大数据----【HDFS】
HDFS入门
1. HDFS基本概念
1.1 HDFS介绍
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统。
分布式文件系统解决的问题就是大数据存储。
1.2 HDFS设计目标
- 硬件故障是常态 , 因此故障的检测和自动快速恢复是HDFS的黑心架构目标
- 数据访问的高吞吐量
- 支持大文件
- 对文件的要求是 write-one-read-many 访问模型 , 即一次写入多次读取
- 移动计算的代价比移动数据的代价低
- 可移植性
2. HDFS重要特性
-
HDFS特性
- 主从架构 , 各司其职
- 分块存储 hadoop 2.x默认是128M/块(1.x默认是64M)
如下例子 1.txt 100M blk-1:0-100M 2.txt 150M blk-1:0-128M blk-2:129-150M- 副本机制 默认3副本 指的是最终有几个副本
主角色有自己的职责 : 管理文件系统目录树 文件块信息
从角色也有自己的职责 : 保存最终的块的存储
两者各司其职 , 共同对外提供了分布式文件存储的能力
hdfs职责概述图解如下
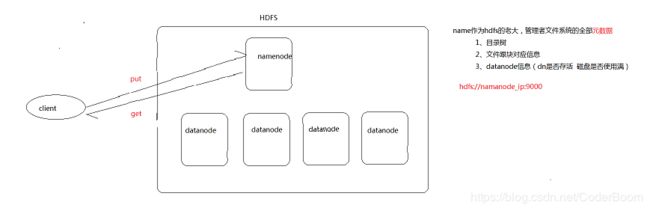
namenode作为hdfs的老大 , 管理着文件系统的全部元数据
- 目录树
- 文件跟块对应信息
- datanode信息(dn是否存活 , 磁盘是否已满)
访问 : hdfs://namenode_ip:9000
Q1 : 分布式是用来干什么的 , 为什么使用分布式?
分布式是用来解决大数据的存储的问题 , 由于传统的文件存储模式固有的瓶颈 : 内存不足、磁盘不足 , 我们本能的采取缺啥补啥(加内存 , 加磁盘) , 但是这样的做法是有上限的 , 因此我们想到了增加机器 , 也就是分布式来解决这个问题.
Q2 : 为什么单独配置一台文件位置存储的服务器?
由于文件系统变成多台的时候 , 查询文件变得不那么方便了 , 因此我们专门部署一台服务器用于记录文件所在的位置信息 , 用元数据描述清文件所在的位置 , 这样使得查询文件变得方便且快速.
Q3 : 为什么使用分块存储?
由于文件的过大 , 会导致文件上传和下载变得耗时 , 因此我们采取分块存储的技术来实现存储的高效性 , 同时分块使得文件查询也变得有条不紊 .
Q4 : 为什么要备份(副本)?
为了防止机器出现故障 , 导致数据块的缺失 , 同时保证数据的安全性 , 同时也有一些弊端 , 备份越大 , 表明冗余越高 , 但是数据越安全 , 这是一个抉择问题.
总结 : 分布式文件系统特征
如何解决文件存不下问题---->分布式 , 多台机器
如何解决数据查找不方便的问题----> 元数据记录 , 抽象成立于人理解的目录树
如何解决数据上传下载耗时问题---->分块存储
如何解决数据丢失安全问题---->备份 , 副本机制
模拟实现分布式文件系统图解

3. HDFS基本操作
3.1 Shell命令行客户端
方法 : hadoop fs
URI 格式为 scheme://authority/path。对于 HDFS,该 scheme 是 hdfs,对于本地 FS,该 scheme 是 file。scheme 和 authority 是可选的。如果未指定,则使用配置中指定的默认方案。
hdfs shell客户端
hadoop fs -ls hdfs://node-1:9000/ 操作hdfs文件系统
hadoop fs -ls file:///root 操作本地文件系统
hadoop fs -ls / 如果不指定 就采用默认文件系统 至于默认文件系统是谁 看配置文件fs.defaultFS
- hadoop fs -put local mubiao 把文件从本地文件系统复制到目标文件系统
- hadoop fs -get mubiao local 把目标文件复制到本地文件系统
Q: 哪个是本地文件系统?(windows linux hdfs)
本地文件系统 指的是 执行命令所在机器的文件系统就是本地
比如:node-1 执行 从node-1的本地linux文件系统上传到hdfs分布式文件系统
hadoop fs -put file:///root/install.log.syslog hdfs://node-1:9000/in
等价于
hadoop fs -put install.log.syslog /in
3.2 Shell命令选项
| 选项名称 | 使用格式 | 含义 |
|---|---|---|
| -ls | -ls <路径> | 查看指定路径的当前目录结构 |
| -lsr | -lsr <路径> | 递归查看指定路径的目录结构 |
| -du | -du <路径> | 统计目录下个文件大小 |
| -dus | -dus <路径> | 汇总统计目录下文件(夹)大小 |
| -count | -count [-q] <路径> | 统计文件(夹)数量 |
| -mv | -mv <源路径> <目的路径> | 移动 |
| -cp | -cp <源路径> <目的路径 | 复制 |
| -rm | -rm [-skipTrash] <路径> | 删除文件/空白文件夹 |
| -rmr | -rmr [-skipTrash] <路径> | 递归删除 |
| -put | -put <多个 linux 上的文件> |
上传文件 |
| -copyFromLocal | -copyFromLocal <多个 linux 上的文件> |
从本地复制 |
| -moveFromLocal | -moveFromLocal <多个 linux 上的文件> |
从本地移动 |
| -getmerge | -getmerge <源路径> |
合并到本地 |
| -cat | -cat |
查看文件内容 |
| -text | -text |
查看文件内容 |
| -copyToLocal | -copyToLocal [-ignoreCrc] [-crc] [hdfs源路径] [linux 目的路径] |
