Java NIO学习笔记:结合源码分析+Reactor模式
Java NIO和IO的主要区别
下表总结了Java NIO和IO之间的主要差别,我会更详细地描述表中每部分的差异。
| IO | NIO |
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
面向流与面向缓冲
Java NIO和IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
阻塞与非阻塞IO
Java IO的各种流(Stream)是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
先上代码看看,传统IO vs NIO
传统IO读取文件 代码一览
案例采用FileInputStream读取文件内容的:
// 传统IO模式读取文件内容
public void IoDemo() throws IOException {
InputStream in =
new BufferedInputStream(new FileInputStream("xx.txt"));
byte[] buf = new byte[1024];
int bytesRead = in.read(buf);
while (bytesRead != -1) {
for (int i = 0;i < bytesRead; i++) {
System.out.println((char) buf[i]);
bytesRead = in.read(buf);
}
}
in.close();
}输出结果:(略)
然后看看NIO的代码怎么写
案例是对应的NIO(这里通过RandomAccessFile进行操作,当然也可以通过FileInputStream.getChannel()进行操作):
// NIO模式读取文件内容
public void NioTest() throws IOException {
RandomAccessFile aFile =
new RandomAccessFile("xx.txt", "tw");
FileChannel fileChannel = aFile.getChannel();
ByteBuffer buf = ByteBuffer.allocate(1024);
int bytesRead = fileChannel.read(buf);
System.out.println(bytesRead);
while (bytesRead != -1) {
buf.flip();
while (buf.hasRemaining()) {
System.out.println((char) buf.get());
}
buf.compact();
bytesRead = fileChannel.read(buf);
}
aFile.close();
}输出结果:(略)
通过代码的对比,应该能看出个大概,最起码能发现NIO的实现方式比叫复杂。有了一个大概的印象可以进入下一步了。
NIO 核心组件
- Channel
- Buffer
- Selector
Channel
Java NIO Channel通道和流非常相似,主要有以下几点区别:
- Channel是双向的,也就是说可读也可写。Stream是单向的(只能读或者写)。
- Channel可以异步读写。
- Channel总是基于缓冲区Buffer来读写。
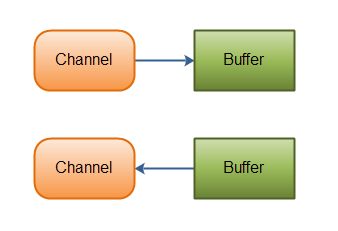
Java NIO: Channels read data into Buffers, and Buffers write data into Channels
翻译:Channels读数据到Buffers,Buffers写数据到Channels
这里有个问题,就是往buffer里写数据为什么是channel.read(buffer);呢,按理说“写”对应的不应该是“write”吗。我刚开始这里也容易搞混。后来看了源码的解释和重新思考了一下面向对象的思想,这个问题也就想明白了
- 首先面向对象的主体是对象,所有的操作都是围绕着这个对象展开的。这里channel就是对象,而read()这个方法是针对channel的。
- 再来看源码的解释
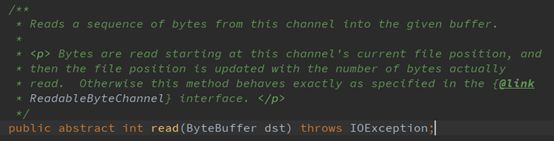
注意这句:
Reads a sequence of bytes from this channel into the given buffer.
翻译:从channel读一些bytes到buffer里。
小结:这个read()是针对channel而言的,意思就是从先从channel读取一些bytes,然后再写到buffer里。
常用Channel
Channel就像他的名字一样,只是个“管道”不保存数据,是用来传输数据的,而且这种传输是双向的,可以传入也可以传出。
下面列出Java NIO中最重要的集中Channel的实现:
- FileChannel:文件的数据读写。
- DatagramChannel:UDP的数据读写。
- SocketChannel:TCP的数据读写。
- ServerSocketChannel:允许我们监听TCP链接请求,每个请求会创建会一个SocketChannel.
