构造一个端到端的图分类。图5(a)展示了这样一个过程。
- 无监督图嵌入。图中没有标签数据的时候,可以在端到端的框架中以无监督的方式学习一种图嵌入。这些算法以两种方式利用边级信息。一种简单的:利用自编码框架,编码器利用GCN将图嵌入到潜在的表示中,解码器利用潜在的表示重构图结构[59,61]。另一种方式:利用负采样方法,抽取一部分节点对作为负对,图中剩余的节点对作为正对,之后利用逻辑回归层,形成一个端到端的学习框架[24]。
4 图卷积网络
GCNs分为两类:spectral-based 和spatial-based,Spectral-based方法从图信号处理的角度[76]引入滤波器来定义图卷积,此使图卷积被解释为从图信号中去除噪声。Spatial-based的方法将图卷积表示为来自邻居节点的特征信息的结合。GCNs在节点级作用时,图池化模块可以与GCN交错定义,将图粗话为高水平子结构。如图5(a)所示,这样一个结构设计能够提取图水平的表示并用于图分类任务。
4.1 基于图谱的GCN
基于谱的方法在图信号处理中具有坚实的基础[76]。首先介绍图信号处理的基本知识,然后回顾spectral-based GCNs的代表性成果。
4.1.1 图信号处理
归一化图拉普拉斯矩阵时一个图的一种鲁棒的数据表示,记为: L = I n − D − 1 2 A D − 1 2 L = I_n - D^{-\frac{1}{2}}AD^{-\frac{1}{2}} L=In−D−21AD−21,其中 A A A是图的邻接矩阵, D D D时一个节点度矩阵,记录每个节点的度, D i i = ∑ j ( A i j ) D_{ii} = \sum_j(A_{ij}) Dii=∑j(Aij),归一化拉普拉斯矩阵具有实对称半正定的性质。因此 L L L能够被分解为 L = U Λ U T L = U\Lambda U^T L=UΛUT,其中 U = [ u 0 , u 1 , ⋯ , u n − 1 ] ∈ R N × N U = [u_0,u_1,\cdots,u_{n-1}]\in R^{N\times N} U=[u0,u1,⋯,un−1]∈RN×N是根据特征值排序的特征向量组成的矩阵, Λ \Lambda Λ是特征值的对角矩阵, Λ i i = λ i \Lambda_{ii} = \lambda_i Λii=λi.图拉普拉斯矩阵的特征向量构成一个正交的空间,即 U T U = I U^TU = I UTU=I。在图信号处理中,图信号 x ∈ R N x\in R^N x∈RN是图中第 i i i个节点 x i x_i xi的特征向量,信号 x x x的图傅里叶变换定义为 F ( X ) = U T x F(X) = U^Tx F(X)=UTx,逆傅里叶变换为 F − 1 ( x ^ ) = U x ^ F^{-1}(\widehat{x}) = U\widehat{x} F−1(x )=Ux , x ^ \widehat{x} x 表示图傅里叶变换对信号 x x x的输出。从定义中可以看到,图拉普拉斯确实将图输入信号投影到正交空间,该正交空间的基根据 L L L的特征向量构成。变换后的信号 x ^ \widehat{x} x 的元素表示新空间中图的坐标,因此,输入信号能够被表示为 x = ∑ i x ^ i u i x = \sum_i\widehat{x}_iu_i x=∑ix iui,实际上是图信号的逆傅里叶变换。因此,输入信号 x x x用 g ∈ R N g\in R^N g∈RN滤波的图卷积为: x ∗ G g = F − 1 ( F ( x ) ⊙ F ( g ) ) = U ( U T x ⊙ U T g ) x*Gg = F^{-1}(F(x)\odot F(g))\\ = U(U^Tx\odot U^Tg) x∗Gg=F−1(F(x)⊙F(g))=U(UTx⊙UTg)其中 ⊙ \odot ⊙表示Hadamard乘积,也就是点乘,矩阵的对应元素想乘。如果定义一个滤波器 g θ = d i a g ( U T g ) g_\theta = diag(U^Tg) gθ=diag(UTg),图卷积就简化为 x ∗ G g θ = U g θ U T x x*Gg_\theta = Ug_\theta U^Tx x∗Ggθ=UgθUTx 基于谱的GCN都遵循这个定义,不同的是滤波器 g θ g_\theta gθ的选择不同。
4.1.2 基于谱的GCN方法
谱CNN:Bruna等人,[20]中第一次提出谱卷积神经网络。假设滤波器 g θ = Θ i , j k g_\theta = \Theta_{i,j}^k gθ=Θi,jk是一个可学习参数的集合,并且假设图信号是多维的,图卷积层顶定义为: X : , j k + 1 = σ ( ∑ i = 1 f k − 1 U Θ i , j k U T X : , i k ) ( j = 1 , 2 , ⋯ , f k ) X_{:,j}^{k+1} = \sigma(\sum_{i=1}^{f_{k-1}}U\Theta_{i,j}^kU^TX_{:,i}^{k})\quad \quad \quad (j=1,2,\cdots,f_k) X:,jk+1=σ(i=1∑fk−1UΘi,jkUTX:,ik)(j=1,2,⋯,fk)其中 X k ∈ R N × f k − 1 X^k\in R^{N\times f_{k-1}} Xk∈RN×fk−1是输入图信号, N N N是节点数量, f k − 1 f_{k-1} fk−1是输入通道的数量, f k f_k fk是输出通道的数量, Θ i , j k \Theta_{i,j}^k Θi,jk是一个可学习参数的对角矩阵, σ \sigma σ是一个线性变换。
Chebyshev谱CNN(ChebNet):Defferrard等人[12]中提出ChebNet,定义特征向量对角矩阵的切比雪夫多项式为滤波器,也就是 g θ = ∑ i = 1 K θ i T k ( Λ ~ ) g_\theta = \sum_{i=1}^K\theta_iT_k(\widetilde{\Lambda}) gθ=∑i=1KθiTk(Λ ), Λ ~ = 2 Λ / λ m a x − I N \widetilde{\Lambda} = 2\Lambda/\lambda_{max}-I_N Λ =2Λ/λmax−IN。切比雪夫多项式递归定义为: T k ( x ) = a x T k − 1 ( x ) − T k − 2 ( x ) T_k(x) = axT_{k-1}(x) - T_{k-2}(x) Tk(x)=axTk−1(x)−Tk−2(x),其中 T 0 ( x ) = 1 , T 1 ( x ) = x T_0(x) = 1,T_1(x) = x T0(x)=1,T1(x)=x。信号 x x x的卷积为: x ∗ G g θ = U ( ∑ i = 1 K ) θ i T k ( Λ ~ ) U T x = ∑ i = 1 K θ i T i ( L ~ ) x x*Gg_\theta = U(\sum_{i=1}^K)\theta_iT_k(\widetilde{\Lambda})U^Tx \\ =\sum_{i=1}^{K}\theta_iT_i(\widetilde{L})x x∗Ggθ=U(i=1∑K)θiTk(Λ )UTx=i=1∑KθiTi(L )x其中 L ~ = 2 L / λ m a x − I N \widetilde{L} = 2L/\lambda_{max} - I_N L =2L/λmax−IN。
从上式中,ChebNet避免计算图傅里叶的基,将计算复杂度从 O ( N 3 ) O(N^3) O(N3)将到 O ( K M ) O(KM) O(KM).由于 T i ( L ~ ) T_i(\widetilde{L}) Ti(L )是 L ~ \widetilde{L} L 的 i i i阶多项式,所以 T i ( L ~ ) x T_i(\widetilde{L})x Ti(L )x作用于每个节点的局部,所以ChebNet滤波器在空间是局部化的。
一阶ChebNet(1stChebNet)[效果很好]:Kipf等人,[14]引入了一种一阶近似ChebNet。假设 K = 1 , λ m a x = 2 K=1,\lambda_{max} = 2 K=1,λmax=2,上式简化为: x ∗ G g θ = θ 0 x − θ 1 D − 1 2 A D − 1 2 x x*Gg_\theta = \theta_0x - \theta_1D^{-\frac{1}{2}}AD^{-\frac{1}{2}}x x∗Ggθ=θ0x−θ1D−21AD−21x为了抑制参数数量防止过拟合,1stChebNet假设 θ = θ 0 = − θ 1 \theta = \theta_0 = -\theta_1 θ=θ0=−θ1,图卷积的定义就变为: x ∗ G g θ = θ ( I n + D − 1 2 A D − 1 2 ) x x*Gg_\theta = \theta(I_n+D^{-\frac{1}{2}}AD^{-\frac{1}{2}})x x∗Ggθ=θ(In+D−21AD−21)x为了融合多维图输入信号,1stChebNet对上式进行修正提出了图卷积层: X k + 1 = A ~ X k Θ X^{k+1} = \widetilde{A}X^{k}\Theta Xk+1=A XkΘ其中 A ~ = I N + D − 1 2 A D − 1 2 \widetilde{A} = I_N + D^{-\frac{1}{2}}AD^{-\frac{1}{2}} A =IN+D−21AD−21。
1stChebNet CGN也是空间局部化 的,弥补了谱方法和空间方法的差距。输出的每一行表示一个节点的潜在表示,通过节点自身和邻居节点的加权聚合计算得到,其中权重是 A ~ \widetilde{A} A 的特定行获得。1stChebNet的主要缺点是在批训练时,随着1stChebNet层数的增加,计算消耗成指数增加。最后一层的每一个节点都必须递归的在以前层中扩展他的邻域。Chen et al.[45]假设方程7中重新调整的邻接矩阵 A ~ \widetilde{A} A 来自抽样分布。这样就可以使用蒙特卡洛和方差约减技术加速训练过程。
Chen et al.[46]通过邻域采样和原来的隐藏表示将GCN的感受野缩小到任意小尺度。Huang et al.[54]提出了一种自适应分层抽样方法来加速1stChebNet的训练,其中低层的抽样以高层的抽样为条件(?)。该方法也适用于显式方差约简。
自适应GCN(AGCN):为了探索图拉普拉斯矩阵为指明的隐藏结构,Li等人[22]提出了自适应图卷积网络(AGCN)。AGCN利用所谓的残差图来扩充图,残差图是通过计算节点对的距离来构造的。尽管AGCN能够捕获互补关系信息,但是以 O ( N 2 ) O(N^2) O(N2)的计算量为代价。
4.1.3 总结
谱CNN[20]依赖于拉普拉斯矩阵的特征分解。主要有三个问题:首先,对图的任何扰动都会导致特征基的变化。其次,学习的过滤器依赖于不同领域,这意味着它们不能应用于具有不同结构的图。第三,特征分解需要 O ( N 3 ) O(N^3) O(N3)计算和 O ( N 2 ) O(N^2) O(N2)内存。由ChebNet[12]和1stChebNet[14]定义的过滤器具有空间局部性,学习到的权重可以在图中的不同位置共享。然而,谱方法的一个常见缺点是需要将整个图加载到内存中进行图卷积,这在处理大图时效率不高。
4.2 基于空间的GCN
根据传统CNN在图像上卷积操作了,基于空间的GNN基于一个节点的空间关系定义图卷积算子。将图像看作特殊图形式,每个像素代表一个节点,如图1(a)所示,每个像素与附近的像素直接相连,如果用一个3 × \times × 3窗口取块,每个节点的邻居节点就是其周围的八个像素,将滤波器作用于3 × \times × 3块,则每个通道中心像素的值就是3 × \times × 3块内像素的加权平均值。由于相邻结点有固定的顺序,所以可训练权重能够在不同的局部空间共享。如图1(b)所示,对于一般图结构,中心结点的表示也是根据其邻居结点的聚合结果表示。为了探索结点感受野的深度和宽度,通常叠加多个GCL(图卷积层),根据叠加方法的不同,将基于空间的GCN分成两个类别,基于循环和基于组合的GCNs。基于循环的GCN使用一个相同的GCL个更新隐含表示,基于组合GCN则使用不同的GCL更新隐含表示。图7展示了这种不同。
4.2.1 基于循环的空间GCNs
基于递归的方法的主要思想是递归地更新节点的潜在表示,直到达到稳定的不动点。通过对循环函数[17]施加约束、使用门循环单元架构[18]、异步和随机更新节点潜在表示[19]来实现。
GNNs:GNNs作为最早研究图神经网络的方法,通过递归地个更新结点潜在表示直到收敛来实现。换句话说,从传播的角度来说,每个结点与邻居结点交换信息,直到信息均衡。GNNs的图卷积算子定义为(8),能够处理异构图形: h v t = f ( I v , I c o [ v ] , h n e t − 1 , I n e [ v ] ) h_v^t = f(I_v,I_{co}[v],h_{ne}^{t-1},I_{ne}[v]) hvt=f(Iv,Ico[v],hnet−1,Ine[v]) 其中 I v I_v Iv是结点 v v v的标签属性, I c o [ v ] I_{co}[v] Ico[v]表示结点 v v v相关边的标签属性, h n e t [ v ] h_{ne}^{t}[v] hnet[v]表示结点 v v v的邻居结点在 t t t步的隐含表示, I n e [ v ] I_{ne}[v] Ine[v]表示节点 v v v邻居节点的标签属性。
为了确保收敛,递归函数 f ( ⋅ ) f(\cdot) f(⋅)必须是一个压缩映射,映射后能够缩小两点之间的距离。当 f ( ⋅ ) f(\cdot) f(⋅)为神经网络时,对参数的雅可比矩阵必须加罚项。GNNs采用almeda - pineda算法[77]、[78]对模型进行训练。其核心思想是运行传播过程以达到不动点,然后执行给定收敛解的反向过程。
门控GNN(GGNNs):GGNNs采用门控递归单元(GRU)[79]作为递归函数,将递归减少到固定步数。GGNNs的空间图卷积定义为: h v t = G R U ( h v t − 1 , ∑ u ∈ N ( v ) W h u t ) h_v^t = GRU(h_v^{t-1},\sum_{u\in N(v)}Wh_u^t) hvt=GRU(hvt−1,u∈N(v)∑Whut) 与GNNs不同,GGNNs使用时间反向传播(BPTT)来学习参数,不需要约束参数确保收敛。但是BPTT训练带了时间和内存效率的损失。对于大型图来说,问题尤其严重,因为GGNNs需要在所有节点上多次运行递归函数,需要将所有节点的中间状态存储在内存中。
随机稳态嵌入(SSE):为了提高学习效率,SSE算法[19]以异步方式随机更新节点潜在表示。如算法1所示,SSE递归估计节点潜在表示,并使用随机取样的批数据更新参数。为确保收敛到稳态,SSE的递归函数定义为历史状态和新状态的加权平均: h v t = ( 1 − α ) h v t − 1 + α W 1 σ ( W 2 [ x v , ∑ u ∈ N ( v ) [ h u t − 1 , x u ] ] ) h_v^t = (1-\alpha)h_v^{t-1} + \alpha W_1\sigma(W_2[x_v,\sum_{u\in N(v)}[h_u^{t-1},x_u]]) hvt=(1−α)hvt−1+αW1σ(W2[xv,u∈N(v)∑[hut−1,xu]]) 虽然将邻域信息加起来隐式地考虑了节点的度,但是求和的这种测度是否影响了算法的稳定性仍然值得探究。
算法一 随机不动点迭代学习[19]
- 初始化参数 { h v 0 } v ∈ V \{h_v^0\}_{v\in V} {hv0}v∈V
- for k=1 to K K K do
- for t=1 to T do
- 从节点集合 V V V中取 n n n个样本
- 利用公式 h v t = ( 1 − α ) h v t − 1 + α W 1 σ ( W 2 [ x v , ∑ u ∈ N ( v ) [ h u t − 1 , x u ] ] ) h_v^t = (1-\alpha)h_v^{t-1} + \alpha W_1\sigma(W_2[x_v,\sum_{u\in N(v)}[h_u^{t-1},x_u]]) hvt=(1−α)hvt−1+αW1σ(W2[xv,∑u∈N(v)[hut−1,xu]])更新 n n n个节点的隐层表示
- end
- for p=1 to P do
- 从标记样本集合 V V V中取 m m m个样本
- 根据上面公式反向传播梯度建立正向模型
- end
- end
4.2.2 基于组合的空间GCNs
基于组合的方法通过叠加多个图的卷积层来更新节点的表示。
消息传递神经网络(MPNNs):Gilmer等人将现有的[12]、[14]、[18]、[20]、[53]、[80]、[81]等几个图卷积网络归纳为一个统一的框架,称为消息传递神经网络(MPNNs)。MPNNs由两个阶段组成,消息传递阶段和读出阶段。消息传递阶段实际上是,运行T步基于空间的图卷积,卷积算子由消息函数 M t ( ⋅ ) M_t(\cdot) Mt(⋅)和更新函数 U t ( ⋅ ) U_t(\cdot) Ut(⋅)定义: h v t = U t ( h v t − 1 , ∑ w ∈ N ( v ) M t ( h v t − 1 , h w t − 1 , e v w ) ) h_v^t = U_t(h_v^{t-1},\sum_{w\in N(v)}M_t(h_v^{t-1},h_w^{t-1},e_{vw})) hvt=Ut(hvt−1,w∈N(v)∑Mt(hvt−1,hwt−1,evw)) 读出阶段实际上是一个池操作,根据每个节点隐含表示生成整个图的表示。 y ^ = R ( h v T ∣ v ∈ G ) \widehat{y} = R(h_v^T|v\in G) y =R(hvT∣v∈G) 通过输出函数 R ( ⋅ ) R(\cdot) R(⋅)生成输出 y ^ \widehat{y} y ,可以用于graph-level(图级)任务。通过假设不同形式的 U t ( ⋅ ) U_t(\cdot) Ut(⋅) M t ( ⋅ ) M_t(\cdot) Mt(⋅),作者提出了一些其他的GCN。
