线性模型篇之感知机(PLA)数学公式推导
转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
个人网站:http://thinkgamer.github.io
介绍
感知机(Perceptron)是一种广泛使用的线性分类器,相当于最简单的人工神经网络,只有一个神经元。其全称是PLA(Perceptron Linear Algorithm),线性感知机算法。
感知机是对生物神经元的简单数学模型,有与生物神经元相对应的部件,比如权重(突触)、偏置(阈值)及激活函数(细胞体),输出值为 +1 或者 -1。
y ^ = s g n ( w T x ) \hat{y} = sgn(w^Tx) y^=sgn(wTx)
对于二分类问题,可以使用感知机算法来解决。PLA的原理是逐点解决,首先在超平面上随意取一条分类面,统计分类错误的点,然后随机对某个错误点修正,即变换直线的位置,使该错误点被修正,接着再随机选取另外一个错误点进行修正,分类面不断变化,直到所有点都分类正确了,就得到了最佳分类面。
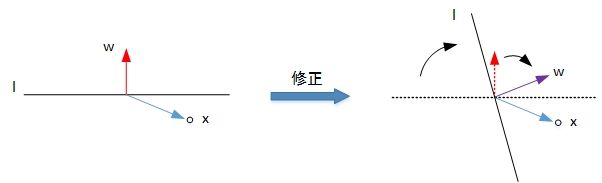
利用二维平面进行解释,第一种情况是错误的将正样本(y=1)分类为负样本(y=-1)。此时wx<0,即w与x的夹角大于90度,分类线L的两侧。修正的方法是让夹角变小,修正w值,使二者位于直线同侧。
w : = w + x = w + y x w:=w+x=w+yx w:=w+x=w+yx
修正过程如下:
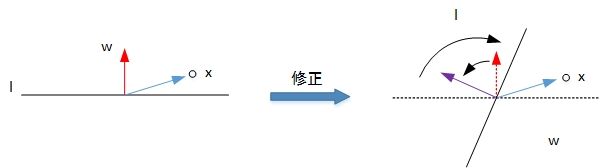
第二种情况就是错误的将负样本(y=-1)分类为正样本(y=1)。此时,wx>0,即w与x的夹角小于90度,分类线L的同一侧。修正的方法是让夹角变大,修正w值,使二者位于分类线同侧。
w : = w − x = w + y x w:=w-x=w+yx w:=w−x=w+yx
修正过程如下:
经过上边两种情况分析,PLA每次更新参数w的表达式是一致的,掌握了每次w的优化表达式,那么PLA就能不断地将所有错误的分类样本纠正并分类正确。
参数学习
给定N个训练集样本{(x^n, yn)},n<=N,其中yn 属于{+1,-1},感知机试图学习到参数w*,使得对于每个样本(xn,yn)
有:
y n w ∗ T x n > 0 , ∀ n ∈ [ 1 , N ] y^n w^{*T}x^n>0,\forall n\in [1,N] ynw∗Txn>0,∀n∈[1,N]
感知机算法是一种错误驱动的在线学习算法,先初始化一个权重向量w<-0(通常是全零向量),然后每次分错一个样本(x,y)时,就用这个样本来更新权重。
w ← w + y x w \leftarrow w + yx w←w+yx
具体的感知机算法伪代码如下(算法-1):

根据感知器的学习策略,可以反推出感知器的损失函数为:
L ( w ; x , y ) = m a x ( 0 , − y w T x ) L (w;x,y)=max(0, -yw^Tx) L(w;x,y)=max(0,−ywTx)
采用随机梯度的下降,其每次更新的梯度为:
∂ L ( w ; x , y ) ∂ w = { 0 if y T x > 0 − y x if y T x < 0 \frac{\partial L (w;x,y) }{ \partial w}=\begin{cases} 0 & \text{ if } y^Tx>0 \\ -yx & \text{ if } y^Tx<0 \end{cases} ∂w∂L(w;x,y)={0−yx if yTx>0 if yTx<0
下图给出了感知机参数学习的过程,其中红色实心为正例,蓝色空心点为负例。黑色箭头表示权重向量,红色虚线箭头表示权重的更新方向。
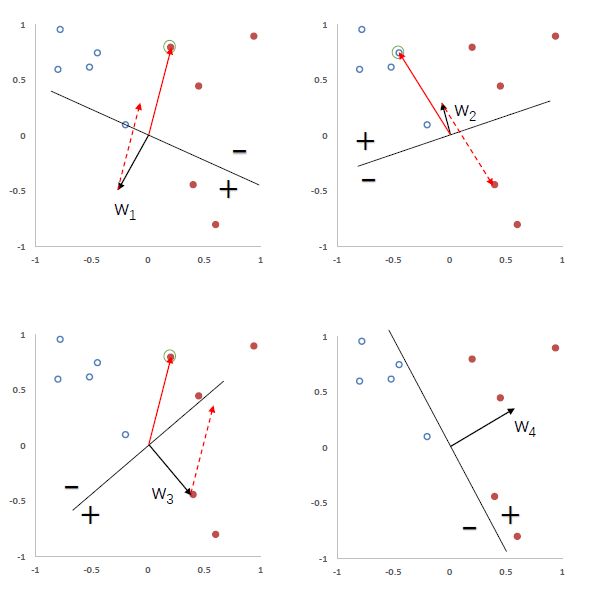
感知机的收敛
Novikoff证明对于两类问题,如果训练集是线性可分的,那么感知器
算法可以在有限次迭代后收敛。然而,如果训练集不是线性分隔的,那么这个算法则不能确保会收敛。
当数据集是两类线性可分时,对于数据集D={(xn,yn)},n属于N,其中xn为样本的增广特征向量,yn属于{-1,+1},那么存在一个正的常数r(r>0)和权重向量w,并且||w*||=1,对所有n都满足(w*)(yn x^n)>r。
可以证明如下定理(定理-1)。
