TensorFlow-深度学习-07-基于逻辑回归预测二元分类
现在我这里有一份数据集,数据量很少,只有不到200行,里面有0和1的标签,很适合做二分类,数据集如下:
LOW,AGE,LWT,RACE,SMOKE,PTL,HT,UI,BWT
1,28,113,1,1,1,0,1,709
1,29,130,0,0,0,0,1,1021
1,34,187,1,1,0,1,0,1135
1,25,105,1,0,1,1,0,1330
1,25,85,1,0,0,0,1,1474
1,27,150,1,0,0,0,0,1588
1,23,97,1,0,0,0,1,1588
1,24,128,1,0,1,0,0,1701
1,24,132,1,0,0,1,0,1729
1,21,165,0,1,0,1,0,1790
1,32,105,1,1,0,0,0,1818
1,19,91,0,1,1,0,1,1885
1,25,115,1,0,0,0,0,1893
1,16,130,1,0,0,0,0,1899
1,25,92,0,1,0,0,0,1928
1,20,150,0,1,0,0,0,1928
1,21,190,1,0,0,0,1,1928
1,24,155,0,1,1,0,0,1936
1,21,103,1,0,0,0,0,1970
1,20,125,1,0,0,0,1,2055
1,25,89,1,0,1,0,0,2055
1,19,102,0,0,0,0,0,2082
1,19,112,0,1,0,0,1,2084
1,26,117,0,1,1,0,1,2084
1,24,138,0,0,0,0,0,2100
1,17,130,1,1,1,0,1,2125
1,20,120,1,1,0,0,0,2126
1,22,130,0,1,1,0,1,2187
1,27,130,1,0,0,0,1,2187
1,20,80,1,1,0,0,1,2211
1,17,110,0,1,0,0,0,2225
1,25,105,1,0,1,0,0,2240
1,20,109,1,0,0,0,0,2240
1,18,148,1,0,0,0,0,2282
1,18,110,1,1,1,0,0,2296
1,20,121,0,1,1,0,1,2296
1,21,100,1,0,1,0,0,2301
1,26,96,1,0,0,0,0,2325
1,31,102,0,1,1,0,0,2353
1,15,110,0,0,0,0,0,2353
1,23,187,1,1,0,0,0,2367
1,20,122,1,1,1,0,0,2381
1,24,105,1,1,0,0,0,2381
1,15,115,1,0,0,0,1,2381
1,23,120,1,0,0,0,0,2395
1,30,142,0,1,1,0,0,2410
1,22,130,0,1,0,0,0,2410
1,17,120,0,1,0,0,0,2414
1,23,110,0,1,1,0,0,2424
1,17,120,1,0,0,0,0,2438
1,26,154,1,0,1,1,0,2442
1,20,105,1,0,0,0,0,2450
1,26,168,0,1,0,0,0,2466
1,14,101,1,1,1,0,0,2466
1,28,95,0,1,0,0,0,2466
1,14,100,1,0,0,0,0,2495
1,23,94,1,1,0,0,0,2495
1,17,142,1,0,0,1,0,2495
1,21,130,0,1,0,1,0,2495
0,19,182,1,0,0,0,1,2523
0,33,155,1,0,0,0,0,2551
0,20,105,0,1,0,0,0,2557
0,21,108,0,1,0,0,1,2594
0,18,107,0,1,0,0,1,2600
0,21,124,1,0,0,0,0,2622
0,22,118,0,0,0,0,0,2637
0,17,103,1,0,0,0,0,2637
0,29,123,0,1,0,0,0,2663
0,26,113,0,1,0,0,0,2665
0,19,95,1,0,0,0,0,2722
0,19,150,1,0,0,0,0,2733
0,22,95,1,0,0,1,0,2750
0,30,107,1,0,1,0,1,2750
0,18,100,0,1,0,0,0,2769
0,18,100,1,1,0,0,0,2769
0,15,98,1,0,0,0,0,2778
0,25,118,0,1,0,0,0,2782
0,20,120,1,0,0,0,1,2807
0,28,120,0,1,0,0,0,2821
0,32,121,1,0,0,0,0,2835
0,31,100,0,0,0,0,1,2835
0,36,202,0,0,0,0,0,2836
0,28,120,1,0,0,0,0,2863
0,25,120,1,0,0,0,1,2877
0,28,167,0,0,0,0,0,2877
0,17,122,0,1,0,0,0,2906
0,29,150,0,0,0,0,0,2920
0,26,168,1,1,0,0,0,2920
0,17,113,1,0,0,0,0,2920
0,17,113,1,0,0,0,0,2920
0,24,90,0,1,1,0,0,2948
0,35,121,1,1,1,1,0,2948
0,25,155,0,1,1,0,0,2977
0,25,125,1,0,0,0,0,2977
0,29,140,0,1,0,0,0,2977
0,19,138,0,1,0,1,0,2977
0,27,124,0,1,0,0,0,2992
0,31,115,0,1,0,0,0,3005
0,33,109,0,1,0,0,0,3033
0,21,185,1,1,0,0,0,3042
0,19,189,0,0,0,0,0,3062
