python正则表达式知识汇总
正则表达式
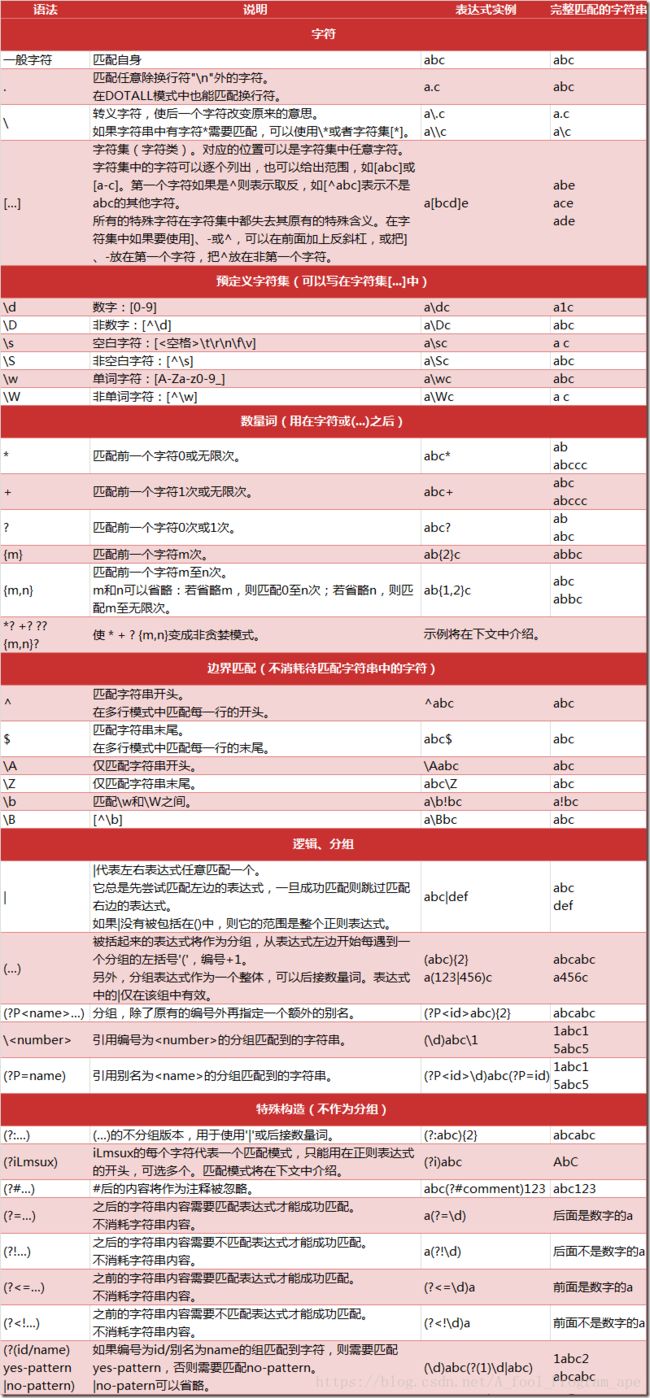
常用的一些字符串匹配规则
1. \d:用于匹配一个数字
2. \w:用于匹配一个数字或者字母
3. .:用于匹配前面字符后面跟着任意一个字符。如:a.:ab,ac,al,af,ag
4. *:用于匹配前面一个字符0个或者多个 a*:匹配0次,或者aa,aaa,aaaa,aaaaa
5. ?:用于匹配前面字符0个或者1个。a?:匹配0次,aa
6. +:用于匹配前面字符1个或者多个,不能为零个。例如a+:匹配a,aaa,aaaa
7. ^:匹配以某某字符开头的字符,^b:匹配以b开头的字符
8. $:匹配以某某字符结尾的字符,c$:以c结尾的字符
9. .+:匹配任意字符至少出现一次
10. .*:贪婪匹配模式:尽可能的匹配符合条件的最大值
11. .*?:非贪婪匹配模式:在能匹配字符的前提下, 尽可能少的匹配字符
##########################################################
re.match():这个函数是从字符串起始位置开始匹配,匹配成功则返回match对象
re.search():这个函数从目标字符串的任意位置开始匹配,如果匹配成功多个数据,但依然只返回一个
re.findall():搜索整个目标字符串,但是符合条件的字符都会被匹配出来
re.split():以搜索到的字符为分隔符,分割整个字符串
re.sub():使用一个字符替换目标字符串的字符