FCOS算法详解
论文名称:FCOS:Fully Convolutional One-Stage Object Detection
作者:Zhi Tian & Chunhua Shen等
论文链接:https://arxiv.org/abs/1904.01355
代码链接:https://github.com/tianzhi0549/FCOS/
先放一张思维导图,串联一下知识点

简要概述文章精华
FCOS算法也是一篇anchor free的目标检测算法,但是其思想跟CornerNet系列有点不太一样,CornerNet系列的核心思想是通过Corner pooling来检测角点,然后对角点进行配对,最终得到检测结果,而FCOS方法借鉴了FCN的思想,对每个像素进行直接预测,预测的目标是到bounding box的上、下、左、右边的距离,非常的直观,另外为了处理gt重合的的时候,无法准确判断像素所属类别,作者引入了FPN结构,利用不同的层来处理不同的目标框,另外为了减少误检框,作者又引入了Center-ness layer,过滤掉大部分的误检框。FCOS的主干结构采用的是RetinaNet结构。
下面详细介绍一下这篇文章
Object detection是计算机视觉的一个重要的分支,其解决的问题是在一张图像中,找到图像中的目标并给出目标的类别以及坐标框,过去几年,Object detection取得了可喜的成果,很多的算法被提出,目标检测的精度也越来越高,这其中就包括:Faster RCNN,SSD,YOLO v2,v3等,这些方法有一个共同的特点,就是都是基于anchor的,可以说,过去几年,anchor是目标检测算法的灵魂,但是基于anchor的算法同样面临着几个问题:
- anchor的设计非常重要,超参数的设计比较难。
- anchor难以覆盖所有形状的目标,泛化能力较差。
- 为了取得较好的召回率,通常需要选取大量的anchor,计算量以及显存消耗都比较大。
那么既然基于anchor的算法存在这样的问题,我们是否可以抛弃anchor,直接进行目标检测呢?即anchor free算法。
本文便是其一。
作者的灵感来源于FCN,FCN可以使用在语义分割、关键点估计、深度估计等各个方面,唯独目标检测领域没有使用FCN,最主要的原因就在于对于anchor的依赖,那么我们是否可以大胆的将FCN应用于目标检测领域呢?使之成为统一的整体?作者就是这样干的,并且取得了比较理想的效果。
其实在作者之前也有人使用FCN方法进行目标检测,比如DenseBox,这个网络有必要说一下,其也算是一个想法比较大胆的网络,其使用FCN-based方法,对每点预测4个向量,分别是到上下左右四条边的距离,后面你会发现,其实本文也是这么干的,但是为了克服bounding box的尺度多样性(比如,图像中的大目标和小目标,回归的尺度范围不一样,大目标需要的值大一点,小目标相对小一点,这样就比较难统一),所以DenseBox在训练的时候将图像缩放到统一尺度,在预测的时候使用图像金字塔处理,但这其实脱离了FCN只计算一次的本质,并且召回比较低,另外DenseBox还遇到一个比较棘手的问题是,bounding box重合的时候,较难处理,如下图所示,那个点到底是要回归球拍还是回归人,因为无法判断该像素的类别以及目标,所以当时DenseBox值在场景检测、关键点检测方面效果较好,在目标检测效果不是很好。

本文作者就是在DenseBox的基础上,解决了上面提到的问题,取得了较不错的效果。
另外提到anchor free方法就不得不提一下anchor free方法的鼻祖:CornerNet,CornerNet的思想跟本文的思想还是有差别的,CornerNet的主要思想是在检测坐标框的时候,我不是一下检测整个坐标框(需要4个坐标),而是检测左上角点和右下角点(2个坐标),这样相比较于4个坐标,就相对简单一点,然后检测出左上角点和右下角点之后,再将其组合筛选出bounding box,筛选的过程需要较复杂的后处理逻辑。
介绍了这么多的背景,下面该本文的主角出场了
首先,介绍一下FCOS的预测目标,如果是基于anchor的方法,需要提取anchor然后通过anchor的变换来逼近目标,但是FCOS是anchor free的,那么它该如何求的目标呢?这里就是采用了FCN的套路,直接对每个坐标点进行预测,预测的目标呢,就如下图所示,分别是该点对应目标的上下左右四条边的距离。至于前面DenseBox提到的坐标框重合的情况,这里先忽略这个问题,先选择小的坐标框进行回归,后面会有方法解决它。

这就带来了一个好处,就是FCOS可以使用的正样本的数量就会很多了,相比较于基于anchor的方法,这或许也是该方法取得较好的效果的原因。
网络的输出依然包括分类和检测分支,分类分支通过卷积,输出是80维的向量,代表的是80个类别,并且80个类别接的是sigmoid,这点跟RetinaNet一致,检测分支输出的4维的向量,分别对应点到上下左右边的距离,模型结构如下图Figure 2所示,另外训练的时候,Classification采用的是focal loss,Regression采用的是IOU loss(IOU loss其实也很简单,就是- ln(IOU),详情可以参考论文:UnitBox),这里跟基于anchor的RetinaNet不太一样,RetinaNet回归使用的是smooth L1 loss。另外需要说明的是,网络中的头是共享的。
具体损失函数公式如下:
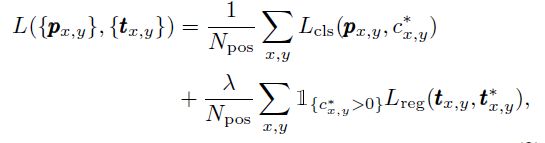