0,23,130,1,0,0,0,0,3062
0,21,160,0,0,0,0,0,3062
0,18,90,0,1,0,0,1,3076
0,18,90,0,1,0,0,1,3076
0,32,132,0,0,0,0,0,3080
0,19,132,1,0,0,0,0,3090
0,24,115,0,0,0,0,0,3090
0,22,85,1,1,0,0,0,3090
0,22,120,0,0,0,1,0,3100
0,23,128,1,0,0,0,0,3104
0,22,130,0,1,0,0,0,3132
0,30,95,0,1,0,0,0,3147
0,19,115,1,0,0,0,0,3175
0,16,110,1,0,0,0,0,3175
0,21,110,1,1,0,0,1,3203
0,30,153,1,0,0,0,0,3203
0,20,103,1,0,0,0,0,3203
0,17,119,1,0,0,0,0,3225
0,17,119,1,0,0,0,0,3225
0,23,119,1,0,0,0,0,3232
0,24,110,1,0,0,0,0,3232
0,28,140,0,0,0,0,0,3234
0,26,133,1,1,0,0,0,3260
0,20,169,1,0,1,0,1,3274
0,24,115,1,0,0,0,0,3274
0,28,250,1,1,0,0,0,3303
0,20,141,0,0,0,0,1,3317
0,22,158,1,0,1,0,0,3317
0,22,112,0,1,1,0,0,3317
0,31,150,1,1,0,0,0,3321
0,23,115,1,1,0,0,0,3331
0,16,112,1,0,0,0,0,3374
0,16,135,0,1,0,0,0,3374
0,18,229,1,0,0,0,0,3402
0,25,140,0,0,0,0,0,3416
0,32,134,0,1,1,0,0,3430
0,20,121,1,1,0,0,0,3444
0,23,190,0,0,0,0,0,3459
0,22,131,0,0,0,0,0,3460
0,32,170,0,0,0,0,0,3473
0,30,110,1,0,0,0,0,3475
0,20,127,1,0,0,0,0,3487
0,23,123,1,0,0,0,0,3544
0,17,120,1,1,0,0,0,3572
0,19,105,1,0,0,0,0,3572
0,23,130,0,0,0,0,0,3586
0,36,175,0,0,0,0,0,3600
0,22,125,0,0,0,0,0,3614
0,24,133,0,0,0,0,0,3614
0,21,134,1,0,0,0,0,3629
0,19,235,0,1,0,1,0,3629
0,25,200,0,0,1,0,1,3637
0,16,135,0,1,0,0,0,3643
0,29,135,0,0,0,0,0,3651
0,29,154,0,0,0,0,0,3651
0,19,147,0,1,0,0,0,3651
0,19,147,0,1,0,0,0,3651
0,30,137,0,0,0,0,0,3699
0,24,110,0,0,0,0,0,3728
0,19,184,0,1,0,1,0,3756
0,24,110,0,0,1,0,0,3770
0,23,110,0,0,0,0,0,3770
0,20,120,1,0,0,0,0,3770
0,25,141,0,0,0,1,0,3790
0,30,112,0,0,0,0,0,3799
0,22,169,0,0,0,0,0,3827
0,18,120,0,1,0,0,0,3856
0,16,170,1,0,0,0,0,3860
0,32,186,0,0,0,0,0,3860
0,18,120,1,0,0,0,0,3884
0,29,130,0,1,0,0,0,3884
0,33,117,0,0,0,0,1,3912
0,20,170,0,1,0,0,0,3940
0,28,134,1,0,0,0,0,3941
0,14,135,0,0,1,0,0,3941
0,28,130,1,0,0,0,0,3969
0,25,120,0,0,0,0,0,3983
0,16,135,1,0,0,0,0,3997
0,20,158,0,0,0,0,0,3997
0,26,160,0,0,0,0,0,4054
0,21,115,0,0,0,0,0,4054
0,22,129,0,0,0,0,0,4111
0,25,130,0,0,0,0,0,4153
0,31,120,0,0,0,0,0,4167
0,35,170,0,0,1,0,0,4174
0,19,120,0,1,0,1,0,4238
0,24,216,0,0,0,0,0,4593
0,45,123,0,0,1,0,0,4990
可以把它复制下来存成excel或txt或csv,利用pandas读取。这是一份公开数据集,一个人的恶习指标对下一代出生婴儿的影响,无影响表示0,有影响表示1,即标签列,为数据集中的“LOW”列。
下面将使用简单的逻辑回归进行数据训练与预测:
1、读取数据集及各列:
data = pd.read_csv("Logistic_data.csv")
y_labels = np.array(data.iloc[:, data.columns == "LOW"])
x_data = np.array(data.iloc[:, data.columns != "LOW"].astype(float)) # 去除LOW列
2、划分训练集与测试集(比例大概为8:2)
np.random.seed(99) # 每次生成的随机数都相同
tf.set_random_seed(99)