Channel的基础示例(Basic Channel Example)
这有一个利用FileChannel读取数据到Buffer的例子:
注意:因为Channel要结合Buffer一起才能使用,所以这里的Channel示例和下面的Buffer代码基本相同。更详细的后面会讲
RandomAccessFile aFile = new RandomAccessFile("xx.txt", "rw");
FileChannel inChannel = aFile.getChannel();
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf);
while (bytesRead != -1) {
System.out.println("Read " + bytesRead);
buf.flip();
while(buf.hasRemaining()){
System.out.print((char) buf.get());
}
buf.clear();
bytesRead = inChannel.read(buf);
}
aFile.close();注意buf.flip()的调用,
如果想要从Buffer读取数据,要调用flip()方法,把Buffer从写模式(write mode)切换到读模式(read mode)。
后面会详细讲file()
Buffer
Buffer顾名思义:缓冲区,实际上是一个容器,一个连续数组。
Channel提供从文件、网络读取数据的渠道,但是读写的数据都必须经过Buffer。如下图: 
向Buffer中写数据有两种方法:
- 从Channel写到Buffer (fileChannel.read(buf))
- 通过Buffer的put()方法 (buf.put(…))
从Buffer中读取数据同样也有两种方法:
- 从Buffer读取到Channel (channel.write(buf))
- 使用get()方法从Buffer中读取数据 (buf.get())
Buffer属性:
- capacity
- position
- limit
- mark
这里直接看源码

源码中这一局交代了他们之间的大小关系
// Invariants: mark <= position <= limit <= capacityBuffer属性解释:
| 索引 |
说明 |
| capacity |
缓冲区数组的总长度。固定不变 |
| position |
是下一个要读取或写入的元素的索引(注意!不是当前索引!)。0 <= position <= limit |
| limit |
是读\写模式下可读\写的最大范围。0 <= limit <= capacity |
| mark |
用于记录当前position的位置,用于恢复position的位置。默认为-1。后面会讲 |
Java NIO Buffers用于和NIO Channel交互。正如你已经知道的,我们从channel中读取数据到buffers里,从buffer把数据写入到channels.
buffer本质上就是一块内存区,可以用来写入数据,并在稍后读取出来。这块内存被NIO Buffer包裹起来,对外提供一系列的读写方便开发的接口。
Buffer基本用法(Basic Buffer Usage)
利用Buffer读写数据,通常遵循四个步骤:
- 把数据写入buffer;
- 调用flip;
- 从Buffer中读取数据;
- 调用buffer.clear()或者buffer.compact()
当写入数据到buffer中时,buffer会记录已经写入的数据大小。当需要读数据时,通过flip()方法把buffer从写模式调整为读模式;在读模式下,可以读取所有已经写入的数据。
当读取完数据后,需要清空buffer,以满足后续写入操作。清空buffer有两种方式:调用clear()或compact()方法。clear会清空整个buffer,compact则只清空已读取的数据,未被读取的数据会被移动到buffer的开始位置,写入位置则近跟着未读数据之后。
读数据
这里有一个简单的buffer案例,包括了write,flip和clear操作:
RandomAccessFile aFile = new RandomAccessFile("xx.txt", "rw");
FileChannel inChannel = aFile.getChannel();
//create buffer with capacity of 48 bytes
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf); //read into buffer.