基本网络介绍完了,作者是如何解决重合的边界框的问题的呢?答案就是FPN结构。
作者使用FPN结构,可以将不同的目标框分散到不同的层中进行预测,这样就很大程度上减少了重叠的发生,作者也做了统计,不使用FPN存在大约23.16%的重合框,使用之后,降到了7.14%。并且使用FPN对小目标也有一定的帮助。

下图所示为使用FPN,multi-level之后的效果,可见使用multi-level之后,mAP几乎翻倍。

不同于基于anchor的方法,其利用anchor的尺度将不同目标分配到不同层,这里是利用max(l,r,t,b)的范围进行划分的。
并且由于这里使用的是共享头,但是不用的layer回归的尺度是不一样的,如果都使用相同的标准不太合理,所以这里作者使用了exp(sx)对边界框的回归进行处理,增加了一个比例调节因子s,这样就可以调节它的回归尺度了,比如前面层回归小一些,后面层回归大一些。
另外为了进一步降低目标的误检,作者引入了Center-ness层
Center-ness层的主要目标就是找到目标的中心点,即离目标中心越近,输出值越大,反之越小,这里作者的实现方式很简单,就是增加了一个1维的分类层的分支,上面的图Figure 2可以看到,而中心的目标定义如下公式,可见最中心的点的centerness为1,距离越远的点,centerness的值越小。
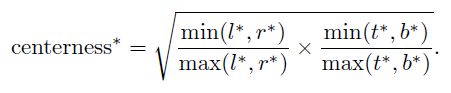
训练的时候,使用Binary CrossEntropy Loss。
在inference阶段,网络前向之后,将该Center-ness的值与classification的输出值相乘,这样可以有效的过滤掉一批误检框,提高识别准确度。
这里,作者也对比了使用center-ness的效果,结果如下表所示,其中center-ness+,代表的是在检测分支上直接进行中心点的预测,而不是在分类上增加一个分支,结果可以发现(1)在检测分支进行直接预测的结果并没有原来的好,在分类分支增加了center-ness,mAP可以提高大约3个点左右。另外作者也进行了实验,如果center-ness预测的全部都对的情况下(理想情况),mAP可以达到42.1%的准确率,说明其实center-ness还是有提升空间的,所以作者进一步进行了实验,将center-ness加深,结果显示mAP从36.6%提高到了36.8%。

介绍到这里,基本上网络的知识点都介绍完了,下面看一下网络的整体效果
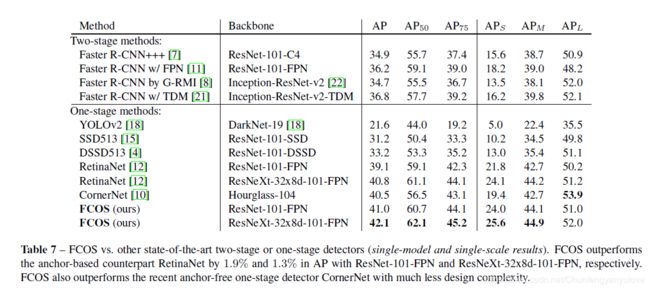
下表,是FCOS与现有比较好的算法的精度对比,可以发现还是具有一定优势的。
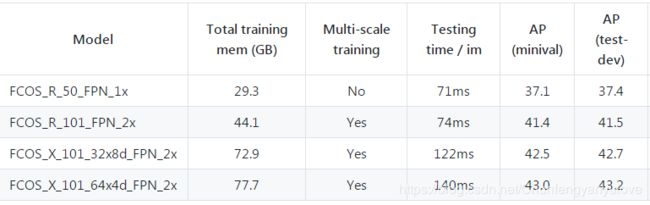
由于FCOS网络比较大,所以训练起来对显存的要求还是比较高的,根据作者GitHub的链接显示,训练需要的显存还是比较大的,ResNeXt101需要70G+的显存,估计没有牛逼卡的同学,最多也就可以训一个ResNet 50的,测试速度71ms,不算很快,但也还可以。
另外,FCOS也可以作为two-stage方法的RPN来使用,这里不详述了。感兴趣的读者可以自行了解,原理都是一样的。
总结
本文是一篇anchor free的目标检测方法,主要创新点在于,利用FCN的思想,同时引入了Center-ness层来进行中心度的计算(在anchor free方法中,center还是挺重要的),最终取得的效果还不错,随着算法能力的提升,现在在COCO上,没有个mAP > 0.4都不好意思拿出来秀。
本文为个人理解,如有错误,欢迎指正。