train_indeces = np.random.choice(len(x_data), round(len(x_data) * 0.8), replace=False) # replace=False不能有重复
test_indeces = np.array(list(set(range(len(x_data))) - set(train_indeces))) # 剩余的数据
# 训练集
x_train = x_data[train_indeces]
x_test = x_data[test_indeces]
y_train = y_labels[train_indeces]
y_test = y_labels[test_indeces]
3、数据归一化(防止某列部分数据过小而被某列大数据吃掉)
def normalization(data):
cmax = data.max(axis=0)
cmin = data.min(axis=0)
return (data - cmin) / (cmax - cmin)
x_train = np.nan_to_num(normalization(x_train))
x_test = np.nan_to_num(normalization(x_test))
4、梯度下降设置
x_input = tf.placeholder(shape=[None, 8], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
W = tf.Variable(tf.random_normal([8, 1]))
b = tf.Variable(tf.random_normal([1, 1]))
model = tf.add(tf.matmul(x_input, W), b)
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y_target, logits=model)) #交叉熵损失函数,不需要使用sigmod()
optimizer = tf.train.GradientDescentOptimizer(0.05) #梯度下降优化器
step = optimizer.minimize(loss)
5、喂数据并训练
batch_size=50
# train stage
for i in range(8000):
rand_index=np.random.choice(len(x_train),size=batch_size,replace=False)
rand_x=x_train[rand_index]
rand_y=y_train[rand_index]
sess.run(step,feed_dict={x_input:rand_x,y_target:rand_y})
temp_loss,curr_acc_train = sess.run([loss,accuary], feed_dict={x_input:rand_x,y_target:rand_y})
curr_acc_test = sess.run(accuary,feed_dict={x_input: x_test, y_target: np.transpose(y_test).reshape(len(x_test), 1)})
acc_test.append(curr_acc_test)
acc_train.append(curr_acc_train)
loss_value.append(temp_loss)
if (i+1)%800==0:
print("训练集准确率:",(curr_acc_train*100),"%","测试集准确率:",(curr_acc_test*100),"%","损失值:",temp_loss)
6、绘制loss损失值图像与准确率图像(可以忽略)
'''-----loss值绘图-------'''
plt.plot(loss_value,'k--')
plt.title("loss function")
plt.xlabel("Generation")
plt.ylabel("Cross entry")
plt.show()
'''----准确率绘图-------'''
plt.plot(acc_train, 'b--',label="train accuary")
plt.plot(acc_test, 'g--',label="test accuary")
plt.title("accuary")
plt.xlabel("Generation")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
完整代码:
import tensorflow as tf
import pandas as pd
import numpy as np
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
data = pd.read_csv("Logistic_data.csv")
# print(data.head()
'''-------------取出标签列和参数行--------------'''
y_labels = np.array(data.iloc[:, data.columns == "LOW"])
x_data = np.array(data.iloc[:, data.columns != "LOW"].astype(float)) # 去除LOW列
'''-------------训练集和测试集划分---------------'''
np.random.seed(99) # 每次生成的随机数都相同
tf.set_random_seed(99)
