Java编程入门笔记(十一)
海纳百川——对象数组和集合
对象数组
数组
在Java提供的存储及随机访问对象序列的各种方法中,数组是效率最高的一种
- 类型检查
- 边界检查
优点
- 数组知道其元素的类型
- 编译时的类型检查
- 大小已知
代价
- 数组对象的大小是固定的,在生存期内大小不可变
对象数组
- 数组元素是类的对象
- 所有元素具有相同的类型
- 每个元素都是一个对象的引用
静态初始化:在声明和定义数组的同时对数组元素进行初始化,例如:
BankAccount[] accounts = {
new BankAccount(“Zhang", 100.00),
new BankAccount(“Li", 2380.00),
new BankAccount(“Wang", 500.00),
new BankAccount(“Liu", 175.56),
new BankAccount(“Ma", 924.02)};
动态初始化:使用运算符new,需要经过两步:
首先给数组分配空间
type arrayName[ ]=new type[arraySize];
然后给每一个数组元素分配空间
arrayName[0]=new type(paramList);
…
arrayName[arraySize-1]=new type(paramList);
Java集合框架
- 程序员不需要关心你的数组到底该申请多少个元素,框架会自动帮你分配空间
- 程序员可以通过一个键,快速得到这个键所对应的值,并且不需要顾虑插入和删除元素的问题
- 程序员可以方便地对数据进行排序、遍历等
- 程序员可以直接使用各种数据结构
Java集合框架提供了一套性能优良、使用方便的接口和类,它们位于java.util包中
遍历等多种算法实现
Collection 接口存储一组不唯一,无序的对象
List 接口存储一组不唯一,有序(插入顺序)的对象
Set 接口存储一组唯一,无序的对象
Map接口存储一组键值对象,提供key(唯一)到value的映射
List类集合
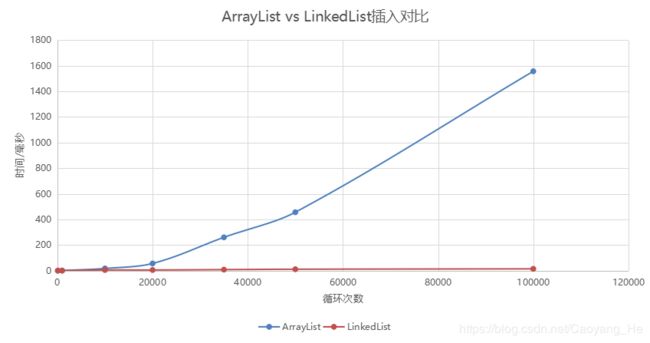
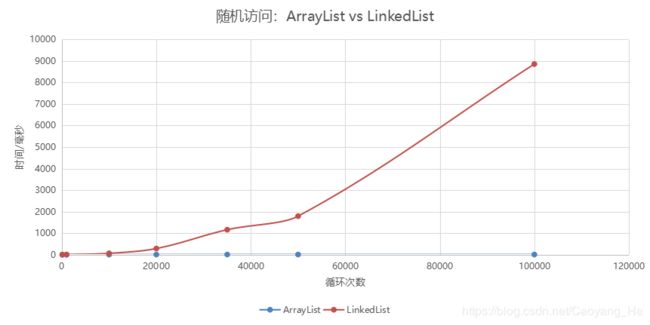
ArrayList实现了长度可变的数组,在内存中分配连续的空间。遍历元素和随机访问元素的效率比较高
LinkedList采用链表存储方式(离散空间)。插入、删除元素时效率比较高
List接口常用方法小结
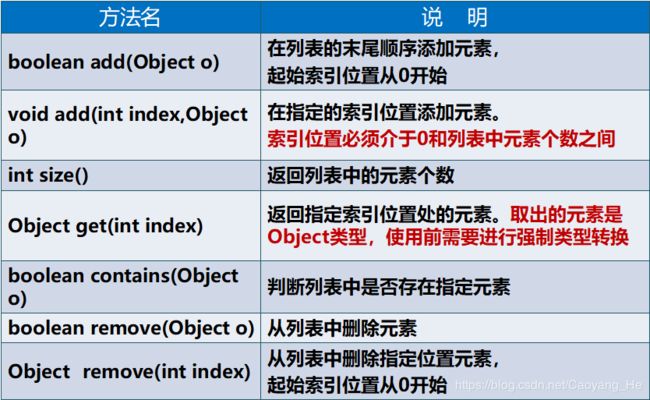
LinkedList的特殊方法
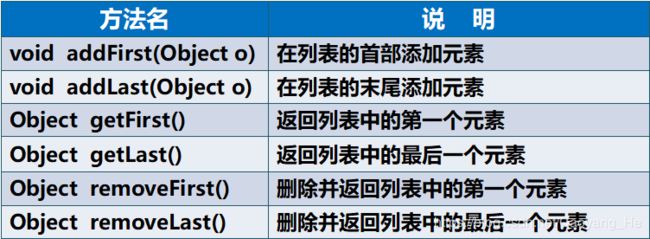
插入元素对比
随机访问对比
Vector类
-
另外一个常用的列表类是Vector类,它也实现了List接口,可以实现ArrayList的所有操作。
-
Vector和ArrayList的异同
- 实现原理、功能相同,可以互用
- 主要区别
Vector线程安全操作相对较慢
ArrayList重速度轻安全,线程非安全
长度需增长时,Vector默认增长一倍,ArrayList增长50%
Vector可以使用capacity()方法获取实际的空间
ArrayList和Vector的默认初始大小均为10
Set类集合
如果确定元素在列表中不能重复,那么可以使用Set
Set无法随机访问,要访问其元素,只能使用迭代器遍历
Set支持的操作
- boolean add(E e);
- void clear();
- boolean contains(Object o);
- boolean isEmpty();
- boolean remove(Object o);
- int size();
HashSet:保证在Set中的元素唯一,但是不保证元素的顺序恒久不变(加入新元素后,元素的遍历顺序可能发生改变)。
TreeSet:保证Set中的元素唯一,并且对元素按其自然顺序进行排序。
-
TreeSet特有的操作:
- E first();
- E last();
- E ceiling(E e);
- E floor(E e);
- E lower(E e);
- E higher(E e);
- void poolFirst();
- void poolLast();
对比
| HashSet | TreeSet |
|---|---|
| 保证元素唯一 | 保证元素唯一 |
| 元素在集合中的顺序不定(并且和放入顺序无关) | 保证元素排序 |
| 使用equals()方法和hashCode()方法来保证元素唯一性 | 通过对元素比较判断其结果是否为0来保证元素唯一性 元素可以实现Comparable接口 也可以使用Comparator来比较元素 |
| 低层数据结构:哈希链表 | 低层数据结构:二叉树 |
算法
Java中的算法都封装在类Arrays和Collections中
排序(Sorting)
使用Arrays.sort()方法可以对数组进行排序
使用Collections.sort()方法可以对集合进行排序
排序算法:
- 当处理原始数据类型时,算法为快速排序
- 当处理对象类型时,算法为归并排序
乱序(Shuffling)
乱序就是做和排序相反的工作,将数据随机地打乱顺序。
生活中的乱序:洗牌。
常规数据处理算法
