基于CDH版本5.13.3实现原生版Spark集群及问题记录
基于CDH版本5.13.3实现Spark集群
1. 安装背景
由于部门及已上项目使用的是CDH版本大数据平台,为了充分更好使用Spark集群Spark引擎运算,解决基于CDH版本下可支持3种大数据运算分析方式Hive on MR、Hive on Spark和Spark Sql。
2. 安装环境
2.1. 硬件规划
CPU |
物理内存 |
磁盘存储 |
节点 |
1核X2颗 Intel Core Processor 2295MHZ (Haswell, no TSX) |
8GB |
80G |
192.17.10.136 |
1核X2颗 Intel Core Processor 2295MHZ (Haswell, no TSX) |
8GB |
80G |
192.17.10.138 |
1核X2颗 Intel Core Processor 2295MHZ (Haswell, no TSX) |
8GB |
80G |
192.17.10.139 |
2.2. 软件规划
类别 |
软件清单 |
备注 |
操作系统 |
CentOS Linux release 77.2.1511 |
|
大数据平台 |
CDH5.13.1 Hadoop2.6.0 Spark1.6.0 Java1.7.0.9 MySql 5.7.21 Hive:1.1.0 Scala2.10.5 HBase HDFS … |
|
2.3. 目录规划
l 原生Spark安装目录:/opt/cdh5/spark-1.6.0
l CDH相关安装目录:/opt/cloudera/parcels/CDH
l MySql安装目录:
/usr/bin/mysql
/usr/lib64/mysql
/usr/share/mysql
/usr/share/man/man1/mysql.1.gz
3. 安装步骤
3.1. 环境配置
由于本次是基于已有CDH环境下,增加安装原生版本Spark安装,所以操作所需要的:
免密配置、防火墙、主机名配置、主机与IP静态绑定、修改vm.swappiness参数、Oracle JDK1.7和Mysql安装配置等都已完成了,所以本次安装只需安装配置原生Spark即可。
3.2. 介质准备
l Spark1.6.0介质提供有源码和预编译好的两种,本次我选择的是用后者。
下载地址链接:
http://archive.apache.org/dist/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
l 如果选择是源码编译方式,则需要下载Maven3.3.3以上版本以及需要保证编译节点服务器可联公网。
下载Maven链接:
http://archive.apache.org/dist/maven/maven-3/3.3.3/binaries/apache-maven-3.3.3-bin.tar.gz
注:统一下载在/opt目录
3.3. Spark安装
1、 创建目录
mkdir -p /opt/cdh5
mkdir –p /opt/service/maven3.3.3
2、 解压介质
sudo tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz
mv spark-1.6.0-bin-hadoop2.6 /opt/cdh5/spark-1.6.0
sudo chown -R root:root spark-1.6.0
sudo tar -zxvf apache-maven-3.3.3-bin.tar.gz
mv apache-maven-3.3.3 /opt/service/maven3.3.3/
sudo chown -R root:root apache-maven-3.3.3
sudo tar -zxvf scala-2.10.7.tgz
mv scala-2.10.7 /opt/
sudo chown -R root:root scala-2.10.7
3、 配置环境变量
1)、vi /etc/profile添加如下内容
#MAVEN
exportMAVEN_HOME=/opt/service/maven-3.3.3/apache-maven-3.3.3
exportPATH=$MAVEN_HOME/bin:$PATH
#scala
exportSCALA_HOME=/opt/scala-2.10.7
exportPATH=$SCALA_HOME/bin:$PATH
2)、vi /opt/cdh5/spark-1.6.0/conf/spark-env.sh文件
因原生版本spark下配置文件安装后没有spark-env.sh文件,需要从模板文件复制一个出来,即:cp spark-env.sh.template spark-env.sh
添加如下内容:
export JAVA_HOME=/usr/java/jdk1.7.0_79
export SCALA_HOME=/opt/scala-2.10.7
export HADOOP_CONF_DIR=/etc/hadoop/conf
exportHADOOP_HOME=/opt/cloudera/parcels/CDH-5.13.3-1.cdh5.13.3.p0.2/lib/hadoop
export SPARK_HOME=/opt/cdh5/spark-1.6.0
exportHIVE_HOME=/opt/cloudera/parcels/CDH-5.13.3-1.cdh5.13.3.p0.2/lib/hive
exportHBASE_HOME=/opt/cloudera/parcels/CDH-5.13.3-1.cdh5.13.3.p0.2/lib/hbase
exportZOOKEEPER_HOME=/opt/cloudera/parcels/CDH-5.13.3-1.cdh5.13.3.p0.2/lib/zookeeper
export SPARK_MASTER_IP=192.17.10.136
exportSPARK_MASTER_PORT=7099
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=2g
#export SPARK_EXECUTOR_MEMORY=128M
#export SPARK_DRIVER_MEMORY=4096M
export SPARK_WORKER_PORT=7098
export SPARK_WORKER_WEBUI_PORT=8091
export SPARK_WORKER_INSTANCES=2
exportSPARK_WORKER_DIR=/opt/cdh5/spark-1.6.0/data/tmp