train_indeces = np.random.choice(len(x_data), round(len(x_data) * 0.8), replace=False) # replace=False不能有重复
test_indeces = np.array(list(set(range(len(x_data))) - set(train_indeces))) # 剩余的数据
# 训练集
x_train = x_data[train_indeces]
x_test = x_data[test_indeces]
y_train = y_labels[train_indeces]
y_test = y_labels[test_indeces]
def normalization(data):
cmax = data.max(axis=0)
cmin = data.min(axis=0)
return (data - cmin) / (cmax - cmin)
x_train = np.nan_to_num(normalization(x_train))
x_test = np.nan_to_num(normalization(x_test))
x_input = tf.placeholder(shape=[None, 8], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
W = tf.Variable(tf.random_normal([8, 1]))
b = tf.Variable(tf.random_normal([1, 1]))
model = tf.add(tf.matmul(x_input, W), b)
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y_target, logits=model)) #交叉熵损失函数,不需要使用sigmod()
optimizer = tf.train.GradientDescentOptimizer(0.05) #梯度下降优化器
step = optimizer.minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
acc_train=[]
acc_test=[]
loss_value=[]
sess.run(init)
predicts = tf.round(tf.sigmoid(model))
correction = tf.cast(tf.equal(predicts, y_target), tf.float32)
accuary = tf.reduce_mean(correction)
batch_size=50
# train stage
for i in range(8000):
rand_index=np.random.choice(len(x_train),size=batch_size,replace=False)
rand_x=x_train[rand_index]
rand_y=y_train[rand_index]
sess.run(step,feed_dict={x_input:rand_x,y_target:rand_y})
temp_loss,curr_acc_train = sess.run([loss,accuary], feed_dict={x_input:rand_x,y_target:rand_y})
curr_acc_test = sess.run(accuary,feed_dict={x_input: x_test, y_target: np.transpose(y_test).reshape(len(x_test), 1)})
acc_test.append(curr_acc_test)
acc_train.append(curr_acc_train)
loss_value.append(temp_loss)
if (i+1)%800==0:
print("训练集准确率:",(curr_acc_train*100),"%","测试集准确率:",(curr_acc_test*100),"%","损失值:",temp_loss)
'''-----loss值绘图-------'''
plt.plot(loss_value,'k--')
plt.title("loss function")
plt.xlabel("Generation")
plt.ylabel("Cross entry")
plt.show()
'''----准确率绘图-------'''
plt.plot(acc_train, 'b--',label="train accuary")
plt.plot(acc_test, 'g--',label="test accuary")
plt.title("accuary")
plt.xlabel("Generation")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
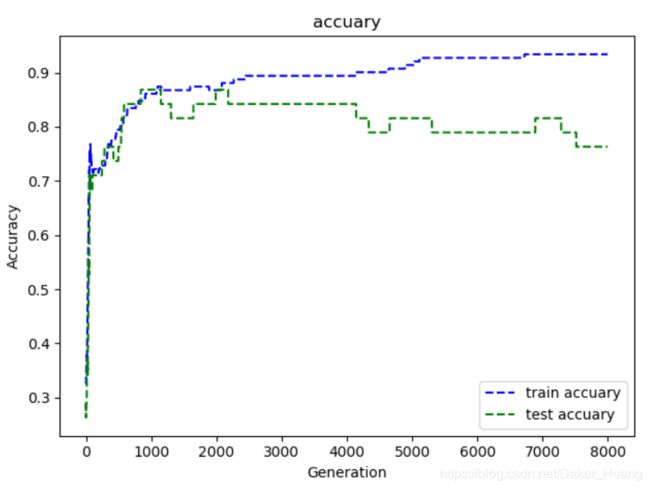
结果:
图像:
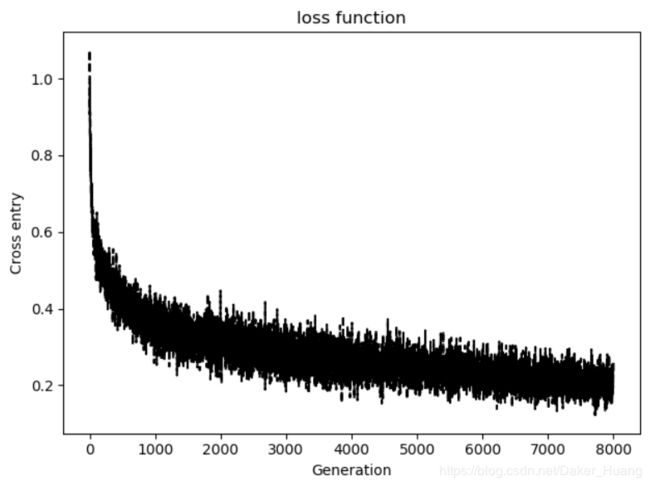
调整代码,我们不设值batch_size,如果把数据一次性喂给网络进行训练,loss值效果可能还会更好,但是速度可能慢点:
import tensorflow as tf
import pandas as pd
import numpy as np
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
data = pd.read_csv("Logistic_data.csv")
# print(data.head()
'''-------------取出标签列和参数行--------------'''