从本地复制 |
| -moveToLocal | -moveToLocal [-crc] |
从本地移动 |
| -mkdir | -mkdir |
创建空白文件夹 |
| -setrep | -setrep [-R] [-w] <副本数> <路径> |
修改副本数量 |
| -touchz | -touchz <文件路径> | 创建空白文件 |
| -stat | -stat [format] <路径> | 显示文件统计信息 |
| -tail | -tail [-f] <文件> | 查看文件尾部信息 |
| -chmod | -chmod [-R] <权限模式> [路径] |
修改权限 |
| -chown | -chown [-R] [属主][:[属组]] 路径 |
修改属主 |
| -chgrp | -chgrp [-R] 属组名称 路径 | 修改属组 |
| -help | -help [命令选项] | 帮助 |
3.3 Shell 常用命令介绍
- ls
使用方法:hadoop fs -ls[-h][-R]
功能:显示文件、目录信息。
示例:hadoop fs -ls /user/hadoop/file1==> 显示user/hadoop下的file1文件信息 - mkdir
使用方法:hadoop fs -mkdir [-p]
功能:在 hdfs 上创建目录,-p 表示会创建路径中的各级父目录。
示例:hadoop fs -mkdir –p /user/hadoop/dir1==> 在user/hadoop下创建dir1文件夹 - put
使用方法:hadoop fs -put [-f][-p] [ -|.. ].
功能:将单个 src 或多个 srcs 从本地文件系统复制到目标文件系统。
-p:保留访问和修改时间,所有权和权限。
-f:覆盖目的地(如果已经存在)
示例:hadoop fs -put -f startZk.sh /test==> 将linux本地的startZk.sh上传到hadoop根目录下的test目录下 - get
使用方法:hadoop fs -get [-ignorecrc][-crc] [-p][-f]
-ignorecrc:跳过对下载文件的 CRC 检查。
-crc:为下载的文件写 CRC 校验和。
功能:将文件复制到本地文件系统。
示例:hadoop fs -get /test/startZk.sh /root/test==> 将hadoop的test文件夹下的startZk.sh下载到本地root目录下的test目录下 - appendToFile
使用方法:hadoop fs -appendToFile...
功能:追加一个文件到已经存在的文件末尾
示例:hadoop fs -appendToFile 1.txt /test/2.txt==> 将本地1.txt内容追加到hadoop的test目录下的2.txt后 - cat
使用方法:hadoop fs -cat [-ignoreCrc] URI [URI ...]
功能:显示文件内容到 stdout
示例:hadoop fs -cat /test/2.txt==>显示2.txt的内容到stdout - tail
使用方法:hadoop fs -tail [-f] URI
功能:将文件的最后一千字节内容显示到 stdout。
-f 选项将在文件增长时输出附加数据。
示例:hadoop fs -tail /hadoop/hadoopfile - chgrp
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI ...]
功能:更改文件组的关联。用户必须是文件的所有者,否则是超级用户。
-R 将使改变在目录结构下递归进行。
示例:hadoop fs -chgrp othergroup /hadoop/hadoopfile - chmod
功能:改变文件的权限。使用-R 将使改变在目录结构下递归进行。
示例:hadoop fs -chmod 666 /hadoop/hadoopfile - chown
功能:改变文件的拥有者。使用-R 将使改变在目录结构下递归进行。
示例:hadoop fs -chown someuser:somegrp /hadoop/hadoopfile - copyFromLocal
使用方法:hadoop fs -copyFromLocalURI
功能:从本地文件系统中拷贝文件到 hdfs 路径去
示例:hadoop fs -copyFromLocal /root/1.txt / - copyToLocal
功能:从 hdfs 拷贝到本地
示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz - cp
功能:从 hdfs 的一个路径拷贝 hdfs 的另一个路径
示例:hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 - mv
功能:在 hdfs 目录中移动文件
示例:hadoop fs -mv /aaa/jdk.tar.gz / - getmerge
功能:合并下载多个文件
示例:比如 hdfs 的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /aaa/log.* ./log.sum - rm
功能:删除指定的文件。只删除非空目录和文件。-r 递归删除。
示例:hadoop fs -rm -r /aaa/bbb/ - df
功能:统计文件系统的可用空间信息
示例:hadoop fs -df -h / - du
功能:显示目录中所有文件大小,当只指定一个文件时,显示此文件的大小。
示例:hadoop fs -du /user/hadoop/dir1 - setrep
功能:改变一个文件的副本系数。-R 选项用于递归改变目录下所有文件的副本
系数。
示例:hadoop fs -setrep -w 3 -R /user/hadoop/dir1