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export JRE_HOME=$JAVA_HOME/jre
exportCLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_LIBRARY_PATH/lib:$HADOOP_HOME/lib:$HBASE_HOME/lib:$HIVE_HOME/lib:$SCALA_HOME/lib:$SPARK_HOME/lib:$ZOOKEEPER_HOME/lib:$SCALA_HOME/lib:$SPARK_HOME/lib:$JRE_HOME/lib
注意端口,需重新定义标红部分项的默认端口,确保与已存在CDH的spark所用端口不冲突。
3)、配置spark-defaults.conf文件:不配置此选项运行spark服务还是在local模式下运行。
因原生版本spark下配置文件安装后没有spark-defaults.conf文件,需要从模板文件复制一个出来,即:cp spark-defaults.conf.template spark-defaults.conf
添加spark.master spark://192.17.10.136:7099
注意:此端口需要和spark-env.sh中参数项SPARK_MASTER_PORT=7099一致。
4)、编辑slaves文件,添加slaves节点
cct-bigdata-2
cct-bigdata-3
此处可用主机名或IP地址都可。
4、 相关文件配置
因需要访问hive,所以需要把hive-site.xml文件复制到spark安装目录下使用。即:
scp -r /opt/cloudera/parcels/CDH/lib/hive/conf/hive-site.xmlroot@ cct-bigdata-1:/opt/cdh5/spark-1.6.0/conf
此处还需添加,如配置为空或不添加会导致hive的程序使用了NULL而非空字符串做密码,但我们的登录hive元数据库设置了密码。
同理还需复制访问Mysql的驱动jar包,否则访问时会异常。即找到已下载好的jar包:
scp /opt/mysql/mysql-connector-java-5.1.45-bin.jar root@cct-bigdata-1:/opt/cdh5/spark-1.6.0/lib
5、 同步到其它节点
scp -r /opt/cdh5/spark-1.6.0/ root@ cct-bigdata-2:/opt/cdh5/
scp -r /opt/cdh5/spark-1.6.0/ root@ cct-bigdata-3:/opt/cdh5/
6、 启动&关闭Spark集群
启动服务
sbin/start-master.sh
sbin/start-slaves.sh
或sbin/start-all.sh
启动正常日志会显示为:
登录到web页面查看:
关闭服务
sbin/stop-all.sh
7、 重启Hive
登录到CM下,找到hive服务,点击重启即可。
如hive未重启,则会在执行spark-shell或spark-sql报
3.4. 启动验证
l 启动./bin/Spark-shell,正常情况下应该是类似如下截图:
在scala语言验证可否正常连接hive仓库:
scala>sqlContext.sql("use default")
scala>sqlContext.sql("show tables").take(10)
scala>sqlContext.sql("show tables").collect().foreach(println)
scala> sqlContext.sql("select * fromword").collect().foreach(println)
18/06/2816:58:29 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose taskshave all completed, from pool
[1,word100]
[2,word200]
[9,word900]
[10,word1000]
[11,word1100]
[11,word1100]
[11,word1100-mr]
[11,word1100-2]
[11,word1100-spa1]
[11,word1100-sp3]
[3,word300]
[3,word300]
[3,word300]
[4,word400]
[5,word500]
[6,word600]
[7,word700]
[8,word800]
l 启动./bin/Spark-sql,正常情况下应该是类似如下截图:
在spark-sql CL可否正常连接hive仓库:
spark-sql>select * from word;
18/06/2817:03:57 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose taskshave all completed, from pool
1 word100
2 word200
9 word900
10 word1000
11 word1100
11 word1100
11 word1100-mr
11 word1100-2
11 word1100-spa1
11 word1100-sp3
3 word300
3 word300
3 word300
4 word400
5 word500
6 word600
7 word700
8 word800
18/06/2817:03:57 INFO CliDriver: Time taken: 5.527 seconds, Fetched 18 row(s)
spark-sql> select count(*) from word;
4. 处理问题
安装过程中需注意下面几个问题:
1)、内存配置
原因是:
上述三项内存配置不对所致,后来经过多次尝试修正,最终改正为:
2)、不能访问hive metastore
此类问题后来经过分析排查,发现由于下面服务、配置有异常、hive-site.xml和访问mysql驱动包cp到spark下的lib目录,就会导致spark-shell或spark-sql启动失败。
注意检查:
spark里面hive-site.xml配置hive.metastore.uris有没有,如截图:
hive的metastore服务开启没有;
hive的thrift服务;
在CDH版本下,spark全部配置部署完成后,务必需要重启hive服务。这样确保spark下相关hive配置生效。
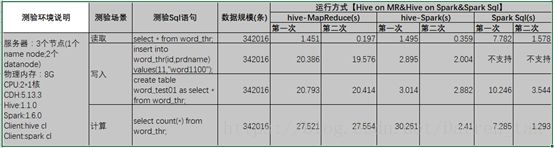
5. 性能验证
5.1. 测验报告