while (bytesRead != -1) {
buf.flip(); //make buffer ready for read
while(buf.hasRemaining()){
System.out.print((char) buf.get()); // read 1 byte at a time
}
buf.clear(); //make buffer ready for writing
bytesRead = inChannel.read(buf);
}
aFile.close();写数据
下面给出通过FileChannel来向文件中写入数据的一个例子:
File file = new File("data.txt");
FileOutputStream outputStream = new FileOutputStream(file);
FileChannel channel = outputStream.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
String string = "java nio";
buffer.put(string.getBytes());
buffer.flip(); //此处必须要调用buffer的flip方法
channel.write(buffer);
channel.close();
outputStream.close();通过上面的程序会向工程目录下的data.txt文件写入字符串"java nio",注意在调用channel的write方法之前必须调用buffer的flip方法,否则无法正确写入内容,至于具体原因将在下篇博文中具体讲述Buffer的用法时阐述。
常见Buffer类型
Java NIO有如下具体的Buffer类型:
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
Buffer常见方法,flip()
没什么比直接看源码学习更高效的了,直接上源码

如果你英文不错的,官方的介绍其实是很清楚的。
我来稍微解释下:
- flip()方法可以吧Buffer从写模式(write mode)切换到读模式(read mode)。
- 调用flip方法会把设置limit为之前的position的值,并把position归零。
- 如果mark之前被设置了,那么调用这个方法之后它将会被抛弃。
不太懂?没关系,下面会有详细的图解
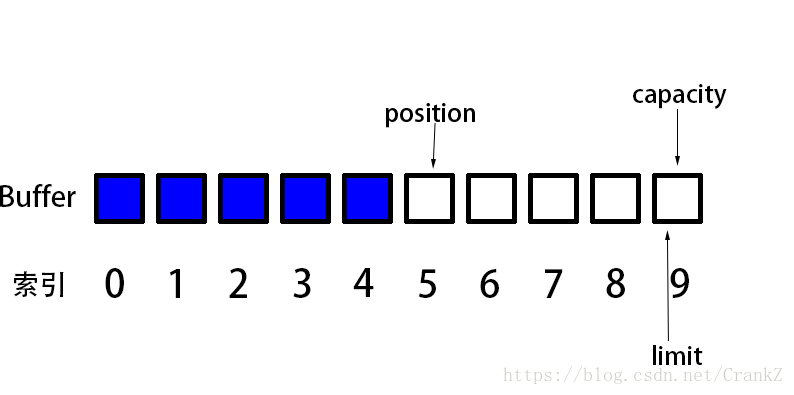
capacity,limit,position三个属性的关系与图解
给Buffer分配内存大小为10的缓存区。
Buffer的容量为10,所以capacity为10,在这里指向索引为10的空间。
Buffer初始化的时候,limit和capacity指向同一最后的那个索引,position指向0。

往Buffer里加一个数据。position位置移动,capacity不变,limit不变。

继续加到5个数据,position指向索引为5的第6个数据,capacity不变,limit不变。
执行flip()
这时候对照着,之前flip源码去看。把position的值赋给limit,所以limit=5,然后position=0。capacity不变。结果就是:

Buffer开始往外写数据。每写一个,position就下移一个位置,一直移到limit的位置,结束。
所以读完之后的状态如图

上图的顺序就是代码中的buffer从初始化,到写数据,再读数据三个状态下,capacity,position,limit三个属性的变化和关系。
大家可以发现:
1. 0 <= position <= limit <= capacity
2. capacity始终不变
图中很好的阐述了,Buffer读写切换的过程。即flip()的反转原理。接下来我们从代码中检测上面的分析过程。想一下下面代码打印的内容,然后执行一编代码看看对不对。
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(10);
System.out.println("初始化");
System.out.println("position:" + buffer.position() +