y_labels = np.array(data.iloc[:, data.columns == "LOW"])
x_data = np.array(data.iloc[:, data.columns != "LOW"].astype(float)) # 去除LOW列
'''-------------训练集和测试集划分---------------'''
np.random.seed(99) # 每次生成的随机数都相同
tf.set_random_seed(99)
train_indeces = np.random.choice(len(x_data), round(len(x_data) * 0.8), replace=False) # replace=False不能有重复
test_indeces = np.array(list(set(range(len(x_data))) - set(train_indeces))) # 剩余的数据
# 训练集
x_train = x_data[train_indeces]
x_test = x_data[test_indeces]
y_train = y_labels[train_indeces]
y_test = y_labels[test_indeces]
def normalization(data):
cmax = data.max(axis=0)
cmin = data.min(axis=0)
return (data - cmin) / (cmax - cmin)
x_train = np.nan_to_num(normalization(x_train))
x_test = np.nan_to_num(normalization(x_test))
x_input = tf.placeholder(shape=[None, 8], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
W = tf.Variable(tf.random_normal([8, 1]))
b = tf.Variable(tf.random_normal([1, 1]))
model = tf.add(tf.matmul(x_input, W), b)
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y_target, logits=model)) #交叉熵损失函数,不需要使用sigmod()
optimizer = tf.train.GradientDescentOptimizer(0.05) #梯度下降优化器
step = optimizer.minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
acc_train=[]
acc_test=[]
loss_value=[]
sess.run(init)
predicts = tf.round(tf.sigmoid(model))
correction = tf.cast(tf.equal(predicts, y_target), tf.float32)
accuary = tf.reduce_mean(correction)
batch_size=50
# train stage
for i in range(8000):
rand_index=np.random.choice(len(x_train),size=batch_size,replace=False)
rand_x=x_train[rand_index]
rand_y=y_train[rand_index]
sess.run(step,feed_dict={x_input:x_train,y_target:y_train})
temp_loss,curr_acc_train = sess.run([loss,accuary], feed_dict={x_input:x_train,y_target:y_train})
curr_acc_test = sess.run(accuary,feed_dict={x_input: x_test, y_target: np.transpose(y_test).reshape(len(x_test), 1)})
acc_test.append(curr_acc_test)
acc_train.append(curr_acc_train)
loss_value.append(temp_loss)
if (i+1)%800==0:
print("训练集准确率:",(curr_acc_train*100),"%","测试集准确率:",(curr_acc_test*100),"%","损失值:",temp_loss)
'''-----loss值绘图-------'''
plt.plot(loss_value,'k--')
plt.title("loss function")
plt.xlabel("Generation")
plt.ylabel("Cross entry")
plt.show()
'''----准确率绘图-------'''
plt.plot(acc_train, 'b--',label="train accuary")
plt.plot(acc_test, 'g--',label="test accuary")
plt.title("accuary")
plt.xlabel("Generation")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
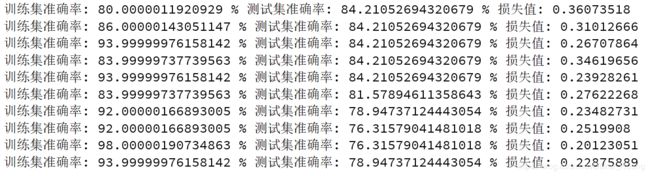
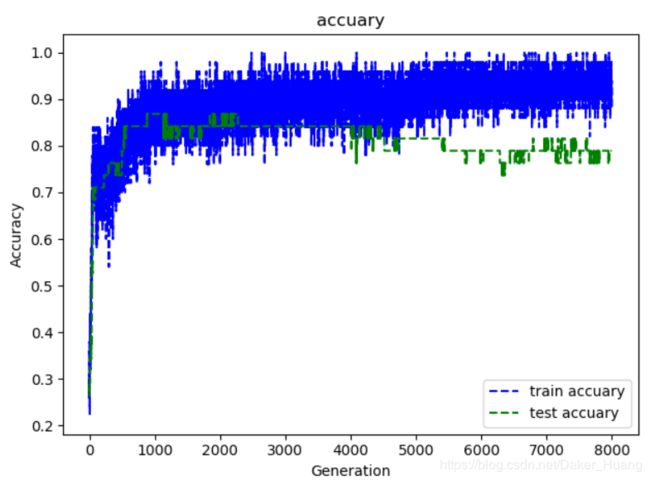
运行结果:

图像: