人脸检测(十四)--MTCNN
本文来自于中国科学院深圳先进技术研究院,目前发表在arXiv上,是2016年4月份的文章,算是比较新的文章。红色表示我在复现测试时的重要点。
论文地址:
https://kpzhang93.github.io/MTCNN_face_detection_alignment/
概述
相比于R-CNN系列通用检测方法,本文更加针对人脸检测这一专门的任务,速度和精度都有足够的提升。R-CNN,Fast R-CNN,FasterR-CNN这一系列的方法不是一篇博客能讲清楚的,有兴趣可以找相关论文阅读。类似于TCDCN,本文提出了一种Multi-task的人脸检测框架,将人脸检测和人脸特征点检测同时进行。论文使用3个CNN级联的方式,和Viola-Jones类似,实现了coarse-to-fine的算法结构。
框架
算法流程
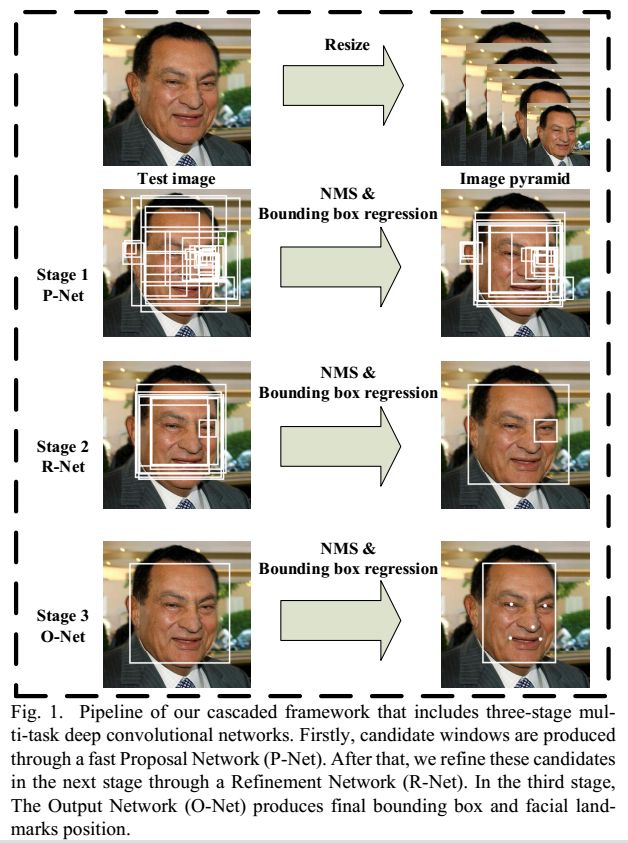
当给定一张测试图片的时候,将其缩放到不同尺度形成图像金字塔,以达到多尺度检测目的。然后,不同尺度的resized图像,传入算法框架:
Stage 1:使用P-Net是一个全卷积网络,用来生成候选窗和边框回归向量(bounding box regression vectors)。使用Bounding box regression的方法来校正这些候选窗,使用非极大值抑制(NMS)合并重叠的候选框。这个网络比较浅,主要基于提供候选窗(有点类似RPN网络),又不消耗时间的角度。注意pnet是全图计算,得到的featureMap上每个点对应金字塔图上12*12的大小
Stage 2:使用N-Net改善候选窗。将通过P-Net的候选窗输入R-Net中,拒绝掉大部分非脸的窗口,继续使用Bounding box regression和NMS合并。
Stage 3:最后使用O-Net输出最终的人脸框和特征点位置。和第二步类似,但是不同的是多了生成5个特征点位置。
CNN结构
本文使用三个CNN,结构如图:
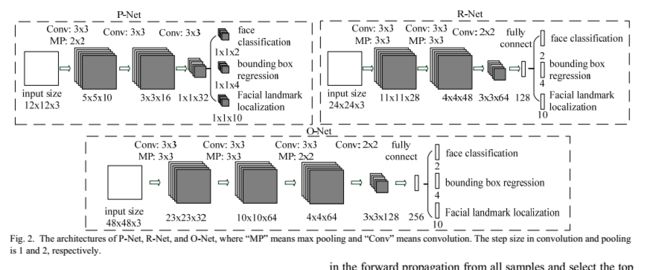
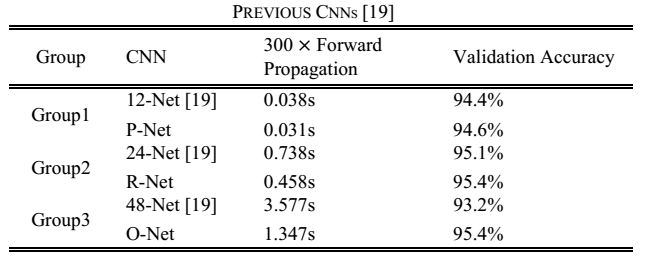
这个CNN模型,是作者基于15年级联CNN人脸检测模型架构改进的,更小的卷积核,更深的网络层。相比原始级联CNN模型能力对比如下:
训练
这个算法需要实现三个任务的学习:人脸非人脸的分类,bounding box regression和人脸特征点定位。
(1)人脸检测
这就是一个分类任务,使用交叉熵损失函数即可:
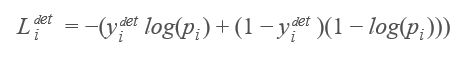
(2)Bounding box regression
这是一个回归问题,使用平方和损失函数:

(3)人脸特征点定位
这也是一个回归问题,目标是5个特征点与标定好的数据的平方和损失:
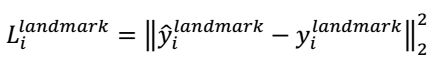
(4)多任务训练
不是每个sample都要使用这三种损失函数的,比如对于背景只需要计算Ldeti,不需要计算别的损失,这样就需要引入一个指示值指示样本是否需要计算某一项损失。最终的训练目标函数是:
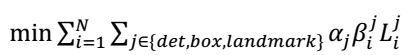
N是训练样本的数量。αj表示任务的重要性。在P-Net和R-Net中,αdet=1,αbox=0.5, αlandmark = 0.5,在O-Net中αdet=1,αbox = 0.5,αlandmark = 1(实际,PNet,RNet,没有用到landmark参与训练)
(5)online hard sample mining
传统的难例处理方法是检测过一次以后,手动检测哪些困难的样本无法被分类,本文采用online hard sample mining的方法。具体就是在每个mini-batch中,取loss最大的70%进行反向传播,忽略那些简单的样本。
训练数据整理
Wider_face包含人脸边框标注数据,大概人脸在20万,CelebA包含边框标注数据和5个点的关键点信息.对于三个网络,提取过程类似,但是图像尺寸不同.