给定一个训练集
D = ( x n , y n ) , n ∈ 1 , N D={(x^n,y^n)},n\in {1,N} D=(xn,yn),n∈1,N
假设R是训练集中最大的特征向量的模
R = m a x n ∥ x n ∥ R=\underset{n}{max} \left \| x^n \right \| R=nmax∥xn∥
如果训练集D线性可分,感知机学习算法-1的权重更新次数不超过 R^2/ r^2
证明:
感知机算法的权重更新方式为(公式-1):
w k = w k − 1 + y k x k w_k = w_{k-1}+y^kx^k wk=wk−1+ykxk
其中x^k, y^k表示第k个错误分类的条件。
因为初始权重为0,在第K次更新时感知器的权重向量为(公式-2):
w k = = ∑ k = 1 K y k x k w_k = =\sum_{k=1}^{K}y^kx^k wk==k=1∑Kykxk
分别计算||w||^2的上下界:
计算其上界(公式-2):
∥ w k 2 ∥ \left \| w_k^2 \right \| ∥∥wk2∥∥
= ∥ w K 1 + y K x K ∥ 2 = \left\| w_{K_1} + y^K x^K \right \|^2 =∥∥wK1+yKxK∥∥2
= ∥ w K − 1 ∥ 2 + ∥ y K x K ∥ 2 + 2 y K w K − 1 x K = \left \| w_{K-1} \right \| ^2 + \left \| y^Kx^K \right \| ^2+2y^Kw_{K-1}x^K =∥wK−1∥2+∥∥yKxK∥∥2+2yKwK−1xK
⩽ ∥ w K − 1 ∥ 2 + R 2 \leqslant \left \| w_{K-1} \right \|^2 + R^2 ⩽∥wK−1∥2+R2
⩽ ∥ w K − 2 ∥ 2 + 2 R 2 \leqslant\left \| w_{K-2} \right \|^2+2R^2 ⩽∥wK−2∥2+2R2
⩽ K R 2 \leqslant KR^2 ⩽KR2
计算其下界(公式-3):
∥ w k 2 ∥ \left \| w_k^2 \right \| ∥∥wk2∥∥
= ∥ w ∗ ∥ 2 . ∥ w K ∥ 2 =\left \| w^* \right \|^2 .\left \| w_K \right \|^2 =∥w∗∥2.∥wK∥2
⩾ ∥ w ∗ T w K ∥ 2 \geqslant \left \| w^{*T}w_K \right \| ^2 ⩾∥∥w∗TwK∥∥2
= ∥ w ∗ T ∑ k = 1 K ( y K x K ) ∥ 2 =\left \| w^{*T}\sum_{k=1}^{K}(y^Kx^K) \right \|^2 =∥∥∥∥∥w∗Tk=1∑K(yKxK)∥∥∥∥∥2
= ∥ ∑ k = 1 K w ∗ T ( y K x K ) ∥ 2 =\left \| \sum_{k=1}^{K}w^{*T}(y^Kx^K) \right \|^2 =∥∥∥∥∥k=1∑Kw∗T(yKxK)∥∥∥∥∥2
≥ K 2 r 2 \geq K^2r^2 ≥K2r2
附:两个向量内积的平方一定小于等于这两个向量的模的乘积。
由公式-2和公式-3得到(公式-4)
K 2 r 2 ≤ ∥ w K ∥ 2 ≤ K R 2 K^2r^2 \leq \left \| w_K \right \|^2\leq KR^2 K2r2≤∥wK∥2≤KR2
取最左和最右的两项,进一步得到K2r2 <= K2R2,然后两边同时除以K,最终得到(公式-5):
K ≤ R 2 r 2 K\leq \frac{R^2}{r^2} K≤r2R2
因此在线性可分的情况下,算法-1会在R^2 / r^2步内收敛。
虽然感知机线性模型在线性可分的数据上可以保证收敛,但其存在以下不足:
- 在数据集线性可分时,感知器虽然可以找到一个超平面把两类数据分开, 但并不能保证能其泛化能力。
- 感知器对样本顺序比较敏感。每次迭代的顺序不一致时,找到的分割超平 面也往往不一致。
- 如果训练集不是线性可分的,就永远不会收敛。
参数平均感知机
根据定理3.1,如果训练数据是线性可分的,那么感知器可以找到一个判别 函数来分割不同类的数据。如果间隔 γ 越大,收敛越快。但是感知器并不能保 证找到的判别函数是最优的(比如泛化能力高),这样可能导致过拟合。