reverse:将一个List中的元素反向排列
fill:用指定的值覆写List中的每一个元素,这个操作在重新初始化List时有用
copy::接受两个参数,目标List和源List,将源中的元素复制到目标,覆写其中的内容。目标List必须至少与源一样长,如果更长,则多余的部分内容不受影响
查找算法binarySearch
使用二分法在一个有序的List中查找指定元素
有两种形式
- 第一种形式假定List是按照自然顺序升序排列的
- 第二种形式需要增加一个Comparator对象,表示比较规则,并假定List是按照这种规则排序的。
寻找最值——用于任何集合对象
min和max算法返回指定集合中的最小值和最大值
这两个算法分别都有两种形式
简单形式按照元素的自然顺序返回最值
另一种形式需要附加一个Comparator对象作为参数,并按照Comparator对象指定的比较规则返回最值
Map类集合
Map接口专门处理键值映射数据的存储,可以根据键实现对值的操作
最常用的实现类是HashMap
例子
Map countries = new HashMap();
countries.put("CN", "中华人民共和国");
countries.put("RU", "俄罗斯联邦");
countries.put("FR", "法兰西共和国");
countries.put("US", "美利坚合众国");
//使用HashMap存储多组键值对
String country = (String) countries.get("CN");
//获取指定元素的值
System.out.println("Map中共有"+countries.size() +"组数据");
//获取Map元素个数
countries.remove("FR");
System.out.println("Map中包含FR的key吗?" + countries.containsKey("FR"));
//删除指定元素,判断是否包含指定元素
System.out.println( countries.keySet() ) ;
System.out.println( countries.values() );
System.out.println( countries );
//显示键集、值集和键值对集
Map接口常用方法
查询方法
| 方法名 | 说明 |
|---|---|
| int size() | 返回Map中的元素个数 |
| boolean isEmpty() | 返回Map中是否包含元素,如不包括任何元素,则返回true |
| boolean containsKey(Object key) | 判断给定的参数是否是Map中的一个关键字(key) |
| boolean containsValue(Object val) | 判断给定的参数是否是Map中的一个值(value) |
| Object get(Object key) | 返回Map中与给定关键字相关联的值(value) |
| Collection values() | 返回包含Map中所有值(value)的Collection对象 |
| Set keySet() | 返回包含Map中所有关键字(key)的Set对象 |
| Set entrySet() | 返回包含Map中所有项的Set对象 |
修改方法
| 方法名 | 说明 |
|---|---|
| Object put(Object key, Object val) | 将给定的关键字(key)/值(value)对加入到Map对象中。其中关键字(key)必须唯一,否则,新加入的值会取代Map对象中已有的值 |
| void putAll(Map m) | 将给定的参数Map中的所有项加入到接收者Map对象中 |
| Object remove(Object key) | 将关键字为给定参数的项从Map对象中删除 |
| void clear() | 从Map对象中删除所有的项 |
哈希表
也称为散列表,是用来存储群体对象的集合类结构,其两个常用的类是HashTable及HashMap
哈希表相关的一些主要概念
| 名词 | 说明 |
|---|---|
| 容量(capacity) | 哈希表的容量不是固定的,随对象的加入,其容量可以自动扩充 |
| 关键字/键(key) | 每个存储的对象都需要有一个关键字key,key可以是对象本身,也可以是对象的一部分(如对象的某一个属性) |
| 哈希码(hash code) | 要将对象存储到HashTable,就需要将其关键字key映射到一个整型数据,称为key的哈希码(hash code) |
| 哈希函数(hash function) | 返回对象的哈希码 |
| 项(item) | 哈希表中的每一项都有两个域:关键字域key及值域value(即存储的对象)。key及value都可以是任意的Object类型的对象,但不能为空(null),HashTable中的所有关键字都是唯一的 |
| 装填因子(load factor) | (表中填入的项数)/(表的容量) |
构造方法
- Hashtable( ); // 初始容量为101,最大装填因子为0.75
- Hashtable(int capacity);
- Hashtable(int capacity, float maxLoadFactor);