GraphSage:GraphSage[24]引入聚合函数的概念定义图形卷积。聚合函数本质上是聚合节点的邻域信息,需要满足对节点顺序的排列保持不变,例如均值函数,求和函数,最大值函数都对节点的顺序没有要求。图的卷积运算定义为: h v t = σ ( W t ⋅ a g g r e g a t e k ( h v t − 1 , ∀ u ∈ N ( v ) ) ) h_v^t = \sigma(W^t\cdot aggregate_k(h_v^{t-1},\forall u \in N(v))) hvt=σ(Wt⋅aggregatek(hvt−1,∀u∈N(v))) GraphSage没有更新所有节点上的状态,而是提出了一种批处理训练算法,提高了大型图的可伸缩性。GraphSage的学习过程分为三个步骤。首先,对一个节点的K-眺邻居节点取样,然后,通过聚合其邻居节的信息表示中心节点的最终状态,最后,利用中心节点的最终状态做预测和误差反向传播。如图8所示k-hop,从中心节点跳几步到达的顶点
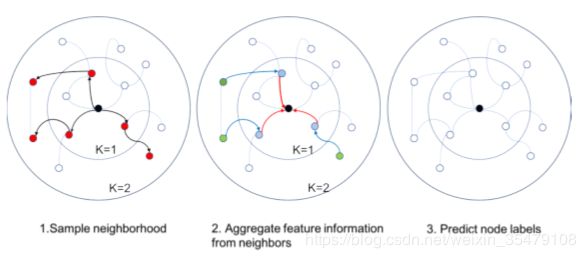
图8 GraphSage [24]的学习过程
假设在第 t t h t^{th} tth-hop取样的邻居个数是 s t s_t st,GraphSage一个batch的 时间复杂度是 O ( ∏ t = 1 T s t ) O(\prod_{t=1}^Ts_t) O(∏t=1Tst).因此随着 t t t的增加计算量呈指数增加,这限制了GraphSage朝深入的框架发展。但是实践中,作者发现 t = 2 t=2 t=2已经能够获得很高的性能。
4.2.3 空间GCNs的其他变体
扩散卷积神经网络(DCNN): DCNN[44]提出了一种封装了图扩散过程的图卷积网络。将输入与转移概率矩阵的幂级数进行独立卷积,得到一个隐藏节点表示。DCNN的扩散卷积运算可以表示为 Z i , j , : m = f ( W j , : ⊙ P i , j , : m X i , : m ) Z_{i,j,:}^m = f(W_{j,:}\odot P_{i,j,:}^mX_{i,:}^m) Zi,j,:m=f(Wj,:⊙Pi,j,:mXi,:m) Z i , j , : m Z_{i,j,:}^m Zi,j,:m表示图 m m m中节点 i i i的 j − h o p j-hop j−hop因隐层表示, P i , j , : m P_{i,j,:}^m Pi,j,:m表示图 m m m的 j − h o p j-hop j−hop转移概率矩阵, X i , : m ) X_{i,:}^m) Xi,:m)是图 m m m中节点 i i i的输入特征。其中 Z m ∈ R N m × H × F Z^m\in R^{N_m\times H\times F} Zm∈RNm×H×F W ∈ R H × F W\in R^{H\times F} W∈RH×F P m ∈ R N m × H × N m P^m \in R^{N_m\times H\times N_m} Pm∈RNm×H×Nm X m ∈ R N m × F X^m \in R^{N_m \times F} Xm∈RNm×F。
尽管通过更高阶的转移矩阵覆盖更大的感受野,DCNN模型需要 O ( N m 2 H ) O(N_m^2H) O(Nm2H)的内存,当用在大图上的时候会引发服务问题。
PATCHY-SAN:PATCHY-SAN[26]使用标准CNN来解决图像分类任务。为此,它将图结构化数据转换为网格结构数据。首先,它使用图标记过程为每个图形选择固定数量的节点。图标记过程本质上是为图中每个节点排序,排序可以根据节点度,中心,WeisfeilerLehman颜色[82],[83]等。然后PATCHY-SAN根据上述图标记结果为每个节点选择和排序固定数量的邻居节点。最后,固定大小的网格数据形成以后,PATCHY-SAN利用标准CNN学习图的隐层表示。GCNs中利用标准CNN能过保持平移不变性,仅依赖于排序函数。因此,节点选择和排序的标准至关重要。PATCHY-SAN中,排序是基于图标记的,但是图标及值考虑了图结构,忽略了节点的特征信息。
大规模图卷积网络(LGCN):LGCN[27]提出了一种基于节点特征信息的排序方法。LGCN使用标准的CNN生成node-level(节点级)输出。对于每个节点,LGCN集成其邻居节点的特征矩阵,并沿着特征矩阵的每一列进行排序,排序后的特征矩阵的前k行作为目标节点的输入网格数据。最后LGCN对合成输入进行1D-CNN得到目标节点的隐藏输入。PATCHY-SAN中得到图标记需要复杂的预处理,但是LGCN不需要,所以更高效。LGCN提出一个子图训练策略以适应于大规模图场景,做法是将采样的小图作为mini-batch。
混合模型网络(MoNet):MoNet[25]用非欧式距离领域的卷积结构统一了标准CNN。因为一些基于空间的方法在整合邻居节点信息的时候忽略了节点与其邻居节点之间的相对位置,所以MoNet引入了伪坐标和权值函数,从而使节点邻居的权重取决于节点和邻居节点的相对位置,也就是伪坐标。在这样一个框架下,从MoNet推广了一些基于流形的方法,可以看作MoNet的特例,如测地线CNN(GCNN)[84],各向异性CNN(ACNN)[85],样条CNN[86],以及对于图形GCN [14], DCNN[44]等。但是这些MoNet框架下的方法都是固定的权重函数,因此MoNet提出了一种具有可学习参数的高斯核函数自由调整权重函数。
4.2.4 总结
基于空间的方法通过聚合邻居的特征信息来定义图卷积。根据图卷积层的不同叠加方式,将空间法分为递归法和合成法两大类。基于递归的方法致力于获得节点的稳定状态,基于组合的方法致力于合并更高阶的邻域信息。训练过程中,两大类的每一层都需要更新所有节点的隐层状态。因为要在内存中保存所有的中间状态,因此效率不高。为了解决这个问题,提出了一些训练方法,包括基于组合的方法中的组图训练,如GraphSage[24],基于递归方法的随机异步训练,如SSE[19]。
4.3 图池模块
将CNN推广到图结构数据的时候,图池化模块也至关重要,对graph-level(图级)分类任务[55], [56], [87]来说尤其重要。Xu等[88]认为在区分图结构方面池辅助的GCN和Weisfeiler-Lehman测试[82]一样强大。与CNN中的池化层一样,GCN的图池化模块也能够对原始特征数据进行下采样,容易降低方差和计算复杂度。由于池窗口中计算均值/最大值/求和的速度很快,因此均值/最大值/求和池是实现此功能最原始、最有效的方法。 h G = m e a n / m a x / s u m ( h 1 T , h 2 T , ⋯ , h n T ) h_G = mean/max/sum(h_1^T,h_2^T,\cdots ,h_n^T) hG=mean/max/sum(h1T,h2T,⋯,hnT) Henaff等人[21]证明在一开始使用简单的max/mean池化对于降低图域的维度非常重要,并且能够缓解图傅里叶变换的巨大复杂度开销。
Defferrard等人在他们的方法ChebNet[12]中优化了最大/最小池化并提出了一种有效的池化策略。首先对输入图进行如图5(a)所示的粗化过程处理,然后将输入图的顶点和粗化后的图进行转换为一个平衡二叉树,在最粗的层次上对节点任意地排序,然后将这个排序传播到平衡二叉树的较低层次,最后会在最细的层次上产生一个规则的排序。对重新排列的1D信号进行池化比对原始信号池化更高效。
Zhang等人提出了一种DGCNN[55]框架,同样对重新排列为有意义顺序的顶点进行池化,与上述池化策略类似,叫SortPooling。不同的是,DCGNN根据节点在图中的结构角色(结构特点)进行分类。将图空间卷积得到的无序节点特征看作连续的WL colors[82],以此进行节点排序。除此之外,还会将图特征向量或截断或扩展到固定图大小k。如果 n > k n>k n>k,则将最后 k − n k-n k−n行删除,反之,如果 n < k n<k n<k,则在最后 k − n k-n k−n行补0.这种方法通过解决一个有挑战性的底层图结构任务,也就是排列不变,增强了图池化,从而提高了GCNs的性能。
最近提出的DIFFPOOL[56]池化模块能够生成图的层次表示,并且在端到端的模式种能够与CNNs和各种GNNs结构结合。DIFFPOOL不像其他粗化方法一样对一个图种的节点进行简单的聚类,而是在一组输入图种提供一种通用的方法对节点进行层次化池化。通过学习 l l l层上的簇分配矩阵 S S S实现, S ( l ) ∈ R n 1 × n 1 + 1 S^{(l)}\in R^{n_1\times n_1+1} S(l)∈Rn1×n1+1。两个包含输入簇节点特征 X ( l ) X^{(l)} X(l)和粗化邻接矩阵 A ( l ) A^{(l)} A(l)的独立的GNN用来生成分配矩阵 S ( l ) S^{(l)} S(l)和嵌入矩阵 Z ( l ) Z^{(l)} Z(l): Z ( l ) = G N N l , e m b e d ( A ( l ) , X ( l ) ) S ( l ) = s o f t m a x ( G N N l , p o o l ( A ( l ) , X ( l ) ) ) Z^{(l)} = GNN_{l,embed}(A^{(l)},X^{(l)})\\S^{(l)} = softmax(GNN_{l,pool}(A^{(l)},X^{(l)})) Z(l)=GNNl,embed(A(l),X(l))S(l)=softmax(GNNl,pool(A(l),X(l))) 任何标准的GNN模型都能够实现上述两个公式,每个GNN模型处理相同的输入数据,但是因为在框架的作用不同,所以有不同的参数。 G N N l , e m b e d GNN_{l,embed} GNNl,embed生成新的嵌入, G N N l , p o o l GNN_{l,pool} GNNl,pool生成输入节点分配到 n l + 1 n_{l+1} nl+1簇的概率。softmax函数对上述第二个公式按行操作,这样, S ( l ) S{(l)} S(l)的每一行为 l l l层的 n l n_l nl节点(或簇), S ( l ) S{(l)} S(l)每一列的对应下一层的一个 n l n_l nl。一旦确定了 Z ( l ) Z{(l)} Z(l) S ( l ) S{(l)} S(l),池化操作定义如下: X ( l + 1 ) = S ( l ) T Z ( l ) ∈ R n l + 1 × d A ( l + 1 ) = S ( l ) T A ( l ) S ( l ) ∈ R n l + 1 × n l + 1 X^{(l+1)} = S^{(l)^T}Z^{(l)}\in R^{n_{l+1}\times d} \\ A^{(l+1)} = S^{(l)^T}A^{(l)}S^{(l)}\in R^{n_{l+1}\times n_{l+1}} X(l+1)=S(l)TZ(l)∈Rnl+1×dA(l+1)=S(l)TA(l)S(l)∈Rnl+1×nl+1 第一个公式根据簇分配矩阵 S ( l ) S^{(l)} S(l)聚合嵌入 Z ( l ) Z^{(l)} Z(l),以计算 n l + 1 n_{l+1} nl+1簇的嵌入。节点表示作为初始簇嵌入。第二个公式,将 A ( l ) A^{(l)} A(l)作为输入,生成粗化邻接矩阵,表示簇之间的连接强度。
总的来说,DIFFPOOL利用两个GNN重新定义了图池化模型对节点进行聚类。所有的GCN模型都能够与DIFFPOOL结合,不仅能够提高性能,而且能够加速卷积过程。
4.4 基于光谱和空间的GCNs的对比
基于光谱的模型作为针对图数据最早期的卷积网络在很多图相关的分析任务种取得了非常好的效果,这种模型最吸引人的地方在于在图信号处理领域奠定了一个理论基础。通过涉及新的图信号滤波器[23],能够理论地涉及新的GCNs。但是,从效率,通用性和灵活性三个方面来说,基于光谱的方法有一些缺点。
效率基于光谱的方法的计算量会随着图的大小急剧增加,因为模型需要同时计算特征向量[20]或者同时处理大图,这就使得模型很难对大图进行并行处理或缩放。基于空间的图方法由于直接对图域的邻居节点进行聚合,所以有潜力处理大图,方法是对一个batch数据计算而不是在整个图上计算。如果邻居节点的数量增加,能够通过采样技术[24,27]提高效率。
通用性基于光谱的图方法假设图是固定的,因此对新的或者不同的图泛化性能很差。基于空间的方法在每个节点上进行局部图卷积,权值可以很容易地在不同地位置和结构之间共享。
灵活性基于谱的模型只适用于无向图,谱方法用于有向图的唯一方法是u将有向图转换为无向图,因为没有有向图的拉普拉斯矩阵明确的定义。基于空间的模型可以将输入合并到聚合函数中(如[13]、[17]、[51]、[52]、[53]),所以在处理多源输入像是边特征边方向上更灵活。
因此,近年来,基于空间的方法更受关注。
5 超GCNs架构
在这一节中,将对其他的图神经网络,包括图注意神经网络、图自动编码器、图生成网络和图时空网络进行回顾。表4总结了每个类别的主要方法。
5.1 图注意力网络
注意力机制成为基于序列的任务的标准[90],其优点是能够集中注意目标最重要的部分,在很多应用,如机器翻译,自然语言理解等都已经证明注意力机制的有效性。由于注意力机制模型容量的增加,图神经网络也因此受益,它可以在聚合过程中使用注意力,集成多个模型的输出,并生成面向重要性的随机游走。本节将讨论如何在图结构数据中使用注意力机制。
5.1.1 GAN方法
图注意网络(GAT): GAT理解
上述关于GT的链接自认比较清楚。图注意网络(GAT)[15]是一种基于空间的图卷积网络,在聚合节点的邻居信息的时候使用注意力机制确定每个邻居节点对中心节点的重要性,也就是权重。定义如下: h i t = σ ( ∑ j ∈ N i α ( h i t − 1 , h j t − 1 ) W t − 1 h j t − 1 ) h_i^t = \sigma(\sum_{j\in N_i}\alpha(h_i^{t-1},h_j^{t-1})W^{t-1}h_j^{t-1}) hit=σ(j∈Ni∑α(hit−1,hjt−1)Wt−1hjt−1) 其中 α ( ⋅ ) \alpha(\cdot) α(⋅)表示注意力函数,能够自动控制邻居节点 j j j对中心节点的 i i i的贡献。为了学习不同子空间的注意力信息,GAT 使用多头注意力方式,并使用 ∥ \| ∥concat方式对不同注意力节点进行整合。 h i t = ∥ k = 1 K σ ( ∑ j ∈ N i α k ( h i t − 1 , h j t − 1 ) W k t − 1 h j t − 1 ) h_i^t = \|_{k=1}^K\sigma(\sum_{j\in N_i}\alpha_k(h_i^{t-1},h_j^{t-1})W_k^{t-1}h_j^{t-1}) hit=∥k=1Kσ(j∈Ni∑αk(hit−1,hjt−1)Wkt−1hjt−1)门控注意网络(GAAN):GAAN也利用多头注意力的方式更新节点的隐层状态。与GAT为各种注意力设置相同的权重进行整合的方式不同,GAAN引入自注意机制对每一个head(头),也就是每一种注意力,计算不同的权重,规则如下: h i t = ϕ o ( x i ⊕ ∥ k = 1 K g i k ∑ j ∈ N i α k ( h i t − 1 , h j t − 1 ) ϕ v ( h j t − 1 ) ) h_i^t = \phi_o(x_i\oplus\|_{k=1}^Kg_i^k\sum_{j\in N_i}\alpha_k(h_i^{t-1},h_j^{t-1})\phi_v(h_j^{t-1})) hit=ϕo(xi⊕∥k=1Kgikj∈Ni∑αk(hit−1,hjt−1)ϕv(hjt−1))其中 ϕ o ( ⋅ ) \phi_o(\cdot) ϕo(⋅), ϕ v ( ⋅ ) \phi_v(\cdot) ϕv(⋅)表示前馈神经网络, g i k g_i^k gik表示第 k k k个注意力头的权重。
图注意模型(GAM):GAM提出一种递归神经网络解决图分类问题,通过自适应访问重要节点序列处理图中信息丰富的部分。定义如下 h t = f h ( f s ( r t − 1 , v t − 1 , g ; θ s ) , h t − 1 ; θ h ) h_t= f_h(f_s(r_{t-1},v_{t-1},g;\theta_s),h_{t-1};\theta_h) ht=fh(fs(rt−1,vt−1,g;θs),ht−1;θh)其中 f h ( ⋅ ) f_h(\cdot) fh(⋅)是一个LSTM网络, f s f_s fs是一个从当前节点 v t − 1 v_{t-1} vt−1到他的一个邻居节点 c t c_t ct的阶跃网络,邻居节点优先考虑策略网络生成的 v t − 1 v_{t-1} vt−1中级别较高的类型 r t = f r ( h t ; θ r ) r_t= f_r(h_t;\theta_r) rt=fr(ht;θr)其中 r t r_t rt是表示节点重要性的随机排序向量,需要以高度优先进一步探讨。 h t h_t ht包含节点从图探索中聚合的历史信息,用来对图标签进行预测。
注意力游走[58]:注意力游走通过随机游走学习节点嵌入。不用于使用固定先验的深度游走(DeepWalk)不同,注意利用游走对可微注意力权重的共生矩阵进行分解: E [ D ] = P ~ ( 0 ) ∑ k = 1 C a k ( P ) k E[D] = \widetilde{P}^{(0)}\sum_{k=1}^Ca_k(P)^k E[D]=P (0)k=1∑Cak(P)k其中 D D D表示共生矩阵, P ~ ( 0 ) \widetilde{P}^{(0)} P (0)表示初始位置矩阵, P P P表示概率转移矩阵。
5.1.2 总括
注意力机制对GNN的贡献分为三个方面,在聚合特征信息的时候对不同的邻居节点分配不同的权值,根据注意力权重集成多个模型,使用注意力权重指导随机游走。尽管将GAT[15]和GAAN[28]归为图的注意网络的范畴,它们也同时是基于空间的GCN。GAT[15]和GAAN[28]的优点是可以自适应学习邻居的重要性权重,如图6所示。但是,由于必须计算每对邻居之间的注意力权重,计算成本和内存消耗迅速增加。
5.2 图自编码
网络嵌入致力于使用神经网络架构将网络顶点在低维向量空间进行表示,图自编码是网络嵌入的一种类型。典型做法是利用多层感知机作为编码器,获得节点嵌入,然后解码器据此重构节点的邻域统计信息,如正点态互信息(positive pointwise mutual information, PPMI)[41]或一阶和二阶近似[42]。近期,研究员探索将GCN[14]作为编码器,设计图自编码器的时候或结合HCN与GAN[91],或结合GAN与LSTM[7]。首先回顾基于GCN的自编码器,然后总结该分类的其他变体。
5.2.1 基于GCN的自编码器
图自编码(GAE):GAE最早将GCN[14]整合到图自编码框架。编码器定义为: Z = G C N ( X , A ) Z=GCN(X,A) Z=GCN(X,A)解码器定义为: A ^ = σ ( Z Z T ) \widehat{A} = \sigma(ZZ^T) A =σ(ZZT)GAE的框架在图5b展示。可以用变分的方式训练GAE,也就是最小化变分下界 L L L: L = E q ( Z ∣ X , A ) [ l o g p ( A ∣ Z ) ] − K L [ q ( Z ∣ X , A ) ∥ p ( Z ) ] L = E_{q(Z|X,A)}[log_p(A|Z)]-KL[q(Z|X,A)\|p(Z)] L=Eq(Z∣X,A)[logp(A∣Z)]−KL[q(Z∣X,A)∥p(Z)]
对抗正则化图自编码器(ARGA)[16]:ARGA利用GANs的训练方案[91]正则化图自编码器。其中,编码器用节点的特征编码其结构信息,也就是GCN中的隐层表示,然后解码器从编码器的输出中重构邻接矩阵。GANs在训练生成模型的时候在生成和判别模型之间进行一个最小-最大博弈。生成器尽可能生成真实的“伪样本”,而判别器则尽可能从真实样本中识别”伪样本“。GAN帮助ARGA正则化节点学习到的隐藏表示遵循先验分布。具体来说,编码器像生成器,尽可能使学习的节点的隐藏表示与真实的先验分布难以区分,解码器,可以看作判别器,尽可能识别所有的隐藏节点表示,无论节点隐藏是从编码器生成的还是从一个真实的先验分布得到的。
5.2.2 图自编码的其他变体
对抗正则化自编码器网络表示(NetRA)[62]:NetRA是与ARGA思想相似的一种图自编码框架,也是通过对抗训练正则化节点隐藏表示遵循一种先验分布。这种方法采用序列-序列结构[92]恢复从随机游走种取样的节点序列,而不是重构邻接矩阵。
**图表示深度神经网络(DNGR)[41]**通过堆叠去噪自编码[93]重构点态互信息矩阵(PPMI)。当图被随机游走序列化后,PPMI矩阵本质上捕获节点的共存信息。形式上,PPMI矩阵定义为: P P M I v 1 , v 2 = m a x ( l o g ( c o u n t ( v 1 , v 2 ) ⋅ ∣ D ∣ c o u n t ( v 1 ) c o u n t ( v 2 ) ) , 0 ) PPMI_{v_1,v_2} = max(log(\frac{count(v_1,v_2)\cdot |D|}{count(v_1)count(v_2)}),0) PPMIv1,v2=max(log(count(v1)count(v2)count(v1,v2)⋅∣D∣),0)其中 ∣ D ∣ = ∑ v 1 , v 2 c o u n t ( v 1 , v 2 ) |D| = \sum_{v_1,v_2}count(v_1,v_2) ∣D∣=∑v1,v2count(v1,v2),且 v 1 , v 2 ∈ V v_1,v_2\in V v1,v2∈V。堆叠的去噪自编码能够学习数据中潜在的高度非线性规律。与传统的神经自编码器不同,它通过将输入项随机切换到零来增加输入的噪声。当存在缺失值时,学习到的隐式表示更具有鲁棒性。
结构深度网络嵌入(SDNE)[42]:SDNE通过堆叠自编码器,同时保留节点的一阶和二阶近似。一阶近似定义为,节点和邻居节点隐含表示之间的距离,一阶近似表示的目标是,尽可能导出邻接节点的表示。具体地,一阶损失函数 L 1 s t L_{1st} L1st定义为: L 1 s t = ∑ i , j = 1 n A i , j ∥ h i ( k ) − h j ( k ) ∥ 2 L_{1st} = \sum_{i,j=1}^{n}A_{i,j}\|h_i^{(k)}-h_j^{(k)}\|^2 L1st=i,j=1∑nAi,j∥hi(k)−hj(k)∥2二阶近似定义为,节点输入和其重构输入之间的距离,其中节点输入是邻接矩阵中节点对应的行。二阶近似的目标是保留一个节点的邻居信息,具体地,二阶近似的损失函数定义为: L 2 n d = ∑ i = 1 n ∥ ( x ^ i − x i ) ⊙ b i ∥ 2 L_{2nd} = \sum_{i=1}^n\|(\widehat{x}_i-x_i)\odot b_i\|^2 L2nd=i=1∑n∥(x i−xi)⊙bi∥2向量 b i b_i bi对非零元素的惩罚多余零元素,因为输入是高度稀疏化的。具体地: b i j = { 1 i f A i , j = 0 β > 0 i f A i , j = 1 b_{ij} = \left\{ \begin{aligned} 1 \quad \quad if \quad A_{i,j}=0\\ \beta>0\quad \quad if \quad A_{i,j}=1\\ \end{aligned} \right. bij={1ifAi,j=0β>0ifAi,j=1总体上,目标函数定义为 L = L 2 n d + α L 1 s t + λ L r e g L = L_{2nd}+\alpha L_{1st}+\lambda L_{reg} L=L2nd+αL1st+λLreg其中 L r e g L_{reg} Lreg是 L 2 L_2 L2正则项。
深度递归网络嵌入 DRNE)[63] 直接重构节点的隐含状态而不是重构整个图的统计信息。DRNE使用聚合函数作为编码器,损失函数为: L = ∑ v ∈ V ∥ h v − a g g r e g a t e ( h u y ∣ u ∈ N ( v ) ) ∥ 2 ( 33 ) L = \sum_{v\in V}\|h_v-aggregate(h_uy|u\in N(v))\|^2\quad\quad (33) L=v∈V∑∥hv−aggregate(huy∣u∈N(v))∥2(33)DRNE的创新之处在于选择LSTRM作为聚合函数,其中邻居序列按照节点度排列。
5.2.3 总结
这些方法都学习节点嵌入,但是DNGR和SDNE只给定拓扑结构,而GAE、ARGA、NetRA和DRNE不仅给定拓扑结构而且给定节点内容特性。图自编码的一个挑战是邻接矩阵的稀疏性,使解码器的正项数远少于负项数。为了解决这个问题,DNGR重构了一个更紧密的矩阵即PPMI矩阵,SDNE对邻接矩阵的零项进行了惩罚,GAE对邻接矩阵中的项进行了加权,NetRA将图线性化为序列。
5.3 图生成网络(GGN)
图生成网络(GGN)的目标是,在给定一组观察到的图的前提下生成图。很多图生成方法是与特定领域相关的,例如,分子图生成,一些方法是对分子图进行字符串表示建模,叫做SMILES[94,95,96,97],自然语言处理,以给定的句子[98,99]为条件生成语义图或者知识图。最近,提出了一些统一的生成方法,一些方法将生成过程看作交替生成节点和边[64,65],其他的方法利用生成对抗训练[66,67]。GGN中的方法或者利用GCN作为构建块,或者使用不同的架构。
5.3.1基于GCN的图生成网络
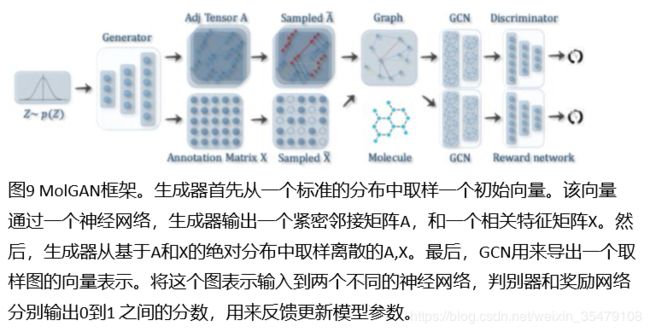
分子生成对抗网络(MolGAN)[66] MolGAN集成了关系GCN[100],增强GAN[101]和强化学习(RL)目标,生成期望属性的图。GAN包含一个生成器和一个判别器,两者相互竞争以提高生成器的准确性。在MolGAN中,生成器尝试生成一个“伪图”包括他的特征矩阵,判别器则要区分伪样本和经验数据。另外,与判别器并行,引入一个奖励网络,根据外部评价器,生成具有一定特性的图。MolGAN框架如图9所示:
图的深度生成模型(DGMG)[65] 利用基于空间的图的GCN来获取现有图的隐藏表示。生成节点和边缘的决策过程取决于生成的图的表示形式。简单地说,DGMG递归地为一个生成图生成节点,直到到达一个停止标准。在加入新节点后的每一步,DGMG重复判断是否在加入的点之间加入边,直到决策变为false。如果决策为true,估计新加入的节点到每个现有节点连接的概率分布,并从概率分布中抽取一个节点作为样本。当新的节点和连接加入到现有图中以后,DGMG再一次更新图表示。
5.3.2 GGN的其他变体
GraphRNN[64] 利用两级循环神经网络开发深度图生成模型。图级RNN每次向节点序列添加一个新的节点,而边级RNN生成二进制序列,表示新加入的节点与序列中之前生成的节点之间的连接。GraphRNN采用广度优先遍历(BFS)策略,将图线性化成节点序列,便于训练图级RNN。GraphRNN采用多变量伯努利分布或者条件伯努利分布建模二进制序列,训练边级RNN。
NetGAN[67] NetGAN将LSTM[7]与Wasserstein GAN[102]结合,从一种基于随机游走的方法生成图形。GAN包含生成器和判别器两个模型,生成器从一个LSTM尽最大可能生成似是而非的随机游走,判别器从正确的随机游走中尽可能区分伪随机游走。训练之后,通过对随机游走集合中节点共生矩阵进行归一化,得到一个新的图。
5.3.3 总结
对生成的图进行评估仍然是一个难题。与人工合成图像或者音频不同,他们能够直接被人类专家评估,生成的图的质量很难直观检测。MolGAN和DGMG利用外部知识来评估生成分子图的有效性。GraphRNN和NetGAN通过图统计信息(如节点度)评估生成的图形。DGMG和GraphRNN依次生成节点和边缘,MolGAN和NetGAN同时生成节点和边缘。根据[68],前一种方法的缺点是当图变大时,对长序列建模是不现实的。后一种方法的挑战是很难控制图的全局属性。最近一种方法[68]采用变分自编码器通过生成邻接矩阵来生成图形,引入惩罚项来解决有效性约束。然而,由于具有 n n n个节点的图的输出空间为 n 2 n^2 n2,这些方法都不能扩展到大型图。
5.4 图时空网络
图时空网络同时捕获时空图的时空依赖性。时空图具有全局图结构,每个节点的输入随时间变化。例如,在交通网络中,将每个传感器作为一个节点,连续记录某条道路的交通速度,其中交通网络的边由传感器对之间的距离决定。图时空网络的目标是预测未来的节点值或标签,或预测时空图标签。最近的研究探索了单独使用GCNs[72],结GCNs与RNN[70]或CNN[71],以及一种为图结构定制的循环架构[73]。下面将介绍这些方法。
5.4.1 基于GCN的图时空网络
扩散卷积递归神经网络(DCRNN)[70] DCRNN引入扩散卷积作为图卷积捕获空间依赖性,用结合门控循环单元(GRU)[79]的序列-序列架构[92]捕获时间依赖性。
扩散卷积对具有前向和后向的截断扩散过程进行建模。形式上,扩散卷积定义为: X : , p ∗ G f ( θ ) = ∑ k = 0 K − 1 ( θ k 1 ( D O − 1 A ) ) k + θ k 2 ( D I − 1 A T ) k ) X : , p X_{:,p*G}f(\theta) = \sum_{k=0}^{K-1}(\theta_{k1}(D_O^{-1}A))^k+\theta_{k2}(D_I^{-1}A^T)^k)X_{:,p} X:,p∗Gf(θ)=k=0∑K−1(θk1(DO−1A))k+θk2(DI−1AT)k)X:,p其中 D O D_O DO是出度矩阵, D I D_I DI是入度矩阵。为了实现多输入输出通道,DCRNN提出了一种扩散卷积层,定义是如下 Z : , q = σ ( ∑ p = 1 P X : , p ∗ G f ( Θ q , p , : , : ) ) Z_{:,q} = \sigma(\sum_{p=1}^PX_{:,p*G}f(\Theta_{q,p,:,:}) ) Z:,q=σ(p=1∑PX:,p∗Gf(Θq,p,:,:))其中, X ∈ R N × Q X\in R^{N\times Q} X∈RN×Q, Z ∈ R N × Q Z\in R^{N\times Q} Z∈RN×Q, Θ ∈ R Q × P × K × 2 \Theta\in R^{Q\times P\times K \times 2} Θ∈RQ×P×K×2, Q Q Q是输出通道数量, P P P是输入通道数量。
为了捕获时间依赖性,DCRNN使用扩散卷积层对GRU的输入进行处理,这样循环单元同时获得上一时刻的历史信息,和图卷积中的邻域信息。DCRNN中改进的GRU叫做扩散卷积门控循环单元(DCGRU): r ( t ) = s i g m o i d ( Θ r ∗ G [ X ( t ) , H ( t − 1 ) ] + b r ) u ( t ) = s i g m o i d ( Θ u ∗ G [ X ( t ) , H ( t − 1 ) ] + b u ) C ( t ) = s i g m o i d ( Θ C ∗ G [ X ( t ) , ( r ( t ) ⊙ H ( t − 1 ) ) + b r ) H ( t ) ] = u ( t ) o d o t H ( t − 1 ) + ( 1 − u ( t ) ) ⊙ C ( t ) r^{(t)} = sigmoid(\Theta_{r*G}[X^{(t)},H^{(t-1)}]+b_r)\\u^{(t)} = sigmoid(\Theta_{u*G}[X^{(t)},H^{(t-1)}]+b_u)\\C^{(t)} = sigmoid(\Theta_{C*G}[X^{(t)},(r^{(t)}\odot H^{(t-1)})+b_r)\\H^{(t)}] = u^{(t)}odot H^{(t-1)}+(1-u^{(t)})\odot C^{(t)} r(t)=sigmoid(Θr∗G[X(t),H(t−1)]+br)u(t)=sigmoid(Θu∗G[X(t),H(t−1)]+bu)C(t)=sigmoid(ΘC∗G[X(t),(r(t)⊙H(t−1))+br)H(t)]=u(t)odotH(t−1)+(1−u(t))⊙C(t)为了满足多步预测的需要,DCGRN采用序列-序列结构[92],其中循环单元由DCGRU代替。
CNN-GCN[71] 1D-CNN与GCN交织学习时空数据。对于一个输入张量 X ∈ R T × N × D X \in R^{T\times N\times D} X∈RT×N×D,1D-CNN层沿时间轴滑过 X [ : , i : ] X_{[:,i:]} X[:,i:]聚合每个节点的时间信息,同时GCN层在每个时间步作用于 X [ i , : , : ] X_{[i,:,:]} X[i,:,:]聚合空间信息。输出层是线性转换,生成每个节点的预测。CNN-GCN框架在图5©中展示。
时空GCN (ST-GCN)[72] ST-GCN将时间流扩展为图边,因此能够使用统一的GCN模型提取时空信息。ST-GCN定义了一个标签函数,根据两个相关节点的距离为图的每条边分配一个标签。这样,邻接矩阵就可以表示为 K K K个邻接矩阵的和,其中 K K K是标签的个数。然后ST-GCN对每个 K K K邻接矩阵使用不同权重的GCN[14],然后求和。 f o u t = ∑ j Λ j − 1 2 A j Λ j − 1 2 f i n W j f_{out} = \sum_j\Lambda_j^{-\frac{1}{2}}A_j\Lambda_j^{-\frac{1}{2}}f_{in}W_j fout=j∑Λj−21AjΛj−21finWj
5.4.2 其他变体
Structural-RNN Jain等[73]提出了一个名为Structural-RNN的递归结构框架,主要目标是在每个时间步骤预测节点标签。Structural-RNN由两种RNN组成,即nodeRNN和edgeRNN。每个节点和边的时间信息分别通过nodeRNN和edgeRNN。由于为不同节点和边假设不同的RNN会显著增加模型复杂度,所以取而代之,将节点和边分割成语义组。例如,一个人-对象交互的图包含两组节点,人节点和对象节点,三组边,人-人边,人-对象边,对象-对象边。统一语义组的节点或者边共享相同的RNN。将edgeRNN的输出作为nodeRNN的输入,以合并空间信息。
5.4.3 总结
DCRNN由于利用了循环网络架构能够处理长时间依赖关系。虽然CNN-GCN比DCRNN简单,但是由于他首先实现了1D-CNN,所以在处理时空图上更加高效。ST-GCN将时间流作为图的边,使邻接矩阵的大小呈二次增长。一方面,增加了图卷积层的计算成本。另一方面,为了捕获长期依赖关系,图卷积层必须多次叠加。Structural-RNN通过在相同的语义组共享相同的RNN提高了模型的有效性。但是,需要人类先验知识来划分语义组。
6 应用
GNN有广泛的应用。首先总结了文献中频繁使用的基准数据集,然后总结了四个常用数据集上的基准性能以及GNN的开源实现,最后,总结了GNN在各个领域的实际应用。
6.1 基准数据集
作者总结了该文章涉及的文献中每个数据集使用的频率,并在表5中展示了至少出现两次的数据集。
| 分类 | 数据集 | 来源 | #图 | #节点 | #边 | #特征 | #标签 | 引文 |
| 引文网络 | Cora | [103] | 1 | 2708 | 5429 | 1433 | 7 | [14], [15], [23], [27], [45] [44], [46], [49], [58], [59],[61], [104] |
| Citeseer | [103] | 1 | 3327 | 4732 | 3703 | 6 | [14], [15], [27], [46], [49] [58], [59], [61 | |
| Pubmed | [103] | 1 | 19717 | 44338 | 500 | 3 | [14], [15], [27], [44], [45] [48], [49], [59], [61], [67] | |
| DBLP | dblp.uni-trier.de [105](aminer.org/citation) | 1 | — | — | — | — | [62], [67], [104], [106] | |
| 社交网络 | BlogCatalog | [107] | 1 | 10312 | 333983 | — | 39 | [42], [48], [62], [108] |
| [24] | 1 | 232965 | 11606919 | 602 | 41 | [24], [28], [45], [46] | ||
| Epinions | www.epinions.com | 1 | — | — | — | — | [50], [106] | |
| 生物化学图 | PPI | [109] | 24 | 56944 | 818716 | 50 | 121 | [15], [19], [24], [27], [28] [46], [48], [62] |
| NCI-1 | [110] | 4100 | — | — | 37 | 2 | [26], [44], [47], [52], [57] | |
| NCI-109 | [110] | 4127 | — | — | 38 | 2 | [26], [44], [52] | |
| MUTAG | [111] | 188 | — | — | 7 | 2 | [26], [44], [52] | |
| D&D | [112] | 1178 | — | — | — | 2 | [26], [47], [52] | |
| QM9 | [113] | 133885 | — | — | — | 13 | [13], [66] | |
| tox21 | tripod.nih.gov/tox21/challenge/ | 12707 | — | — | — | 12 | [22], [53] | |
| 无结构图 | MNIST | yann.lecun.com/exdb/mnist/ | 70000 | — | — | — | 10 | [12], [20], [23], [52] |
| Wikipedia | www.mattmahoney.net/dc/textdata | 1 | 4777 | 184812 | — | 40 | [62], [108] | |
| 20NEWS | [114] | 1 | 18846 | — | — | 20 | [12], [41] | |
| 其他 | METR-LA | [115] | — | — | — | — | — | [28], [70] |
| Movie-Lens1M | [116]grouplens.org/datasets/ | 1 | 10000 | 1 Millinoi | — | — | [23], [108] | |
| Nell | [117] | 1 | 65755 | 266144 | 61278 | 210 | [14], [46], [49] |
引文网络:包括文章,作者及其关系,关系可以是引文,作者,共同作者。尽管引文网络是有向图,但是在评估关于节点分类,链接预测和节点聚类任务的模型性能时,通常被视为无向图。引文网络有三个流行的数据集,Cora,Citeseer和Pubmed。Cora包含2708个机器学习出版物,分为7个类。Citeseer包含3327篇科学论文,分为6个类。Cora,Citeseer中的每一篇论文都由独热向量表示,独热向量表示字典中的单词是否被引用。Pubmed包含19717个与糖尿病相关的出版物,每一篇文章由逆文本频率表示(IF-IDF)。此外,DBLP是一个有数百万篇文章和作者的引文数据集,这些文章和作者都是从计算机科学书目中收集而来。可以在https://dblp.uni-trier.de上找到DBLP的原始数据集。 DBLP引文网络的处理版本由https://aminer.org/citation持续更新。
社交网络 数据根据在线服务如BlogCatalog,Reddit和Epinions等中的用户交互形成。BlogCatalog是一个由博主和他们的社会关系形成的社交网络。博主的标签代表了他们的个人兴趣。Reddit数据集是由Reddit论坛收集的帖子形成的无向图。如果两个如果包含同一个用户的评论,这两个帖子就会形成链接。每个帖子含有一个表示其所属社区的标签。Epinions数据集是从在线产品评论网站收集的多关系图,其中评论者可以具有多种关系类型,例如信任,不信任,共同审查和共同评级。
化学/生物图 化学分子和化合物可以用化学图表示,原子作为节点,化学键作为边缘。此类图通常用于评估图分类性能。 NCI-1和NCI-9数据集分别含有4100和4127种化合物,标记它们是否具有阻碍人癌细胞生长的活性。 MUTAG数据集包含188种硝基化合物,标记为是芳香族还是杂芳香族。 D&D数据集包含1178个蛋白质结构,标记它们是酶还是非酶。 QM9数据集包含133885个分子,标签是13种化学特性。 Tox21数据集包含12707种化合物,分为12种毒性。另一个重要的数据集是蛋白质 - 蛋白质相互作用网络(PPI)。它包含24个生物图,其中节点表示蛋白质,边缘表示蛋白质之间的相互作用。在PPI中,图与人体组织关联,节点标签表示生物状态。
非结构化图 为了测试GNN对非结构化数据的泛化能力,k最近邻图(kNN图)已被广泛使用。 MNIST数据集包含70000张尺寸为28×28的图像,并有十类数字。将MNIST图像转换为图的典型方法是,基于其像素位置构造8-NN图形。Wikipedia数据集是从维基百科转储的前一百万字节中提取的单词共生网络。单词标签代表词性(POS)标签。 20-NewsGroup数据集包含大约20,000个新闻组(NG)文本文档,有20种新闻类型。通过将每个文档表示为节点,并使用节点之间的相似性作为边缘权重来构造20-NewsGroup的图。
其他 还有其他几个值得一提的数据集。 METR-LA是从洛杉矶高速公路收集的交通数据集。来自MovieLens网站的MovieLens-1M数据集,包含由6k用户提供的100万项目评级。它是推荐系统的基准数据集。 NELL数据集是从Never-Ending Language Learning项目获得的知识图。它由涉及两个实体及其关系的三元组组成。
6.2 开源项目
在表5中列出的数据集中,Cora,Pubmed,Citeseer和PPI是最常用的数据集。在测试GCN在节点分类任务上的性能的时候,经常在这些数据集上比较。图6展示了这四个数据集的基准性能,其中所有的数据集使用标准数据分割。开源实现有助于深度学习研究中的基线实验。如果没有公开源代码,由于存在大量超参数,就会很难达到文献中提到的结果。表7展示4-5节种涉及的GNN模型的开源实现。值得注意的是,Fey等人 [86]在PyTorch发布了一个名为PyTorch Geometric 3的几何学习库,它实现了几个图形神经网络,包括ChebNet [12],1stChebNet [14],GraphSage [24],MPNNs [13],GAT [15]和SplineCNN [86] ]。最近发布的深度图库(DGL)4提高了许多GNN的快速实现,通过在流行深度学习平台上,如PyTorch和MXNet等,提供一系列函数实现。
表6 对四个最常用数据集的性能进行基准测试
| 方法 | Cora | Citeseer | Pubmed | PPI |
|---|---|---|---|---|
| 1stChebnet (2016) [14] | 81.5 | 70.3 | 79.0 | - |
| GraphSage (2017) [24] | - | - | - | 61.2 |
| GAT (2017) [15] | 83.0 ± \pm ± 0.7 | 72.5 ± \pm ± 0.7 | 79.0 ± \pm ± 0.3 | 97.3 ± \pm ± 0.2 |
| Cayleynets (2017) [23] | 81.9 ± \pm ± 0.7 | - | - | - |
| StoGCN (2018) [46] | 82.0 ± \pm ± 0.8 | 70.9 ± \pm ± 0.2 | 79.0 ± \pm ± 0.4 | 07.9 ± \pm ± 0.04 |
| DualGCN (2018) [49] | 83.5 | 72.6 | 80.0 | - |
| GAAN (2018) [28] | - | - | - | 98.71 ± \pm ± 0.02 |
| GraphInfoMax (2018) [118] | 82.3 ± \pm ± 0.6 | 71.8 ± \pm ± 0.7 | 76.8 ± \pm ± 0.6 | 63.8 ± \pm ± 0.2 |
| GeniePath (2018) [48] | - | - | 78.5 | 97.9 |
| LGCN (2018) [27] | 83.3 ± \pm ± 0.5 | 73.0 ± \pm ± 0.6 | 79.5 ± \pm ± 0.2 | 77.2 ± \pm ± 0.2 |
| SSE (2018) [19]] | - | - | - | 83.6 |
表7 开源实现
| 模型 | 框架 | GitHub链接 |
|---|---|---|
| ChebNet (2016) [12] | tensorflow | https://github.com/mdeff/cnn_graph |
| 1stChebNet (2017) [14] | tensorflow | https://github.com/tkipf/gcn |
| GGNNs (2015) [18] | lua | https://github.com/yujiali/ggnn |
| SSE (2018) [19] | C | https://github.com/Hanjun-Dai/steady_state_embedding |
| GraphSage (2017) [24] | tensorflow | https://github.com/williamleif/GraphSAGE |
| LGCN (2018) [27] | tensorflow | https://github.com/divelab/lgcn/ |
| SplineCNN (2018) [86] | pytorch | https://github.com/rusty1s/pytorch_geometric |
| GAT (2017) [15] | tensorflow | https://github.com/PetarV-/GAT |
| GAE (2016) [59] | tensorflow | https://github.com/limaosen0/Variational-Graph-Auto-Encoders |
| ARGA (2018) [61] | tensorflow | https://github.com/Ruiqi-Hu/ARGA |
| DNGR (2016) [41] | matlab | https://github.com/ShelsonCao/DNGR |
| SDNE (2016) [42] | python | https://github.com/suanrong/SDNE |
| DRNE (2016) [63] | tensorflow | https://github.com/tadpole/DRNE |
| GraphRNN (2018) [64] | tensorflow | https://github.com/snap-stanford/GraphRNN |
| DCRNN (2018) [70] | tensorflow | https://github.com/liyaguang/DCRNN |
| CNN-GCN (2017) [71] | tensorflow | https://github.com/VeritasYin/STGCN_IJCAI-18 |
| ST-GC(2018)[72] | pytorch | https://github.com/yysijie/st-gcn |
| Structural RNN (2016) [73] | theano | https://github.com/asheshjain399/RNNexp |
6.3 实际应用
GNN在不同的任务和领域中有广泛的应用。尽管每类GNN针对一些通用任务都是具体化的,包括节点分类,节点表示学习,图分类,图生成和时空预测,GNN仍然可以应用于节点聚类,链接预测[119]和图分区[120]。本节主要根据它们所属的一般领域介绍实际应用。
6.3.1计算机视觉
GNN的最大应用领域之一是计算机视觉。研究人员在场景图生成,点云分类和分割,动作识别以及许多其他方向中利用图结构来实现进行了探索。
在场景图生成中,目标之间的语义关系有助于理解视觉场景背后的语义。给定图像,场景图生成模型检测和识别目标并预测目标对之间的语义关系[121],[122],[123]。另一个应用是在给定场景图的情况下生成逼真的图像[124],与上述过程相反。由于自然语言可以被解析为语义图,其中每个单词代表一个对象,因此在给定文本描述的情况下合成图像是一种很有前途。
在点云分类和分割中,点云是由LiDAR扫描记录的一组3D点。该任务的解决方案使LiDAR设备能够看到周围环境,通常对无人驾驶有益。为了识别由点云描绘的物体,[125],[126],[127],将点云转换为k-最近邻图或超点图,并使用GCN来探索拓扑结构。
在动作识别中,识别视频中包含的人体动作有助于从机器方面更好地理解视频内容。一种解决方案是检测视频剪辑中人体关节的位置。由骨架链接的人体关节自然形成图,给定人类关节位置的时间序列,[72],[73]应用时空神经网络来学习人类行为模式。
此外,在计算机视觉中应用GNN的可能方向的数量仍在增长。包括小样本图像分类[128],[129],语义分割[130],[131],视觉推理[132]和问答QA系统[133]。
6.3.2推荐系统
基于图的推荐系统将条目和用户作为节点。通过利用条目和条目,用户和用户,用户和条目以及内容信息之间的关系,基于图形的推荐系统能够提供高质量的推荐。推荐系统的关键是将条目的重要性评分给用户,可以被转换为链接预测问题,目标是预测用户和条目之间缺失的链接。为了解决这个问题,范等人 [9]和Ying等人 [11]提出一个基于GCN的图自编码器。 Monti等人 [10]结合GCN和RNN来学习产生已知评级的基础过程。
6.3.3交通
交通拥堵已成为现代城市的热门社会问题。准确预测交通网络中的交通速度,交通量或道路密度对于路线规划和流量控制至关重要。 [28],[70],[71],[134]采用的是与时空神经网络结合的图方法。模型输入是时空图,节点表示放置在道路上的传感器,边缘表示成对节点的距离高于阈值,并且每个节点包含时间序列作为特征。目标是在一个时间间隔内预测道路的平均速度。另一个有趣的应用是出租车需求预测,能够帮助智能交通系统有效利用资源,有效节约能源。根据历史出租车需求,位置信息,天气数据和事件特征,Yao等人[135]结合LSTM,CNN和由LINE [136]训练的节点嵌入,形成每个位置的联合表示,以预测在一个时间间隔内该位置所需的出租车数量。
6.3.4生物化学
在化学领域,研究人员应用GNN来研究分子的图形结构。在分子图中,节点表示原子,边表示化学键。节点分类,图分类和图生成是分子图的三个主要任务,能够学习分子指纹[53],[80],预测分子特性[13],推断蛋白质界面[137],并合成化学品化合物[65],[66],[138]。
6.3.5其他
初步探索将GNN应用于其他问题,如程序验证[18],程序推理[139],社会影响预测[140],对抗性攻击预防[141],电子健康记录建模[142],[ 143],事件检测[144]和组合优化[145]。
7 未来发展方向
尽管已经证明了GNN在学习图数据方面的能力,但由于图的复杂性,仍然存在挑战。在本节中,我们提供了图神经网络的四个未来方向。
7.1 Go Deep
深度学习的成功在于深层神经架构。例如,在图像分类中,杰出的ResNet [146]的具有152个层。然而,当谈到图时,实验研究表明,随着层数的增加,模型性能急剧下降[147]。根据[147],这是由于图卷积推动了相邻节点的表示更接近,因此理论上,无限次卷积,所有节点的表示将收敛到单个点。这就涉及一个问题,在学习图结构数据的时候,更深的网络是否是一个好的策略。
7.2 Receptive Filed
节点的感受野是指包括中心节点及其邻居的一组节点。节点的邻居数量遵循幂律分布。一些节点可能只有一个邻居,而其他节点可能有多达几千个邻居。虽然[24],[26],[27]采用了采样策略,但如何选择节点的代表性感受野仍有待探索。
7.3 Scalability
大多数GNN不能很好地适应大型图。其主要原因是当堆叠多个GCN时,节点的最终状态涉及其大量邻居的隐藏状态,导致反向传播的高复杂性。虽然有几种方法试图通过快速采样[45],[46]和子图训练[24],[27]来提高模型效率,但它们仍然不具有足够的可扩展性来处理具有大图的深层架构。
7.4 Dynamics and Heterogeneity
大多数当前的图神经网络都采用静态齐次图来处理。一方面,假设图结构是固定的。另一方面,假设图中的节点和边缘来自单个源。然而,在许多情况下,这两个假设是不现实的。在社交网络中,新人可以在任何时间进入网络,并且现有人也可以退出网络。在推荐系统中,产品可以具有不同的类型,其输入可以具有不同的形式,例如文本或图像。因此,应该开发新的方法来处理动态和异构图结构。
8 总括
在本次调查中,我们对GNN进行了全面的概述。 我们提供了一种分类法,将图神经网络分为五类:图卷积网络,图注意网络,图自编码器,图生成网络和图时空网络。 我们对类内或类之间的方法进行全面的回顾,比较和总结。 然后我们介绍了图神经网络的广泛应用。 总结了图神经网络的数据集,开源代码和基准。 最后,我们提出了图形神经网络的四个未来方向。