centos7 搭建neo4j因果集群(k8s)
概述
Neo4j是一个高性能的,NOSQL图形数据库,本身就支持集群部署,今天要搭建的就是neo4j的因果集群,其中分为:
核心节点:core-server,可以对数据进行读写的中心节点,通过选举确定leader,follower.
只读节点:read-replica,只提供数据访问的只读节点,需要连接核心节点,可以非常方便的进行扩展
网上的教程,多都是直接部署在服务器上,或者docker部署,这里我讲一下如何在kubernetes集群中部署neo4j的因果集群。
官方文档参考:https://neo4j.com/docs/operations-manual/current/clustering/setup-new-cluster/
官方docker镜像的github参考:https://github.com/neo4j/docker-neo4j-publish
正文
环境:
centos7
neo4j-3.5.5 企业版
kubernetes v1.12.2
1. neo4j集群配置说明
集群是用的是neo4j的官方镜像,镜像的dockerfile可以参考官方github,neo4j分为企业版和社区版,从3.5版本开始,企业版不再开源,只能做为研究使用,不可商用,但是企业版比社区办的功能要多很多,性能更好,重点是只有企业版支持集群部署。所以,如果公司要用的话,还是要买企业版的license。
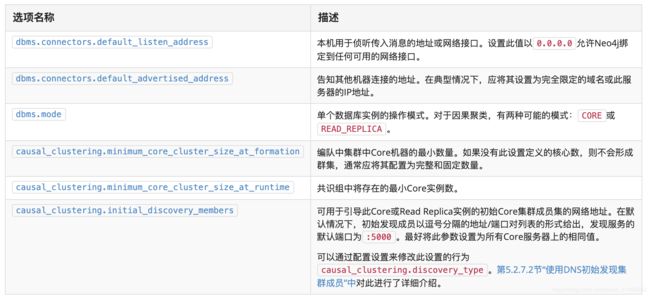
因果集群,首先需要部署core-server集群,官方文档中主要的集群配置如下:
2. 设置nfs动态卷,用于提供neo4j的持久化存储
详细请看:《kubernetes(k8s) 配置nfs动态卷实现StatefulSet的持久化存储》
3. 部署neo4j-core-server集群
因为此集群是有状态的服务,所以使用k8s的StatefulSet进行部署,创建neo4j-core-server.yaml文件,内容如下:
# 先创建namespace,如果在nfs动态卷的时候,已经创建了,就忽略掉
---
apiVersion: v1
kind: Namespace
metadata:
name: neo4j
labels:
name: neo4j
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: neo4j-core
namespace: neo4j
labels:
app: neo4j-core
spec:
replicas: 2 # 部署2个core-server
selector:
matchLabels:
app: neo4j-core
serviceName: neo4j-core
template:
metadata:
labels:
app: neo4j-core
spec:
containers:
- name: neo4j-core
image: neo4j:3.5.5-enterprise # 官方镜像,3.5.5企业版
imagePullPolicy: IfNotPresent
env: # 这里通过env,配置镜像环境参数,这是因为此镜像是通过这样来进行配置参数的
- name: NEO4J_ACCEPT_LICENSE_AGREEMENT # 接受证书协议,必须的
value: "yes"
- name: NEO4J_dbms_connectors_default__advertised__address # 指定自身pod的ip地址,默认为localhost,在集群中必须注明自身地址,这里直接用ip
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NEO4J_dbms_mode # 节点的模式,选择CORE,就是核心节点
value: "CORE"
- name: NEO4J_AUTH # 一定要自定义初始验证的用户名/密码
value: "neo4j/your-password"
- name: NEO4J_causal__clustering_minimum__core__cluster__size__at__formation
value: "2"
- name: NEO4J_causal__clustering_minimum__core__cluster__size__at__runtime
value: "2"
- name: NEO4J_causal__clustering_discovery__type # 默认集群发现方式为LIST,这里写不写都行
value: "LIST"
- name: NEO4J_causal__clustering_initial__discovery__members # 手动写明集群中所有成员的ip:port,5000端口为集群发现端口
value: "neo4j-core-0.neo4j-core.neo4j.svc.cluster.local:5000,neo4j-core-1.neo4j-core.neo4j.svc.cluster.local:5000"
- name: NEO4J_causal__clustering_discovery__advertised__address # 下面这三个必须定义,为节点自身的ip:port,相当于节点自身的名称,因为默认是会用自身hostname,但是在k8s中,无法单单通过hostname解析到ip地址,这样定义的自身地址会无法识别
value: $(NEO4J_dbms_connectors_default__advertised__address):5000
- name: NEO4J_causalClustering_transactionAdvertisedAddress
value: $(NEO4J_dbms_connectors_default__advertised__address):6000
- name: NEO4J_causalClustering_raftAdvertisedAddress
value: $(NEO4J_dbms_connectors_default__advertised__address):7000
volumeMounts:
- name: neo4j-core # 挂载数据目录/data
mountPath: /data
volumeClaimTemplates:
- metadata:
name: neo4j-core # 这里name要和上面volumeMounts的name一致,才能绑定到对应的pod
annotations:
volume.beta.kubernetes.io/storage-class: "managed-nfs-storage" # 这里是上一步创建的nfs动态卷name