哈希表常用函数
| 方法名 | 说明 |
|---|---|
| Object put(Object key, Object value) | 值value以key为其关键字加入到哈希表中,如果此关键字在表中不存在,则返回null,否则表中存储的value |
| Object get(Object key) | 返回关键字为key的值value,如果不存在,则返回null。 |
| Object remove(Object key) | 将键/值对从表中去除,并返回从表中去除的值,如果不存在,则返回null。 |
| boolean isEmpty() | 判断哈希表是否为空 |
| boolean containsKey(Object key) | 判断给定的关键字是否在哈希表中 |
| boolean contains(Object value) | 判断给定的值是否在哈希表中 |
| boolean containsValue(Object value) | 判断给定的值是否在哈希表中 |
| void clear() | 将哈希表清空 |
| Enumeration elements() | 返回包含值的Enumeration对象 |
| Enumeration keys() | 返回包含关键字的Enumeration对象 |
HashMap类与HashTable类很相似,只是HashTable类不允许有空的关键字,而HashMap类允许
HashMap和Hashtable的比较
实现原理、功能相同,可以互用
主要区别
- Hashtable继承Dictionary类,HashMap实现Map接口
- Hashtable线程安全,HashMap线程非安全
- Hashtable不允许null值,HashMap允许null值
不涉及到多线程的开发过程中,最好使用ArrayList和HashMap
如果程序中用到多线程,酌情使用Vector和Hashtable
集合遍历与迭代器(Iterator)
如何遍历List, Set和Map集合呢?
方法1:循环(仅适用于List)
方法2:增强型for循环(foreach循环,适用于所有类)
方法3:通过迭代器Iterator实现遍历
- 获取Iterator :Collection 接口的iterate()方法
- Iterator的方法
boolean hasNext(): 判断是否存在另一个可访问的元素
Object next(): 返回要访问的下一个元素
方法4:(仅适用于JDK 1.8) 适用forEach()方法
Iterator接口
也是一个遍历集合元素的工具,是对Enumeration接口的改进,因此在遍历集合元素时,优先选用Iterator接口
与Enumeration不同,具有从正在遍历的集合中去除对象的能力
具有如下三个实例方法,可见相对于Enumerationo接口简化了方法名
- hasNext() —— 判断是否还有元素
- next() —— 取得下一个元素
- remove() —— 去除一个元素。注意是从集合中去除最后调用
- next()返回的元素,而不是从Iterator类中去除
遍历Map实例
Set keys=dogMap.keySet(); //取出所有key的集合
Iterator it=keys.iterator(); //获取Iterator对象
while(it.hasNext()){
String key=(String)it.next(); //取出key
Dog dog=(Dog)dogMap.get(key); //根据key取出对应的值
System.out.println(key+"\t"+dog.getStrain());
}
//迭代器Iterator
///////////////////////////////////////////////////
for(元素类型t 元素变量x : 数组或集合对象){
引用了x的java语句
}
//增加for型循环
///////////////////////////////////////////////////
Set keys=dogMap.keySet();
Keys.forEach(new DogConsumer()); //新建一个匿名对象
class DogConsumer implements Consumer {
public void accept(Object obj) { //每个Set中的对象,都会调用一次该方法
}
}
//JDK 1.8 之后可以使用forEach方法遍历集合
Enumeration
Enumeration接口不能用于ArrayList对象,而Iterator接口既可以用于ArrayList对象,也可以用于Vector对象
Enumeration接口 (1.0版)
提供了两个实例方法
- hasMoreElements() —— 判断是否还有剩下的元素;
- nextElement() —— 取得下一个元素。
遍历集合类对象v中的每个元素可使用下面代码完成:
Enumeration e = v.elements();
while (e.hasMoreElements()) {
Customer c = (Customer)v.nextElement();
System.out.println(c.getName());
}