",limit:" + buffer.limit() +
",capacity:" + buffer.capacity());
String str = "abcde";
buffer.put(str.getBytes());
System.out.println("填充数据完毕后");
System.out.println("position:" + buffer.position() +
",limit:" + buffer.limit() +
",capacity:" + buffer.capacity());
buffer.flip();
System.out.println("调用flip()后");
System.out.println("position:" + buffer.position() +
",limit:" + buffer.limit() +
",capacity:" + buffer.capacity());
System.out.println("开始读取");
while (buffer.hasRemaining()) {
System.out.println("position:" + buffer.position() +
",limit:" + buffer.limit() +
",capacity:" + buffer.capacity());
System.out.println("元素:" + Character.toString((char) buffer.get()));
}
System.out.println("读取完毕");
System.out.println("position:" + buffer.position() +
",limit:" + buffer.limit() +
",capacity:" + buffer.capacity());
}运行结果

rewind()
直接上源码
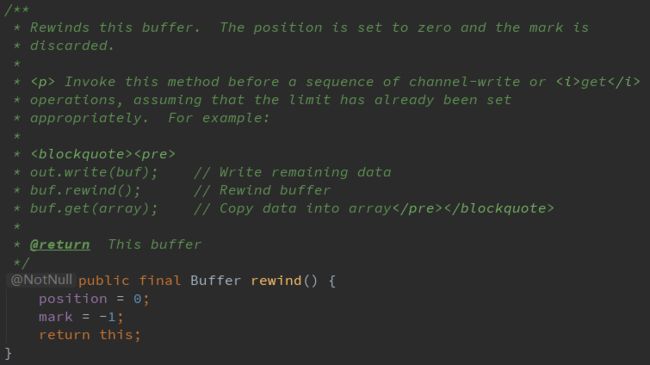
源码讲的很清楚,rewind()和flip()就相差一个
Limit = position;clear() and compact()
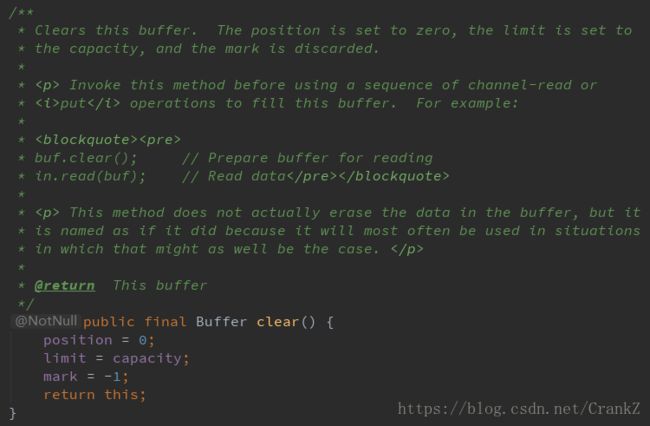
一旦我们从buffer中读取完数据,需要复用buffer为下次写数据做准备。只需要调用clear或compact方法。
clear方法会重置position为0,limit为capacity,也就是整个Buffer清空。实际上Buffer中数据并没有清空,我们只是把标记为修改了。
如果Buffer还有一些数据没有读取完,调用clear就会导致这部分数据被“遗忘”,因为我们没有标记这部分数据未读。
针对这种情况,如果需要保留未读数据,那么可以使用compact。 因此compact和clear的区别就在于对未读数据的处理,是保留这部分数据还是一起清空。
mark() and reset()
提醒:mark()和reset()要搭配使用
使用步骤
- 先用mark()标记当前的position位置
- 后期再通过reset()恢复position到标记的位置。
mark源码

源码其实很清晰,就是 mark = position;
reset源码

把position恢复到之前通过mark()方法,标记的位置。
Channel与Buffer区别与联系
在NIO中并不是以流的方式来处理数据的,而是以buffer缓冲区和Channel管道配合使用来处理数据。
简单理解一下:
- Channel管道比作成铁路,buffer缓冲区比作成火车(运载着货物)
而我们的NIO就是通过Channel管道运输着存储数据的Buffer缓冲区的来实现数据的处理!
- 要时刻记住:Channel不与数据打交道,它只负责运输数据。与数据打交道的是Buffer缓冲区
- Channel-->运输
- Buffer-->数据
相对于传统IO而言,流是单向的。对于NIO而言,有了Channel管道这个概念,我们的读写都是双向的(铁路上的火车能从广州去北京、自然就能从北京返还到广州)!
Channel通道只负责传输数据、不直接操作数据的。操作数据都是通过Buffer缓冲区来进行操作!
