(十一)为什么堆叠的集成模型容易赢得 kaggle 比赛?
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
(一)机器学习中的集成学习入门
(二)bagging 方法
(三)使用Python进行交易的随机森林算法
(四)Python中随机森林的实现与解释
(五)如何用 Python 从头开始实现 Bagging 算法
(六)如何利用Python从头开始实现随机森林算法
(七)AdaBoost 简介
(八)Python 中的 AdaBoost 分类器实例
(九)AdaBoost 中参数对于决策边界复杂度分析
(十)stacking 简介
(十一)为什么堆叠的集成模型容易赢得 kaggle 比赛?
集合方法通常用于通过组合多个机器学习模型的预测来提高整体预测准确性。传统的方法是将所谓的“弱”学习器结合起来。然而,更现代的方法是精心挑选一些强大而多样化的模型从而来构成一个模型集合。
建立强大的整体模型与在商业,科学,政治和体育领域,建立成功的人类团队有许多相似之处。每个团队成员都做出了重大贡献,个人的弱点和偏见被其他成员的优势所抵消。
最简单的集合是将模型库的模型预测进行累加,然后取平均值(这个称为未加权平均值)。例如,如果模型库包括三个区间目标模型(如下图所示),则未加权平均值需要将三个候选模型的预测值之和除以三。在未加权平均值中,每个模型在构建集合模型时都具有相同的权重。
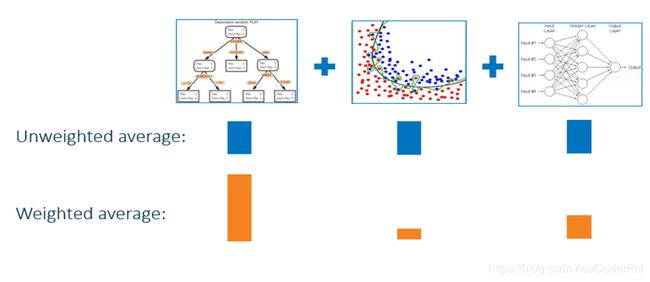
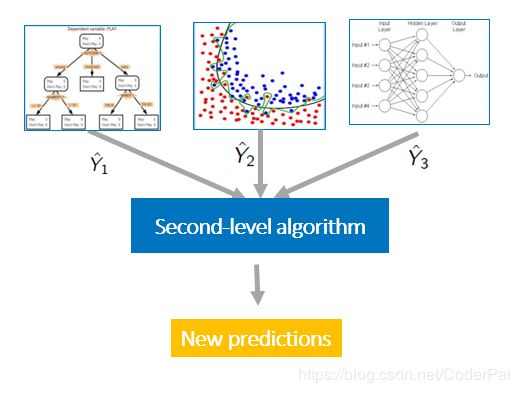
更一般的来说,你可以考虑使用加权平均值。例如,你可能认为某些模型更好或更准确,所以您希望手动为它们分配更高的权重。但更好的方法可能是通过使用另一层学习算法更智能地估计这些权重。这种方法称为模型堆叠。
模型堆叠是一种有效的集合方法,其中通过使用各种机器学习算法生成的预测被用作第二层学习算法中的输入。训练该第二层算法以最佳地组合模型预测以形成新的预测集。例如,当线性回归用作第二层建模时,它通过最小化最小平方误差来估计这些权重。但是,第二层建模不仅限于线性模型;预测变量之间的关系可能更复杂,这就为使用其他机器学习算法打开了大门。
通过集成建模赢得数据科学竞赛
集合建模和模型堆叠在数据科学竞赛中特别受欢迎,其中组织者发布训练集(包括标签)和测试集(不包括标签)并且参赛选手会产生一个榜单。 获奖团队几乎总是使用整体模型而不是单个微调模型。 个人团队通常会在比赛的早期阶段开发自己的集成模型,然后在后期加入他们的微调。
在热门的数据科学竞赛网站 Kaggle,您可以通过其论坛探索众多获奖解决方案,以获得最先进的经验。 另一个受欢迎的数据科学竞赛是 KDD cup。 下图显示了2015年竞赛的获胜解决方案,该竞赛使用了三阶段堆叠建模方法。

该图显示了使用 64 个单一模型来构建模型库。通过使用各种机器学习算法来训练这些模型。例如,绿色框表示梯度增强模型(GBM),粉红色框表示神经网络模型(NN),橙色框表示分解机器模型(FM)。您可以看到模型库中有多个梯度增强模型;它们在使用不同的超参数设置和/或特征集时可能会有所不同。
在阶段1,来自这64个模型的预测被用作训练15个新模型的输入,再次使用各种机器学习算法。在阶段2(集成堆叠),来自阶段1模型的预测被用作通过使用梯度增强和线性回归训练两个模型的输入。在阶段3集成堆叠(最后阶段),来自阶段2的两个模型的预测被用作逻辑回归(LR)模型中的输入以形成最终集合。
为了建立一个强大的预测模型,就像用来赢得2015年KDD cup一样,建立一套多样化的初始模型起着重要的作用!有多种方法可以增强多样性,例如使用:
- 不同的训练算法。
- 不同的超参数设置。
- 不同的特征子集。
- 不同的训练集。
增强多样性的一种简单方法是使用不同的机器学习算法训练模型。例如,将分解模型添加到一组基于树的模型(例如随机森林和梯度提升)提供了很好的多样性,因为分解模型的训练方式与训练决策树模型的方式非常不同。对于相同的机器学习算法,您可以通过使用不同的超参数设置和变量子集来增强多样性。如果您有许多特征,一种有效的方法是通过简单的随机抽样选择变量的子集。选择变量子集可以以更好的方式完成,该方式基于一些计算的重要性度量,这引入了特征选择的大而难的问题。
除了使用各种机器学习训练算法和超参数设置外,上面显示的KDD Cup解决方案还使用了七种不同的特征集(F1-F7)来进一步增强多样性。创建多样性的另一种简单方法是生成各种版本的训练数据。这可以通过 bagging 和交叉验证来完成。
如何避免过度拟合堆叠的集合模型
过度拟合是构建预测模型时无所不在的关注点,每个数据科学家都需要配备一定的技巧来处理它。过度拟合模型非常复杂,会使得模型非常适合训练数据,但它对于新数据集的推广非常差。过度拟合在模型堆叠中是一个特别大的问题,因为所有预测相同目标的预测器都被组合在一起。过度拟合部分是由预测变量之间的这种共线性引起的。
用于训练模型的最有效技术(尤其是在堆叠阶段期间)包括使用交叉验证和某种形式的正则化。下图提供了我们的集合方法的简单摘要。这是一个避免过拟合非常好的方法。

将堆叠模型应用于实际大数据问题可以比单个模型产生更高的预测准确性和稳健性。 模型堆叠方法功能强大且足以引人注目,可以将您的初始数据挖掘思维方式从找到单一最佳模型转变为找到真正优秀的互补模型集合。