概率分布 Probability Distributions
在机器学习领域,概率分布对于数据的认识有着非常重要的作用。不管是有效数据还是噪声数据,如果知道了数据的分布,那么在数据建模过程中会得到很大的启示。本文总结了几种常见的概率分布,比如离散型随机变量的分布代表伯努利分布以及连续型随机变量的分布代表高斯分布。对于每种分布,不仅给出它的概率密度函数,还会对其期望和方差等几个主要的统计量进行分析。目前文章的内容还比较简洁,后续再不断进行完善。
本文主要从三个方面进行阐述:
- 一个函数:Gamma函数
- 六大分布:伯努利分布、二项分布、多项式分布、Beta分布、Dirichlet分布、高斯分布
- 一个理论:共轭先验
一个函数:Gamma函数
Gamma函数是阶乘在实数上的推广,其公式如下:
Gamma函数有着一个特别的性质,即:
六大分布
伯努利分布
伯努利分布(Bernoulli distribution)是关于布尔变量 xϵ{0,1} 的概率分布,其连续参数 μϵ[0,1] 表示变量 x=1 的概率。其概率分布可以写成如下形式:
对于伯努利分布,它的期望和方差如下:
二项分布
二项分布(binomial distribution)描述的是 n 次独立的伯努利分布中有 m 次成功(即 x=1 )的概率,其中每次伯努利实验成功的概率都是 μϵ[0,1] .
对于二项分布,它是伯努利分布的推广,而对于独立事件,加和的均值等于均值的加和,加和的方差等于方差的加和。因此其期望和方差如下:
当 n=1 时,二项分布退化为伯努利分布.
多项式分布
将伯努利分布的单变量扩展到 d 维向量 x⃗ ,其中 xiϵ{0,1} ,且 ∑di=1xi=1 ,假设 xi=1 的概率为 μϵ[0,1] ,
并且 ∑di=1μi=1 ,则将得到离散分布
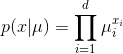
在此基础上扩展二项分布得到多项式分布(multinomial distribution),该分布描述的是在 n 次独立实验中有 mi 次 xi=1 的概率,其密度函数可以表达为如下形式:
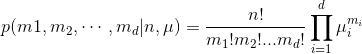
多项式分布的期望、方差、协方差如下:
Beta分布
Beta分布是二项分布的共轭先验分布,下面先介绍两个函数,Beta函数和Gamma函数(直接贴公式吧):
贝塔分布(Beta distribution)是关于连续变量 μϵ[0,1] 的概率分布,它由两个参数 a 和 b 共同确定,概率密度函数如下:
Beta分布的期望和方差如下:
狄利克雷分布
狄利克雷分布(Dirichlet distribution)是Beta分布在高维度上的推广,它是关于一组 d 个连续变量 μiϵ[0,1] 的概率分布.
令 μ=(μi,μ2,...,μd) , 其中参数为:

则狄利克雷分布的概率密度函数为:
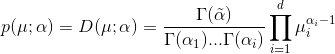
Dirichlet 分布的期望和方差如下:
![]()
![]()
![]()
当 d=2 时,狄利克雷分布退化为Beta分布.
高斯分布
高斯分布又称正态分布,在实际应用中最为广泛。对于单变量 xϵ(−∞,+∞) ,高斯分布的参数有两个,分别是均值 μϵ(−∞,+∞) 和方差 σ2>0 ,其概率密度函数为
期望方差如下:
对于D维向量 x ,多元高斯分布的概率密度函数为:
其中, µ 是 D 维均值向量, Σ 是 D×D 的协方差矩阵, |Σ| 是 Σ 的行列式。多元高斯分布的期望为 μ , 方差为 Σ .
共轭先验
先验分布反映了某种先验信息,后验分布既反映了先验分布提供的信息,又反映了样本提供的信息。若先验分布和抽样分布决定的后验分布与先验分布是同类型分布,则称先验分布为抽样分布的共轭分布。当先验分布与抽样分布共轭时,后验分布与先验分布属于同一种类型,这意味着先验信息和样本信息提供的信息具有一定的同一性。
- Beta的共轭分布是伯努利分布;
- 多项式分布的共轭分布是狄利克雷分布;
- 高斯分布的共轭分布是高斯分布。
参考文献
- special distribution
- Gamma distribution
- Beta distribution