Selector
Selector就是用来管理多个Channel的。
使用步骤:
- 先把要管理的Channel注册到Selector上
- 然后Selector能够检测多个注册的Channel上是否有事件发生
- 如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理
这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事件发生时,才会调用函数来进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,并且避免了多线程之间的上下文切换导致的开销。
与Selector有关的一个关键类是SelectionKey,一个SelectionKey表示一个到达的事件,这2个类构成了服务端处理业务的关键逻辑。
核心类
- Selector
- SelectionKey
先来看一下源码了解一下主要属性和功能
Selector

SelectionKey

使用方法
创建Selector
Selector selector = Selector.open();向Selector注册通道
当向Selector中注册Channel时,Channel必须是非阻塞的,所以不可以注册FileChannel,因为FileChannel没有实现SelectableChannel接口,不能配置为非阻塞状态模式。
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, Selectionkey.OP_READ);当将通道Channel注册到Selector中时,需要在第二个参数中指定相应观察事件的集合interest集合,即SelectionKey中的几个代表状态的整数。如果想注册多种状态需要用位或(|)操作符进行连接。
| SelectionKey.OP_CONNECT |
连接就绪 |
| SelectionKey.OP_ACCEPT |
接收就绪 |
| SelectionKey.OP_READ |
读就绪 |
| SelectionKey.OP_WRITE |
写就绪 |
可以在注册完Channel到Selector之后,通过获取到的SelectionKey来获取ready集合key.readyOps();,即可以得到所观察事件是否就绪的一个位或操作之后的值,此时只需要使用相应的interest值与readyOps值取与(&)操作即可确定此事件是否就绪。或者使用JDK提供的四个API(而实际JDK底层代码也是取与操作进行判断的)如下:
key.isConnectable();
key.isAcceptable();
key.isReadable();
key.isWritable();SelectionKey中还可以添加一些附加对象来标识对应注册的是哪个Channel。方法有两种如下
Object attach = new Object();
// 方法1:在注册时候的第三个参数指定
SelectionKey key = channel.register(selector, SelectionKey.OP_ACCEPT, attach);
// 方法2:使用attach()方法指定
key.attach(attach);
//获取附加对象的方法
Object attached = key.attachment();选择通道
当向Selector中注册了通道,就可以调用select来获取有多少通道发生了我们所感兴趣的(interest集合)事件和。该方法及其重载返回的int值表示有多少通道已经就绪。亦即,自上次调用select()方法后有多少通道变成就绪状态。如果调用select()方法,因为有一个通道变成就绪状态,返回了1,若再次调用select()方法,如果另一个通道就绪了,它会再次返回1。如果对第一个就绪的channel没有做任何操作,现在就有两个就绪的通道,但在每次select()方法调用之间,只有一个通道就绪了。
一旦select()方法返回非零,就可以通过selector.selectedKeys()方法获得所有的以选择即已就绪SelectionKey,通过遍历获取到是SelectionKey的哪个事件就绪。注意每次迭代末尾的keyIterator.remove()调用。Selector不会自己从已选择键集中移除SelectionKey实例。必须在处理完通道时自己移除。下次该通道变成就绪时,Selector会再次将其放入已选择键集中。
// 阻塞到至少有一个通道在你注册的事件上就绪了。
selector.select();
// 和select()一样,除了最长会阻塞timeout毫秒(参数)。
selector.select(1000);
// 不会阻塞,不管什么通道就绪都立刻返回,如果无通道就绪,则立即返回零
selector.selectNow();
// 遍历就绪的SelectionKey
Set keys = selector.selectedKeys();
Iterator iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey selectedKey = iterator.next();
if (key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
iterator.remove();
} 唤醒Selector
某个线程调用select()方法后阻塞了,即使没有通道已经就绪,也有办法让其从select()方法返回。只要让其它线程在第一个线程调用select()方法的那个对象上调用Selector.wakeup()方法即可。阻塞在select()方法上的线程会立马返回。
如果有其它线程调用了wakeup()方法,但当前没有线程阻塞在select()方法上,下个调用select()方法的线程会立即“醒来(wake up)”。
selector.wakeup();关闭Selector
用完Selector后调用其close()方法会关闭该Selector,且使注册到该Selector上的所有SelectionKey实例无效。通道本身并不会关闭。
selector.close();Selector代码实战
后面讲Reactor模式的时候会有一个综合代码
为什么使用Selector(Why Use a Selector?)
