谷歌Cloud AutoML自动机器学习平台初步研究
一、AutoML背景
机器学习(Machine Learning, ML)技术近年来已取得较大成功,越来越多行业领域依赖它。但目前成功的关键还需依赖人类机器学习工程师完成以下工作:
- 预处理数据
- 选择适当的功能
- 选择适当的模型系列
- 优化模型超参数
- 后处理机器学习模型
- 严格分析所得的结果
以上工作的复杂性通常超过了非机器学习专家的能力,随着机器学习应用的快速增长对自动机器学习方法产生了需求。目前,世界上只有小部分企业拥有足够的人力财力资源充分发挥AI和机器学习的潜能,也只有小部分人有能力开发出先进的机器学习模型。但即使这样一小部分拥有AI专家的企业,也仍需大量时间且反复过程才能构建出自定义的机器学习系统。
基于此现状,2017年5月,谷歌正式宣布AutoML研究项目成立;2017年10月,已实现部分超越研究人员成果的机器学习AI模型;2018年1月,谷歌已发布第一个产品,并将它作为云服务开放出来。服务地址如下:
https://cloud.google.com/automl/
二、AutoML定位
AutoML官方宣称适用对象是有想法有数据,但不知怎么用的企业或个人用户,使用AutoML就不需要再去招募大量的机器学习人才,也不需要花大量的时间去标注训练数据,就直接可以得到自己定制的东西。简而言之,AutoML能降低使用机器学习的门槛,让更多对机器学习了解有限的人,把Google级的AI技术运用到产品打磨中。更多懂行业、懂产品的人可以发挥自己已有的特长,就能让AI技术实现其行业和产品价值。
三、关于Cloud AutoML
产品介绍
2018年1月18日,Google Cloud AI首席科学家李飞飞连发三条Twitter,通过一篇博客文章发布了谷歌最新AI产品—AutoML,该产品可以自动设计机器学习模型,通过Google最先进的传输学习和神经架构搜索技术,帮助机器学习专业知识薄弱的企业或个人用户构建自己的高质量自定义模型;另一方面,Cloud AutoML能使AI专家们更加高效,帮助其构建更强大AI系统的同时,帮助其拓展新的领域。
使用AutoML时,就像使用一个工具,只需将训练数据集传入AutoML,AutoML将自动训练数据并形成自定义模型。
当前,Google发布了第一个产品AutoML Vision,并已将它作为云服务开放出来,提供了一种简单,安全和灵活的ML服务,可让用户为自己的数据训练自定义视觉模型。同时,谷歌也表示稍后会支持其他标准机器学习模型,包括语音、翻译、视频、自然语言处理等。
产品特点
作为谷歌产品,AutoMLVision具有以下三个特点:
l 更精准:Cloud AutoML Vision基于谷歌领先的图像识别方法,包括传输学习和神经架构搜索技术。这意味着即使企业不具备足够的机器学习专业知识,也可以获得更准确的模型。
l 更快:使用Cloud AutoML可以在几分钟内创建一个简单的模型,用以调试你想用AI支持的应用程序,可以在一天内构建能用于生产的完整模型。
l 操作简单:AutoML Vision提供了一个简单的图形用户界面,可让你指定数据,然后将数据转换为一个针对特定需求的高质量模型。
产品使用
Cloud AutoML Vision可以更快、更轻松地创建用于图像识别的自定义机器学习模型。凭借其拖放式界面可轻松上传图像,训练和管理模型,然后直接在GoogleCloud上部署这些训练的模型。使用者只需要将图片上传并点击训练,便能选择想要建立的定制化模型或是谷歌提供的模型。如果希望定制化模型,谷歌建议理想的情况是,每个标签至少要有100张训练图片。如果选择通过Vision API使用谷歌提供的模型,则只能标识一些常见的物件,像是脸部、标志、地标等。
谷歌Cloud AutoML Vision系统基于监督式学习,所以需要提供一系列带有标签的数据。具体来说,开发者只需要上传一组图片,然后导入标签或者通过App创建,随后谷歌的系统就会自动生成一个定制化的机器学习模型。整个过程,从导入数据到打标签到训练模型,所有的操作都是通过拖拽完成。在这个模型生成以及训练的过程中,除了训练样本时需要人工打标签外,其他的步骤就不需要人为的干预。据说,模型会在一天之内训练完成。
AutoML Vision提供了一个简单的图形用户界面(GUI),供用户根据自己的数据来训练,评估,改进和部署模型,只需花费几分钟时间。如下展示了一个对走廊,餐厅,客厅,厨房,卧室以及浴室共7类标签2880个图片的图片识别模型评估界面。

模型评估界面
下图是展示新图片在训练好的模型上做预测属于哪类标签,结果显示最大可能是75.85%属于厨房,具体如下:

模型预测界面
用户在训练模型时,如果不想自己打图片标签,可以使用Google提供的公共数据集的标签服务来标注,以确保用户的模型接受高质量数据训练。
费用说明
官方宣称免费试用,但从了解的信息来看,是根据模型训练时间多少来决定收费标准:
1、 1小时内免费;
2、 超过1小时到24小时最多收费$550;
四、AutoML技术原理介绍
使用技术
从技术层面来看,基于两个技术:
1.谷歌通过迁移学习(Transfer Learning)将已训练完成的模型,转移到新的模型训练过程。这样,能够用较少量数据训练出机器学习模型。迁移学习目标是将从一个环境中学到的知识用来帮助新环境中的学习任务,强调的是在不同但是相似的领域、任务、分布之间进行知识的迁移。虽然只拥有很少的数据,但谷歌用友很多类似的AI模型,所以通过迁移学习,谷歌可以将这两者结合起来,生成一个满足需求的AI模型。此外,谷歌还通过learning2learn功能自动挑选适合的模型,搭配超参数调整技术(Hyperparametertuning technologies)自动调整参数。
2.神经架构搜索(Neural Architecture Search),AutoML用的是增强学习(迭代)+RNN生成的方法,实际上针对的是CNN的网络结构,用深度学习调参来训练确定网络构架。增强学习中,不用告诉机器参数怎么设定,等它随机调整了一个参数后,如果结果是好的,那么给它奖励,如果结果不好,那么给它惩罚,但是不告诉它哪一步做错了,久而久之机器会自己摸索出一套最佳方案来。增强学习极大减少了数据的依赖,尤其是在规则明确的游戏当中,则更加适合增强学习发挥其强大的威力。
核心原理
AutoML由控制器(Controller)和子网络(Child)两个神经网络组成,控制器生成子模型架构,子模型架构执行特定的任务训练并评估模型的优劣反馈给控制器,控制器将会将此结果作为下一个循环修改的参考。重复执行数千次“设计新架构、评估、回馈、学习”的循环后,控制器能设计出最准确的模型架构,如图:

在这一过程中,搭建训练模型、调参等种种老大难题都能被自动解决,这也将GoogleCloud这一新服务与微软Azure ML的机器学习平台区分开。
未来发展
当前AutoML的简易架构如下图所示:
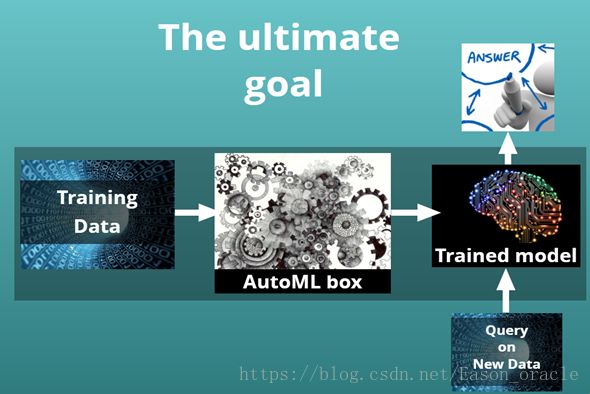
当前架构图
目前Cloud AutoML的核心模块在于AutoML Box,用户上传样本数据后,AutoML Box将适配适合的算法模型来训练用户数据,最终形成高精度的训练模型供用户使用。未来,AutoML通过新增的Crowd Intelligence模块,使得AutoML更加智能,行为更加类似人类大脑。未来架构如下图所示:
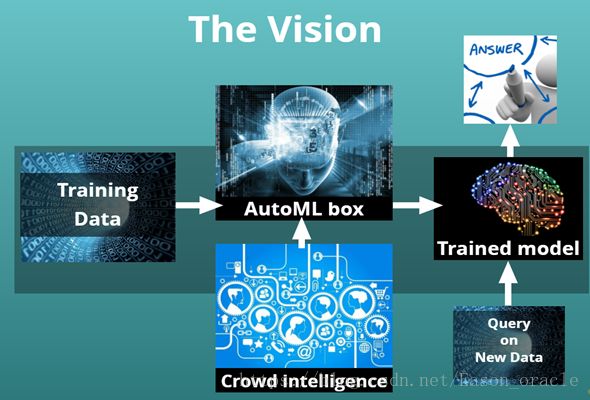
未来架构图
五、AutoML应用领域了解
截至目前,已有包括迪士尼、伦敦动物学会ZSL、服饰品牌Urban Outfitter在内的多家公司和组织试用了该服务,取得了业务突破。比如伦敦动物学学会用AutoML来识别野生动物,在垃圾检测方面,通过AutoML Vision识别所料瓶等花式使用,谷歌目前在医疗、教育等这样集中关切却又缺乏很好解决方案的领域做AI探究。
对于个人来说,你可以开发一个针对某一类物体识别的App,比如恐龙、蜘蛛等,你只需要事先使用AutoML Vision训练好模型,用户在你的App里上传恐龙图片将得到这是一只什么龙的答案:霸王龙还是什么龙。
下面分享一个毒蜘蛛分类使用案例,链接如下:
https://shinesolutions.com/2018/03/14/using-google-cloud-automl-vision-to-classify-poisonous-australian-spiders/amp/?__twitter_impression=true
六、AutoML与其他同类技术产品对比
谷歌此次声称AutoML是市面上唯一提供类似服务的产品,但诸如Clarif.ai这样的服务也已打出过类似的旗号,而微软的认知服务也能让你定制预先训练好的视觉、语音识别和决策模型(不过所有这些服务都还未被正式发布)。
通过使用机器学习云服务,你可以开始构建你的第一个工作模型,从相对较小的团队预测中来产出有价值的见解。市场上最好的机器学习平台:亚马逊机器学习服务、微软Azure机器学习和谷歌云AI这三个领先的云MLaaS服务(服务型导向的机器学习)。
在文本识别、翻译和文本分析方面的API比较:

微软提供了最丰富的功能列表,但是所有供应商都提供最重要的功能。
关于图像分析的比较如下图:

虽然图像分析与视频分析接口有许多交叉之处,但是许多视频工具仍在发展或处于良好的版本中。例如,谷歌对多种图像处理任务可提供许多支持,但是明显缺乏一些微软和亚马逊已能实现的视频分析特征功能。

微软看似是赢家,虽然我们仍认为亚马逊有最高效的视频分析接口,如亚马逊可支持流媒体处理。这个特征功能显然拓宽了视频分析技术的应用面。
图像和视频处理应用程序接口:亚马逊 Rekognition
我们绝对没有拼错单词。Rekognition应用程序接口是用于图像识别以及最近的视频识别任务。包括:
- 图像目标检测以及分类(发现并检测图像中的不同目标对象并且进行定位)
- 在视频中,该接口能检测一般活动(比如“跳舞”)或者复杂活动(如“扑火”)
- 面部识别 (用于检测面部并进行匹配) 以及面部分析(这个接口有些非常有意思的功能比如检测笑脸、分析眼睛,甚至看可以定义视频中的情感情绪
- 检测不合适的视频
- 识别图像和视频中的名人 (无论出于何种目的)
图像与视频处理应用程序接口: 微软 Azure 认知服务
微软的图像包结合了针对不同种类图像、视频和文本分析的六个应用程序接口
- 可识别目标对象、行为(如走路)以及定义图像主颜色特征的计算机视觉
- 可检测图像、文本、视频中不合适内容的内容评分机制
- 面部应用程序接口用于检测面部并集中检测结果,进行年龄、情绪、姿势、笑容和面部毛发的识别定义
- 情绪应用程序接口是可描绘面部表情的另一个面部识别工具
- 定制视觉服务支持用自己的数据构建定制图像识别模型
- 视频索引器是一个可在视频中寻找人物、定义语音情感以及圈出关键词的工具
图像和视频处理应用程序接口: 谷歌云服务
云视觉应用程序接口。该工具被用于图像识别任务,并非常擅长查找特定的图像属性:
- 标记对象
- 检测脸部并分析表情
- 发现地标并描绘场景(如度假,婚礼等)
- 发现图像中的文本并辨识文本语言
- 主颜色特征
云视频智能。该谷歌的视频识别应用程序接口处于发展的早期,因此它缺少许多亚马逊Rekognition和微软认知服务的特征功能。现在该接口提供以下工具箱:
- 标记对象并定义行为
- 精确识别内容
- 转录语音
虽然从特征表级别上来说,谷歌人工智能服务也许缺少一些功能,但是谷歌应用程序接口的优势力量在于谷歌握有的大数据集。