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 2Gi # 大小自定义
---
apiVersion: v1
kind: Service
metadata:
name: neo4j-core
namespace: neo4j
spec:
selector:
app: neo4j-core
type: NodePort # 这里用nodeport来开启外网访问,没用traefik是因为7687的连接端口不是http访问,需要4层负载,但是traefik不支持,所以只能通过nodeport来实现外网访问,才能正常访问7474端口的web管理界面。
ports:
- protocol: TCP
name: http
port: 7474
nodePort: 27474
targetPort: 7474
- protocol: TCP
name: blot
port: 7687
nodePort: 27687
targetPort: 7687执行此yaml文件:
kubectl create -f neo4j-core-server.yaml说明:
1. 以上yaml文件中的注释要看清楚,因为因果集群的核心节点是采用的选举方式来确定主节点的,所以最好是单数节点,我这里只部署了2个节点,只是因为资源不太够,测试而已,生产使用的话,最少3节点。
2. 在这里,我用的默认的list的集群发现方式,有一点不好,就是如果增加节点,需要自己手动写上所有集群节点到列表中,且增加核心节点的时候,会比较麻烦。
官方有三种发现方式,分别为LIST,DNS,K8S。先说DNS,DNS的发现方式,可以通过在Service中,使用clusterIP:None 来取消负载的ip,然后在NEO4J_causal__clustering_initial__discovery__members中设置为neo4j-core-0.neo4j-core.neo4j.svc.cluster.local:5000,然后通过k8s集群中的dns服务,来解析到此Service中所有的ip。这样配置非常方便,还不需要修改,我之所以没用,是因为Service中,如果用了clusterIP:None 则没发使用nodeport来暴露7687的tcp端口给k8s外部网络使用,除非traefik可以实现tcp的4层负载,或者不是使用的traefik,二是nginx的Ingress,实现4层负载即可。为什么没用K8S的发现方式呢,我尝试过,但是由于文档没有示例的配置参考,不管怎么样设置,都还是无法正常启动,所以就没法用,如果后面发现了配置方法,再补充给大家
3. 数据持久化存储,我这里用的nfs动态卷,详细的配置和部署方式直接查看上面我给的链接就行了。
4. 其中一定要自定义初始化的用户密码,因为neo4j的每个节点的用户验证系统是独立的!独立的!独立的!也就是说,你在leader节点上新增用户或修改密码,是不会同步到follower节点上的。所以,为了不至于当leader节点挂掉后,新的leader节点密码不同导致出错,所以,部署时最好统一用户密码,当然只读节点也是。
执行后,查看pod的日志,如下则为正常启动:
4. 部署只读节点read-replica
core核心节点部署完成后,则可以进行只读节点的部署,只读节点比核心节点则简单很多,创建neo4j-read-replica.yaml 文件,内容如下:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: neorj-read-replica
namespace: neo4j
labels:
app: neorj-read-replica
spec:
replicas: 3
selector:
matchLabels:
app: neorj-read-replica
template:
metadata:
labels:
app: neorj-read-replica
spec:
containers:
- name: neorj-read-replica
image: neo4j:3.5.5-enterprise
imagePullPolicy: IfNotPresent
env:
- name: NEO4J_ACCEPT_LICENSE_AGREEMENT
value: "yes"
- name: NEO4J_dbms_connectors_default__advertised__address
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NEO4J_dbms_mode # 指定模式为只读节点模式
value: "READ_REPLICA"
- name: NEO4J_AUTH
value: "neo4j/your-password" # 统一设置用户密码
- name: NEO4J_causal__clustering_discovery__type
value: "LIST"
- name: NEO4J_causal__clustering_initial__discovery__members
value: "neo4j-core-0.neo4j-core.neo4j.svc.cluster.local:5000,neo4j-core-1.neo4j-core.neo4j.svc.cluster.local:5000"
---
apiVersion: v1
kind: Service
metadata:
name: neorj-read-replica
namespace: neo4j
spec:
selector:
app: neorj-read-replica
ports:
- protocol: TCP
port: 7687
targetPort: 7687
执行此yaml文件,创建只读节点:
kubectl create -f neo4j-read-replica.yaml说明:
部署3个只读节点,无状态服务,不需要进行数据持久化,只需要将core节点的集群列表写出就行了,会自动去找到核心节点的集群,然后从中复制数据,提供访问即可。因为只读节点只能访问数据,所以没必要提供k8s的外部访问,所以直接在service中负载一下bolt的访问端口就行了,以提供给k8s内部应用访问即可。
查看日志如下为正常启动:
5. 访问web界面
部署完成后,设置域名,设置nginx,访问web界面:
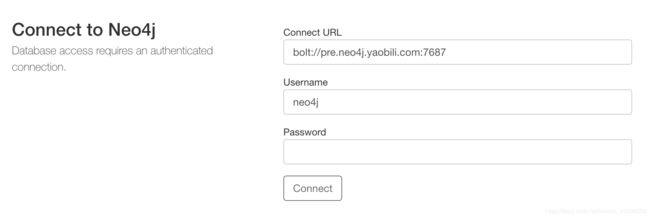 默认用户密码为: neo4j / neo4j
默认用户密码为: neo4j / neo4j
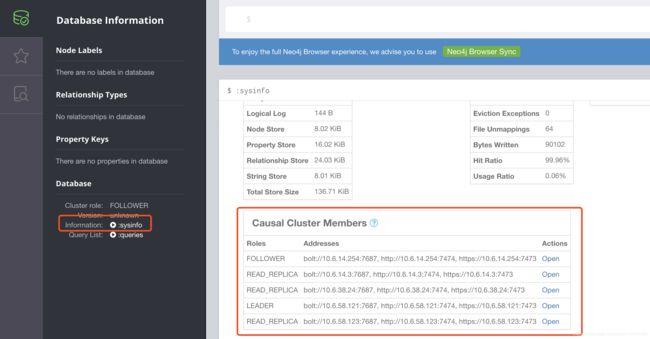
登录修改密码,然后查看状态,可以看到集群的状态:
结束
ok,到此,neo4j在k8s中的因果集群搭建就完成了,其中还有很多的不足,发现方式也不是最优解,后面再进行优化。如果有更好的方法,欢迎交流