用单线程处理多个channels的好处是我需要更少的线程来处理channel。实际上,你甚至可以用一个线程来处理所有的channels。从操作系统的角度来看,切换线程开销是比较昂贵的,并且每个线程都需要占用系统资源,因此暂用线程越少越好。
需要留意的是,现代操作系统和CPU在多任务处理上已经变得越来越好,所以多线程带来的影响也越来越小。如果一个CPU是多核的,如果不执行多任务反而是浪费了机器的性能。不过这些设计讨论是另外的话题了。简而言之,通过Selector我们可以实现单线程操作多个channel。
这有一幅示意图,描述了单线程处理三个channel的情况:
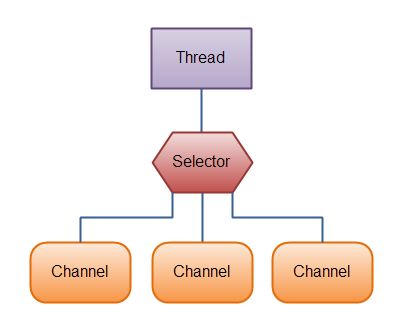
Java NIO: A Thread uses a Selector to handle 3 Channel's
其余功能介绍
看完以上陈述,详细大家对NIO有了一定的了解,下面主要通过几个案例,来说明NIO的其余功能,下面代码量偏多,功能性讲述偏少。
零拷贝
Java NIO中提供的FileChannel拥有transferTo和transferFrom两个方法,可直接把FileChannel中的数据拷贝到另外一个Channel,或者直接把另外一个Channel中的数据拷贝到FileChannel。该接口常被用于高效的网络/文件的数据传输和大文件拷贝。在操作系统支持的情况下,通过该方法传输数据并不需要将源数据从内核态拷贝到用户态,再从用户态拷贝到目标通道的内核态,同时也避免了两次用户态和内核态间的上下文切换,也即使用了“零拷贝”,所以其性能一般高于Java IO中提供的方法。
使用FileChannel的零拷贝将本地文件内容传输到网络的示例代码如下所示。
public class NIOClient {
public static void main(String[] args) throws IOException, InterruptedException {
SocketChannel socketChannel = SocketChannel.open();
InetSocketAddress address = new InetSocketAddress(1234);
socketChannel.connect(address);
RandomAccessFile file = new RandomAccessFile(
NIOClient.class.getClassLoader().getResource("test.txt").getFile(), "rw");
FileChannel channel = file.getChannel();
channel.transferTo(0, channel.size(), socketChannel);
channel.close();
file.close();
socketChannel.close();
}
}
Scatter/Gatter
分散(scatter)从Channel中读取是指在读操作时将读取的数据写入多个buffer中。因此,Channel将从Channel中读取的数据“分散(scatter)”到多个Buffer中。
聚集(gather)写入Channel是指在写操作时将多个buffer的数据写入同一个Channel,因此,Channel 将多个Buffer中的数据“聚集(gather)”后发送到Channel。
scatter / gather经常用于需要将传输的数据分开处理的场合,例如传输一个由消息头和消息体组成的消息,你可能会将消息体和消息头分散到不同的buffer中,这样你可以方便的处理消息头和消息体。
案例:
public class ScattingAndGather
{
public static void main(String args[]){
gather();
}
public static void gather()
{
ByteBuffer header = ByteBuffer.allocate(10);
ByteBuffer body = ByteBuffer.allocate(10);
byte [] b1 = {'0', '1'};
byte [] b2 = {'2', '3'};
header.put(b1);
body.put(b2);
ByteBuffer [] buffs = {header, body};
try
{
FileOutputStream os = new FileOutputStream("src/scattingAndGather.txt");
FileChannel channel = os.getChannel();
channel.write(buffs);
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
Pipe
Java NIO 管道是2个线程之间的单向数据连接。Pipe有一个source通道和一个sink通道。
数据会被写到sink通道,从source通道读取。
public static void method1() throws IOException {
Pipe pipe = Pipe.open();
ExecutorService exec = Executors.newFixedThreadPool(2);
final Pipe pipeTemp = pipe;
exec.submit(() -> {
// 向通道中写数据
Pipe.SinkChannel sinkChannel = pipeTemp.sink();
while (true) {
TimeUnit.SECONDS.sleep(1);
String newData = "Pipe Test At Time " + System.currentTimeMillis();
ByteBuffer buf = ByteBuffer.allocate(1024);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while (buf.hasRemaining()) {
System.out.println(buf);
sinkChannel.write(buf);
}
}
});
exec.submit(() -> {
// 向通道中读数据
Pipe.SourceChannel sourceChannel =
pipeTemp.source();
while (true) {
TimeUnit.SECONDS.sleep(1);
ByteBuffer buf = ByteBuffer.allocate(1024);
buf.clear();
int bytesRead = sourceChannel.read(buf);
System.out.println("bytesRead=" + bytesRead);
while (bytesRead > 0) {
buf.flip();
byte b[] = new byte[bytesRead];
int i = 0;
while (buf.hasRemaining()) {
b[i] = buf.get();
System.out.println("%X" + b[i]);
i++;
}
String s = new String(b);
System.out.println("===============||" + s);
bytesRead = sourceChannel.read(buf);
}
}
});
exec.shutdown();
}两种高性能IO设计模式
在传统的网络服务设计模式中,有两种比较经典的模式:
一种是 多线程,一种是线程池。
多线程
对于多线程模式,也就说来了client,服务器就会新建一个线程来处理该client的读写事件,如下图所示:

这种模式虽然处理起来简单方便,但是由于服务器为每个client的连接都采用一个线程去处理,使得资源占用非常大。因此,当连接数量达到上限时,再有用户请求连接,直接会导致资源瓶颈,严重的可能会直接导致服务器崩溃。
线程池
因此,为了解决这种一个线程对应一个客户端模式带来的问题,提出了采用线程池的方式,也就说创建一个固定大小的线程池,来一个客户端,就从线程池取一个空闲线程来处理,当客户端处理完读写操作之后,就交出对线程的占用。因此这样就避免为每一个客户端都要创建线程带来的资源浪费,使得线程可以重用。
但是线程池也有它的弊端,如果连接大多是长连接,因此可能会导致在一段时间内,线程池中的线程都被占用,那么当再有用户请求连接时,由于没有可用的空闲线程来处理,就会导致客户端连接失败,从而影响用户体验。因此,线程池比较适合大量的短连接应用。
因此便出现了下面的两种高性能IO设计模式:Reactor和Proactor。
Reactor
在Reactor模式中,会先对每个client注册感兴趣的事件,然后有一个线程专门去轮询每个client是否有事件发生,当有事件发生时,便顺序处理每个事件,当所有事件处理完之后,便再转去继续轮询,如下图所示:

从这里可以看出,多路复用IO就是采用Reactor模式。注意,上面的图中展示的 是顺序处理每个事件,当然为了提高事件处理速度,可以通过多线程或者线程池的方式来处理事件。
Proactor
在Proactor模式中,当检测到有事件发生时,会新起一个异步操作,然后交由内核线程去处理,当内核线程完成IO操作之后,发送一个通知告知操作已完成,可以得知,异步IO模型采用的就是Proactor模式。
实战Reactor模式
以搭建一个服务器为例子
- 经典Reactor模式
- 多线程Reactor模式
经典Reactor模式
经典的Reactor模式示意图如下所示。
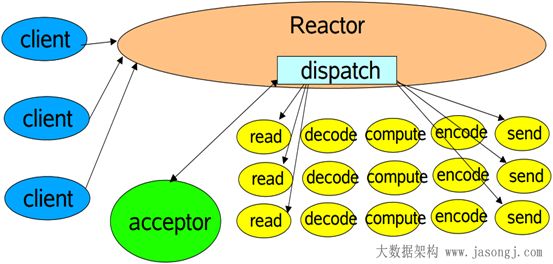
在Reactor模式中,包含如下角色
- Reactor 将I/O事件发派给对应的Handler
- Acceptor 处理客户端连接请求
- Handlers 执行非阻塞读/写
最简单的Reactor模式实现代码如下所示。
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel
= ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.bind(new InetSocketAddress(1234));
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (selector.select() > 0) {
Set keys = selector.selectedKeys();
Iterator iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
ServerSocketChannel acceptServerSocketChannel
= (ServerSocketChannel) key.channel();
SocketChannel socketChannel =
acceptServerSocketChannel.accept();
System.out.println("Accept request from " + socketChannel.getRemoteAddress());
socketChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int count = socketChannel.read(buffer);
if (count <= 0) {
socketChannel.close();
key.cancel();
System.out.println("Received invalid data, close the connection");
continue;
}
}
keys.remove(key);
}
}
} 为了方便阅读,上示代码将Reactor模式中的所有角色放在了一个类中。
