二、安装Spark集群
【一个很疑惑的问题】
为什么我们一直在反复做一个操作:就是scp拷贝过来拷贝过去?
【答案】这是为了将文件或目录的权限修改成hadoop所属组。一. 下载Spark安装包并传给mster机器,使权限是hadoop
①在slave1机器上下载Spark(进入官网下载更快)
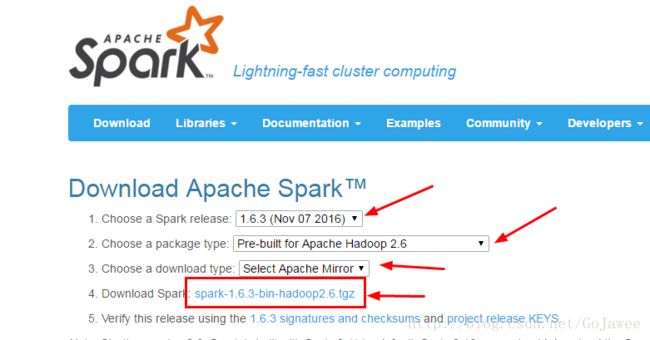
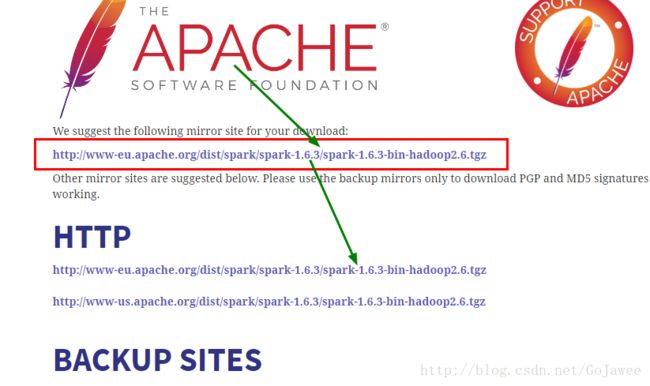
②解压安装包
tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz -C /data③把slave1机器上的解压后的spark拷贝到master机器上
先进入/data目录下,打开终端,不用修改用户
再:
scp -r spark-1.6.3-bin-hadoop2.6/ hadoop@master:/data/④删除slave1机器上的spark-1.6.3-bin-hadoop2.6
sudo rm -r /data/spark-1.6.3-bin-hadoop2.6到现在为止,
slave1机器上的spark-1.6.3-bin-hadoop2.6安装包已经被删除;
只在master机器上有spark-1.6.3-bin-hadoop2.6安装包,且权限是
hadoop。
可以进行下面的Spark配置了!==========
二 .配置 spark(涉及到的配置文件有以下几个:)
在master机器上,新建下面文件:
先su hadoop
sudo mkdir /data/spark_data
sudo chmod -R 777 /data/spark_data
sudo mkdir /data/spark_data/spark_works
sudo chmod -R 777 /data/spark_data/spark_works
sudo mkdir /data/spark_data/history
sudo chmod -R 777 /data/spark_data/history
sudo mkdir /data/spark_data/history/event-log
sudo chmod -R 777 /data/spark_data/history/event-log
sudo mkdir /data/spark_data/history/spark-events
sudo chmod -R 777 /data/spark_data/history/spark-events
再把在master创建好的上面的文件拷贝给slave机器:
在 master 机器上:
先切换到hadoop用户
su hadoop
scp -r /data/spark_data hadoop@slave1:/data
scp -r /data/spark_data hadoop@slave2:/data
此时,在slave机器上就产生了/data/spark_data目录,查看权限是hadoop
删除上面再master机器上创建的目录(在master机器上执行)
sudo rm -r /data/spark_data
从slave1机器上复制一份给master(在slave1机器上执行)
scp -r /data/spark_data hadoop@master:/data1. ${SPARK_HOME}/conf/spark-env.sh
2. ${SPARK_HOME}/conf/slaves
3. ${SPARK_HOME}/conf/spark-defaults.conf
这三个文件都是由原始的 template 文件复制过来的,比如:
先进入conf目录下,打开终端,再:
su hadoop
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
sudo chmod -R 777 ../*配置文件 1:sudo gedit spark-env.sh
【重点注意】SPARK_MASTER_IP=192.168.1.10一定要修改成自己的master地址
注意:需要在本地创建/data/spark_data/spark_works 目录