正负样本,部分样本提取:
1.从Wider_face随机选出边框,然后和标注数据计算IOU,如果大于0.65,则为正样本,大于0.4小于0.65为部分样本,小于0.3为负样本,由于不同标注风格导致脸部差异,因此0.3~0.4的数据丢弃.最终样本比例控制在:Neg:Pos:Par:Lan = 3:1:1:2(每个batchsize中)
2.计算边框偏移.对于边框,(x1,y1)为左上角坐标,(x2,y2)为右下角坐标,新剪裁的边框坐标为(xn1,yn1),(xn2,yn2),width,height.则offset_x1 = (x1 - xn1)/width,同上,计算另三个点的坐标偏移.
3.对于正样本,部分样本均有边框信息,而对于负样本不需要边框信息
关键点样本提取
1.从celeba中提取,可以根据标注的边框,在满足正样本的要求下,随机裁剪出图片,然后调整关键点的坐标.
loss修改
由于训练过程中需要同时计算3个loss,但是对于不同的任务,每个任务需要的loss不同.
所有在整理数据中,对于每个图片进行了15个label的标注信息
1.第1列:为正负样本标志,1正样本,0负样本,2部分样本,3关键点信息
2.第2-5列:为边框偏移,为float类型,对于无边框信息的数据,全部置为-1
3.第6-15列:为关键点偏移,为floagt类型,对于无边框信息的数据,全部置为-1
修改softmax_loss_layer.cpp 增加判断,只对于1,0计算loss值
修改euclidean_loss_layer.cpp 增加判断,对于置为-1的不进行loss计算
困难样本选择
论文中作者对与人脸分类任务,采用了在线困难样本选择,实现过程如下:
修改softmax_loss_layer.cpp,根据计算出的loss值,进行排序,只对于70%的值较低的数据,进行反向传播.
测试结果
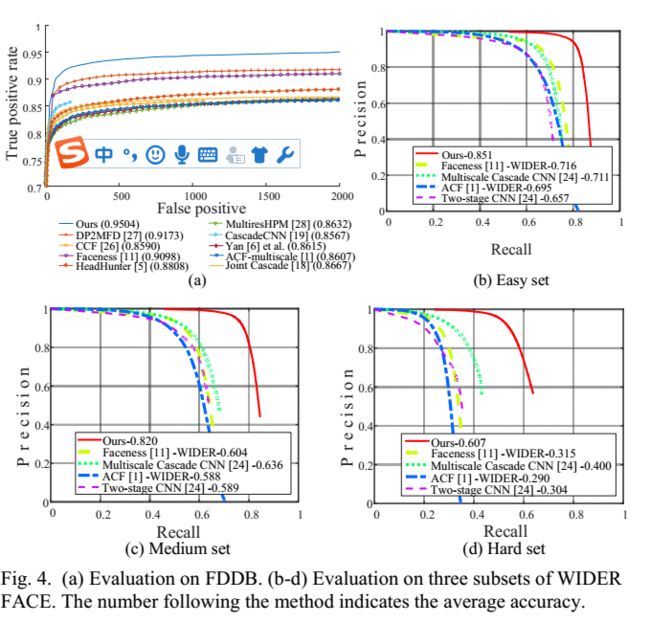
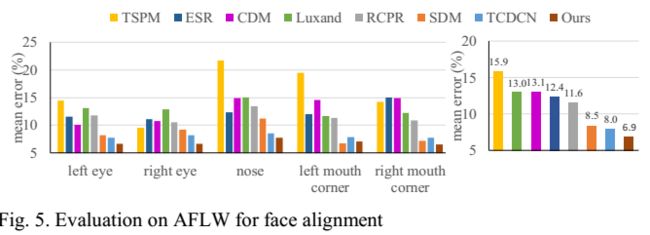

总结
本文使用一种级联的结构进行人脸检测和特征点检测,该方法速度快效果好,可以考虑在移动设备上使用。这种方法也是一种由粗到细的方法,和Viola-Jones的级联AdaBoost思路相似。类似于Viola-Jones:1、如何选择待检测区域:图像金字塔+P-Net;2、如何提取目标特征:CNN;3、如何判断是不是指定目标:级联判断。