从上示代码中可以看到,多个Channel可以注册到同一个Selector对象上,实现了一个线程同时监控多个请求状态(Channel)。同时注册时需要指定它所关注的事件,例如上示代码中socketServerChannel对象只注册了OP_ACCEPT事件,而socketChannel对象只注册了OP_READ事件。
selector.select()是阻塞的,当有至少一个通道可用时该方法返回可用通道个数。同时该方法只捕获Channel注册时指定的所关注的事件。
多工作线程Reactor模式
经典Reactor模式中,尽管一个线程可同时监控多个请求(Channel),但是所有读/写请求以及对新连接请求的处理都在同一个线程中处理,无法充分利用多CPU的优势,同时读/写操作也会阻塞对新连接请求的处理。因此可以引入多线程,并行处理多个读/写操作,如下图所示。
Netty中使用的Reactor模式,引入了多Reactor,也即一个主Reactor负责监控所有的连接请求,多个子Reactor负责监控并处理读/写请求,减轻了主Reactor的压力,降低了主Reactor压力太大而造成的延迟。
并且每个子Reactor分别属于一个独立的线程,每个成功连接后的Channel的所有操作由同一个线程处理。这样保证了同一请求的所有状态和上下文在同一个线程中,避免了不必要的上下文切换,同时也方便了监控请求响应状态。
多线程Reactor模式示例代码如下所示。
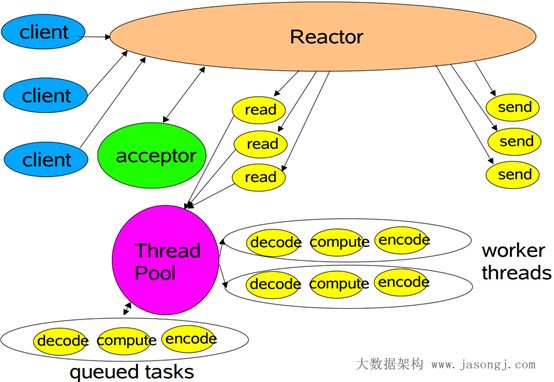
多线程Reactor代码:
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel =
ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.bind(new InetSocketAddress(1234));
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
if (selector.selectNow() < 0) {
continue;
}
Set keys = selector.selectedKeys();
Iterator iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
ServerSocketChannel acceptServerSocketChannel =
(ServerSocketChannel) key.channel();
SocketChannel socketChannel = acceptServerSocketChannel.accept();
socketChannel.configureBlocking(false);
System.out.println("Accept request from " + socketChannel.getRemoteAddress());
SelectionKey readKey = socketChannel.register(selector,
SelectionKey.OP_READ);
readKey.attach(new Processor());
} else if (key.isReadable()) {
Processor processor = (Processor) key.attachment();
processor.process(key);
}
}
}
} 从上示代码中可以看到,注册完SocketChannel的OP_READ事件后,可以对相应的SelectionKey attach一个对象(本例中attach了一个Processor对象,该对象处理读请求),并且在获取到可读事件后,可以取出该对象。
注:attach对象及取出该对象是NIO提供的一种操作,但该操作并非Reactor模式的必要操作,本文使用它,只是为了方便演示NIO的接口。
具体的读请求处理在如下所示的Processor类中。该类中设置了一个静态的线程池处理所有请求。而process方法并不直接处理I/O请求,而是把该I/O操作提交给上述线程池去处理,这样就充分利用了多线程的优势,同时将对新连接的处理和读/写操作的处理放在了不同的线程中,读/写操作不再阻塞对新连接请求的处理。
public class Processor {
private static final ExecutorService service =
Executors.newFixedThreadPool(16);
public void process(final SelectionKey selectionKey) {
service.submit(() -> {
ByteBuffer buffer = ByteBuffer.allocate(1024);
SocketChannel socketChannel = (SocketChannel) selectionKey.channel();
int count = socketChannel.read(buffer);
if (count < 0) {
socketChannel.close();
selectionKey.cancel();
System.out.println("Read ended" + socketChannel);
return null;
} else if (count == 0) {
return null;
}
return null;
});
}
}
参考:
http://wiki.jikexueyuan.com/project/java-nio-zh/java-nio-channel.html
https://www.cnblogs.com/dolphin0520/p/3919162.html
https://blog.csdn.net/u013096088/article/details/78638245
https://segmentfault.com/a/1190000006824196
https://www.hifreud.com/2017/04/18/java-nio-05-selector/