JAVA_HOME=/data/jdk1.8.0_111
SCALA_HOME=/data/scala-2.11.8
SPARK_MASTER_IP=192.168.1.10
HADOOP_CONF_DIR=/data/hadoop-2.6.5/etc/hadoop
# shuffled以及 RDD的数据存放目录
SPARK_LOCAL_DIRS=/data/spark_data
# worker端进程的工作目录
SPARK_WORKER_DIR=/data/spark_data/spark_works配置文件 2:sudo gedit slaves
去掉最后一行的localhost后,在最后一行加上下面内容
master
slave1
slave2配置文件 3:sudo gedit spark-defaults.conf
注意:需要在本地创建/data/spark_data/history/event-log、/data/spark_data/history/spark-events
spark.master spark://master:7077
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.eventLog.enabled true
spark.eventLog.dir file:///data/spark_data/history/event-log
spark.history.fs.logDirectory file:///data/spark_data/history/spark-events
spark.eventLog.compress true===
三 . 复制到其他节点
在 master 上:
1. scp -r /data/spark* hadoop@slave1:/data
2. scp -r /data/spark* hadoop@slave2:/data
发现在 slave1 和slave2 上的/data目录下有spark-1.6.3-bin-hadoop2.6的目录,
查看权限是hadoop组。
spark*实际上也把创建的目录/data/spark_data全部拷贝过去了。四 . 设置环境变量
在master机器上:
su hadoop
sudo gedit ~/.bashrc
将以下内容加入到~/.bashrc 文件中,
export SPARK_HOME=/data/spark-1.6.3-bin-hadoop2.6
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
然后执行以下命令:
source ~/.bashrc
再把master机器上的~/.bashrc文件拷贝到slave机器上:(在hadoop用户下)
su hadoop #切换到hadoop用户
scp -r ~/.bashrc hadoop@slave1:~/
scp -r ~/.bashrc hadoop@slave2:~/=======================================
=======================================
5. 启动验证
在master机器上
1)启动 master
start-master.sh
下图说明在 master 节点上成功启动 Master 进程:
在master机器上
2)启动 slave
start-slaves.sh
jps
在slave机器上
执行jps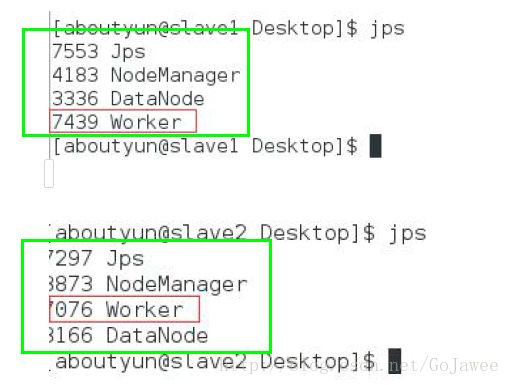
上面的图片说明在每台机器上都成功启动了 Worker 进程。3)访问 WebUI
在 master、slave1 和 slave2 这三台中任意一台机器上的浏览器中输入:http://master:8080/,
看到如下图片,就说明我们的 spark 集群安装成功了。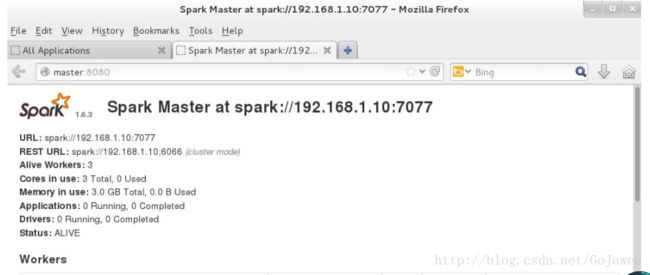
===
趟过的坑
配置 core-site.xml 和 hdfs-site.xml 文件时所指定的本地目录一定要自己
创建,否则在执行 玩格式化 hdfs 后,启动 hdfs 会丢失进程。