感知机的学习到的权重向量和训练样本的顺序相关。在迭代次序上排在后 面的错误样本,比前面的错误样本对最终的权重向量影响更大。比如有 1, 000 个 训练样本,在迭代 100 个样本后,感知器已经学习到一个很好的权重向量。在 接下来的 899 个样本上都预测正确,也没有更新权重向量。但是在最后第 1, 000 个样本时预测错误,并更新了权重。这次更新可能反而使得权重向量变差。
为了改善这种情况,可以使用“参数平均”的策略提高感知ji的鲁棒性,也叫投票感知机。
投票感知机记录第k次更新参数之后的权重w_k在之后的训练过程中正确分类样本的次数c_k。这样最后的分类器形式为(公式-6):
y ^ = s g n ( ∑ k = 1 K c k s g n ( w k T x ) ) \hat{y} = sgn(\sum_{k=1}^{K}c_ksgn(w_k^Tx)) y^=sgn(k=1∑Kcksgn(wkTx))
其中sgn(.)为符号函数。
投票感知机虽然提高了模型的泛化能力,但是需要保存K个权重向量。在实际的操作中会带来额外的开销。因此经常会使用一个简化的版本,即平均感知机。其表达式如下(公式-7):
y ^ = s g n ( ∑ k = 1 K c k ( w k T x ) ) = s g n ( ( ∑ k = 1 K c k w k ) T x ) = s g n ( w ˉ T x ) \hat{y} = sgn(\sum_{k=1}^{K}c_k (w_k^Tx)) =sgn( (\sum_{k=1}^{K}c_k w_k )^Tx ) =sgn( \bar{w}^Tx) y^=sgn(k=1∑Kck(wkTx))=sgn((k=1∑Kckwk)Tx)=sgn(wˉTx)
其中
w ˉ \bar{w} wˉ
为平均的权重向量。
假设w_{t,n}是在第t轮更新到第n个样本时的权重向量值,平均的权重向量也可以表示为(公式-8):
w ˉ = ∑ t = 1 T ∑ n = 1 N w t , n n T \bar{w} = \frac{\sum_{t=1}^{T} \sum_{n=1}^{N}w_{t,n}}{nT} wˉ=nT∑t=1T∑n=1Nwt,n
这个方法实现简单,只需要在算法-1中增加一个平均向量,并且在处理每一个样本后,进行更新(公式-9):
w ˉ = w ˉ + w t , n \bar{w} = \bar{w}+ w_{t,n} wˉ=wˉ+wt,n
但这个方法需要在处理每一个样本时都要更新平均权重,因为
w ˉ , w t , n \bar{w} ,w_{t,n} wˉ,wt,n
都是稠密向量,因此更新操作比较费时。为了提高迭代速度,有很多改进的办法,让这个更新只需要在错误预测时才进行。下图给了一个改进的平均感知机算法的训练过程(算法-2)。

扩展到多分类
原始的感知机是二分类模型,但也很容易的扩展到多分类,甚至是更一般的结构化学习问题。
之前介绍的线性分类模型中,分类函数都是在输入x的特征空间上。为了使得感知机可以处理更加复杂的输出,我们引入一个构建输入输出联合空间上的特征函数,将样本(x,y)对映射到一个特征向量空间。
在联合特征空间中,我们可以建立一个广义的感知机模型(公式-10):
y ^ = a r g m a x y ∈ G e n ( x ) w T ϕ ( x , y ) \hat{y} = \underset{y\in Gen(x)}{ arg max} w^T \phi(x,y) y^=y∈Gen(x)argmaxwTϕ(x,y)
其中w为权重向量,Gen(x)表示输入x所有的输出目标集合。当处理C类分类问题时,Gen(x)={1,…,C}
在C分类中,一种常用的特征函数(公式-11)
ϕ ( x , y ) \phi(x,y) ϕ(x,y)
是y和x的内积,其中y为类别的one-hot向量表示(公式-12)。
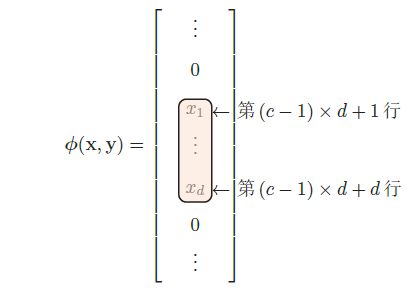
ϕ ( x , y ) = v e c ( y x T ) ∈ R ( d × C ) \phi(x,y) = vec(yx^T)\in R^{(d\times C)} ϕ(x,y)=vec(yxT)∈R(d×C)
其中vec是向量化算子。
给定样本(x,y),若
x ∈ R d x \in R^d x∈Rd
y为第c维为1的one-hot向量,则:
广义感知器算法的训练过程如算法-3所示:

