干货:Spark RDD写入HBase 优化
文章目录
- 一、HBase部分
- 1-1、hbase.regionserver.handler.count
- 1-2、压缩
- 1-3、分裂
- 1-4、hbase.regionserver.optionallogflushinterval
- 1-5、hbase.hregion.memstore.flush.size
- 1-6、hbase.hstore.blockingStoreFiles
- 1-7、hbase.rest.threads.min/max
- 1-8、hbase.client.write.buffer
- 二、HDFS部分
- 2-1、dfs.datanode.handler.count
- 2-2、dfs.namenode.handler.count
- 2-3、dfs.datanode.balance.bandwidthPerSec
- 2-4、dfs.datanode.max.transfer.threads
- 2-5、dfs.namenode.service.handler.coun
- 2-6、dfs.datanode.readahead.bytes
- 三、Spark部分
- 3-1、driver-memory
- 3-2、num-executors
- 3-3、executor-memory
- 3-4、executor-cores
- 3-5、spark.default.parallelism
- 3-6、spark.storage.memoryFraction
- 3-7、spark.shuffle.memoryFraction
- 四、yarny
- 4-1、mapreduce.task.io.sort.factor
- 4-2、mapreduce.job.reduce.slowstart.completedmaps
- 4-3、io.file.buffer.size
- 4-4、mapreduce.task.io.sort.mb
- 4-5、所有与内存以及堆内存有关的参数
- 五、spark-submit验证
- 5-1、默认参数
- 5-2、 修改参数
- 5-3、改为2.1G数据测试
- 5-4、为什么5个reducer tasks只有一个真正运行了
- 六、进一步优化
- 6-1、修改代码
- 6-2、修改spark.storage.memoryFraction与spark.shuffle.memoryFraction、executor-memory
- 疑惑:
- 2019/5/29补充
- 参考
一、HBase部分
1-1、hbase.regionserver.handler.count

该配置参数用于定义regionserver上用于等待响应用户表级请求的线程数,通常的配置规则是:
- 当每次请求的数据量较大时(如接近MB的单次put,cache较大的scan操作),设小一些;
- 当每次请求负载较小时,则可把该值配置较大。同时在请求的数据量大小收到参数。
- 如果单个请求的数据量很大,并且将该值配置的很大时,put并发量很高时,会给内存造成很大压力,甚至有可能触发内存溢出。
- 正在进行的查询的总大小受设置hbase.ipc.server.max.callqueue.size限制
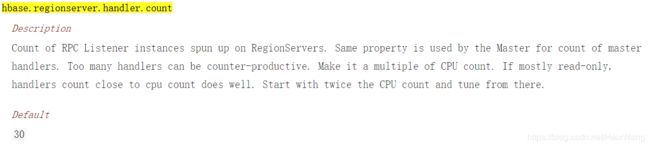
可以通过查看rpc.logging(regionserver打开DEBUG日志级别),根据在排队的线程数量消耗的内存大小来判断hbase.regionserver.handler.count配置是否过大或者过小。
暂时更改为256
1-2、压缩
TODO
1-3、分裂
重要的设置包括hbase.regionserver.region.split.policy,hbase.hregion.max.filesize,hbase.regionserver.regionSplitLimit。分裂的简单观点是,当一个区域增长到时hbase.hregion.max.filesize,它就会分裂。对于大多数使用模式,您应该使用自动拆分。有关手动区域拆分的详细信息,请参阅手动区域拆分决策。
您可以选择自行管理拆分,而不是让HBase自动拆分您的区域。如果你很清楚你的键空间,手动管理分割是有效的
1-4、hbase.regionserver.optionallogflushinterval
HLog 条目的同步间隔:
如尚未累计到触发同步的 HLog 条目的指定数量,则在此间隔后使 HLog 同步到 HDFS (以秒为单位)
默认1s,暂时修改为5s
1-5、hbase.hregion.memstore.flush.size
HBase Memstore 刷新大小
如 memstore 大小超过此值,Memstore 将刷新到磁盘。通过运行由 hbase.server.thread.wakefrequency 指定的频率的线程检查此值。
默认128MB,根据机器性能调整
暂不做修改
1-6、hbase.hstore.blockingStoreFiles
HStore 阻塞存储文件
如在任意 HStore 中有超过此数量的 HStoreFiles,则会阻止对此 HRegion 的更新,直到完成压缩或直到超过为 ‘hbase.hstore.blockingWaitTime’ 指定的值。
默认16,暂时修改为32
1-7、hbase.rest.threads.min/max
HBase REST Server 最小/大线程数
HBase REST Server 线程池的最小大小。该服务器始终在池中保留至少此数量的线程。线程池可以增长到 hbase.rest.threads.max 设置的最大大小。
HBase REST Server 线程池的最大大小。该服务器可以处理此数量的并发请求。将此值设置过高的值会导致内存不足错误。
默认为2/100,暂时修改为10/200
1-8、hbase.client.write.buffer
HBase 客户端写入缓冲
写入缓冲区大小。较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。为了估计服务器已使用内存的数量,请用值“hbase.client.write.buffer”乘以“hbase.regionserver.handler.count”。
默认为2MB,暂时修改为100MB
二、HDFS部分
2-1、dfs.datanode.handler.count
DataNode 服务器线程数
默认3,暂时修改为50
2-2、dfs.namenode.handler.count
NameNode 的服务器线程的数量。
默认30,暂时修改为150
2-3、dfs.datanode.balance.bandwidthPerSec
每个 DataNode 可用于平衡的最大带宽
默认10MB,暂时修改为100MB
2-4、dfs.datanode.max.transfer.threads
指定在 DataNode 内外传输数据使用的最大线程数
默认4096,暂时修改为16384
2-5、dfs.namenode.service.handler.coun
NameNode 用于服务调用的服务器线程数量。仅用于已配置 NameNode Service RPC Port 时
默认30,暂时修改为60
2-6、dfs.datanode.readahead.bytes
提前读取的字节数
启用shuffle readahead来改善MapReduce shuffle处理程序的性能;
读取块文件时,DataNode 可以使用 posix_fadvise 系统呼叫将数据显式放入操作系统缓冲区缓存中当前读取器位置之前。这样可以提高性能,尤其是在磁盘高度占用的情况下。该配置指定 DataNode 尝试提前读取的位置比当前读取位置提前的字节数。值为 0 时禁用此功能。CDH3u3 或之后的部署中支持此属性。
默认4MB,暂时修改为20MB
修改完以上值后,测试发现,性能竟然没有任何提升,运行io 测试工具(写5个150MB的文件):
sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.2.0-tests.jar TestDFSIO -write -nrFiles 5 -fileSize 150结果为:
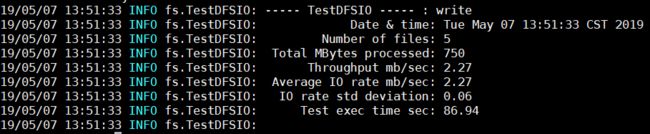
猜测以上修改对local模式作用不大??
三、Spark部分
3-1、driver-memory
参数说明:
该参数用于设置Driver进程的内存。
参数调优建议:
Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
3-2、num-executors
参数说明:
该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。Container数量与此有一定关系,但不是等同的。
参数调优建议:
每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适(具体看数据的大小,集群的资源,运行后4040或者18080去看每个Task处理的时长以及处理的数据量),设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;
设置的太多的话,大部分队列可能无法给予充分的资源(会一直尝试请求资源,任务等待执行)。
3-3、executor-memory
参数说明:
该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:
每个Executor进程的内存设置4G\~8G较为合适(具体也看自己的数据大小以及集群计算能力)。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,不能超过队列的最大内存。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
3-4、executor-cores
参数说明:
该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:
Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
3-5、spark.default.parallelism
参数说明:
该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:
很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
3-6、spark.storage.memoryFraction
参数说明:
该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据选择的不同的持久化策略,如果内存不够时,数据可能会写入磁盘。
参数调优建议:
如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
3-7、spark.shuffle.memoryFraction
参数说明:
该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:
如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用时溢写到磁盘上降低性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
资源参数的调优,没有一个固定的值,需要根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及spark web ui中显示的作业gc情况),
合理地设置上述参数。
四、yarny
4-1、mapreduce.task.io.sort.factor
排序文件时要合并的流的数量。也就是说,在 reducer 端合并排序期间要使用的排序头数量。此设置决定打开文件句柄数。并行合并更多文件可减少合并排序迭代次数并通过消除磁盘 I/O 提高运行时间。注意:并行合并更多文件会使用更多的内存。如 ‘io.sort.factor’ 设置太高或最大 JVM 堆栈设置太低,会产生过多地垃圾回收。Hadoop 默认值为 10,但 Cloudera 建议使用更高值。将是生成的客户端配置的一部分。
4-2、mapreduce.job.reduce.slowstart.completedmaps
Reduce 任务前要完成的 Map 任务数量
4-3、io.file.buffer.size
SequenceFile I/O 缓存区大小
4-4、mapreduce.task.io.sort.mb
当排序文件时要使用的内存缓冲总量(以 MB 为单位)。注意:此内存由 JVM 堆栈大小产生(也就是:总用户 JVM 堆栈 - 这些内存 = 总用户可用堆栈空间)。注意:Cloudera 的默认值不同于 Hadoop 的默认值;默认情况下,Cloudera 使用更大的缓冲,因为现代机器通常有更多的 RAM。所有 TaskTrackers 中的最小值将成为生成的客户端配置的一部分。
4-5、所有与内存以及堆内存有关的参数
比如mapreduce.reduce.memory.mb
mapreduce.reduce.cpu.vcores
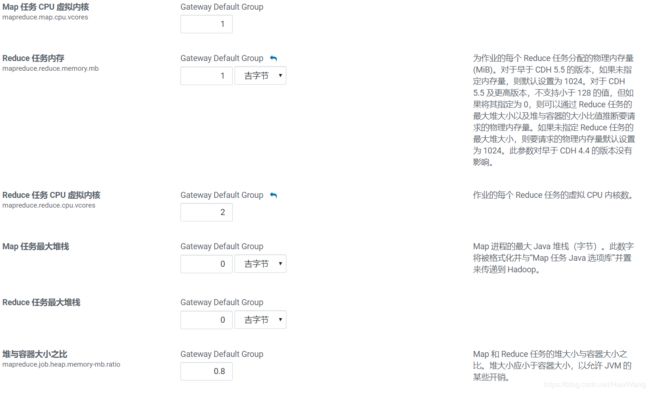
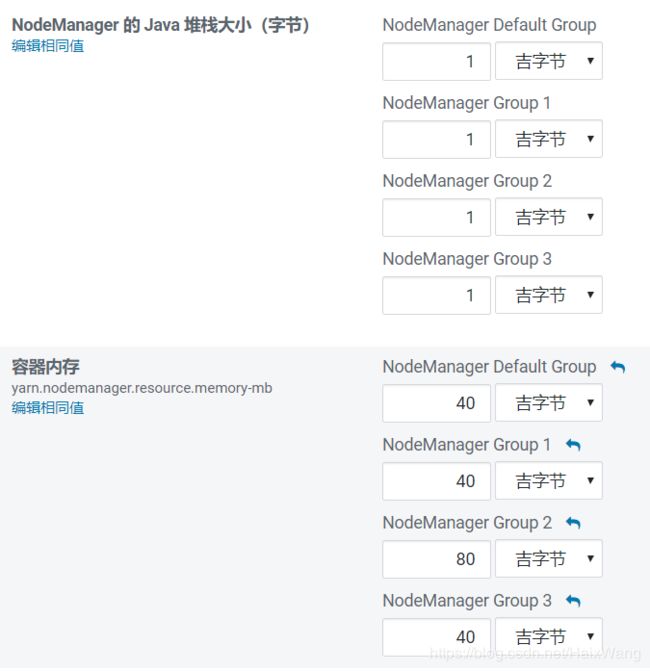
五、spark-submit验证
5-1、默认参数
2.1G测试数据
18个CPU Cores,18个Containers,约27G内存(怎么不是18的倍数???)


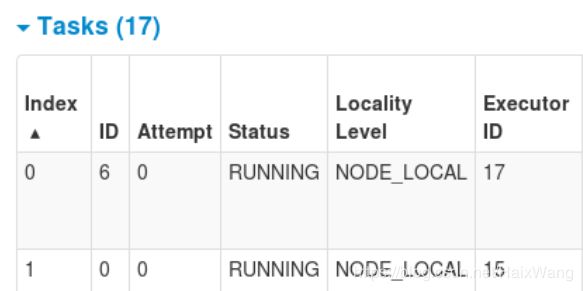
报错:ExecutorLostFailure (executor 9 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 1.6 GB of 1.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead or disabling yarn.nodemanager.vmem-check-enabled because of YARN-4714.
该讨论中,这句话应该是正解:
This means the JVM took more memory than YARN thought it should. Usually this means you need to allocate more overhead, so that more memory is requested from YARN for the same size of JVM heap. See the spark.yarn.executor.memoryOverhead option, which defaults to 10% of the specified executor memory. Increase it.
spark-submit时设置spark.yarn.executor.memoryoverhead
Spark日志中,可以看到这样的信息:
INFO yarn.Client: Will allocate AM container, with 2432 MB memory including 384 MB overhead
注:2.3后使用后spark.executor.memoryOverhead
再次提交,发觉containers等数量少一半多???可之前的应用已经kill了,不存在资源不够的问题

太慢了,改用400MB数据测试
- 处理数据耗时15min
- SparkHadoopWriter耗时4.2min

5-2、 修改参数
sudo -u hdfs spark-submit \
--class core.BulkLoadPut \
--master yarn \
--deploy-mode cluster \
--driver-memory 2G \
--num-executors 60 \
--executor-memory 3G \
--executor-cores 3 \
--conf spark.default.parallelism=300 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.4 \
/cluster_jars/devbigdata.jar \
filePath \
60(partitions)

注意:
spark.default.parallelism设置的应该是defaultParallelism
/** Default level of parallelism to use when not given by user (e.g. parallelize and makeRDD). */
def defaultParallelism: Int = {
assertNotStopped()
taskScheduler.defaultParallelism
}
而textFile中的minPartitions参数等于math.min(defaultParallelism, 2),但是这并不意味着读取的文件只会被分为2个区(只有两个并行度),这里比较绕,可参考
集群模式时:spark.default.parallelism = max(所有executor使用的core总数, 2)
5-3、改为2.1G数据测试
sudo -u hdfs spark-submit \
--class core.BulkLoadPut \
--master yarn \
--deploy-mode cluster \
--driver-memory 2G \
--num-executors 60 \
--executor-memory 2G \
--executor-cores 3 \
--conf spark.default.parallelism=300 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.4 \
/cluster_jars/devbigdata.jar \
filePath \
150

containers数不是期望的数,kill改变参数试试
sudo -u hdfs spark-submit \
--class core.BulkLoadPut \
--master yarn \
--deploy-mode cluster \
--driver-memory 2G \
--num-executors 70 \
--executor-memory 3G \
--executor-cores 4 \
--conf spark.default.parallelism=600 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.4 \
/cluster_jars/devbigdata.jar \
filePath \
300
现在数据写HDFS是瓶颈

注意到shuffle spill数量大:(比较难优化??太多的Put等对象)
并且shuffle write阶段,数据写到了同一机器的内存及磁盘??
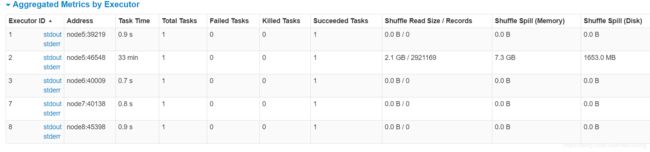
- 当没有足够的内存用于随机数据时,会发生shuffle spill。
Shuffle spill (memory) - 溢出时内存中数据的反序列化后的大小
shuffle spill (disk) - 溢出后磁盘上数据序列化后的大小 - (由于反序列化后为大量的对象,所以耗用的内存大,这也是可优化的一方面,尽量少使用对象)
- 但是写入HBase的数据,都是封装为大量的Put对象或者KeyValue对象
- 当内存不够用时,spill到磁盘
TODO:RDD压缩,进一步检查序列化
5-4、为什么5个reducer tasks只有一个真正运行了
这篇讨论与我的问题相似,Bulk Load 增加reducer数量
The reduce phase of a bulk load preparation job is used to align the output
files against the # of regions under the targeted table.You will always see the number of reducers equal the number of regions in the targeted table during the time of launching the job.
If you desire more reducers, you will need to pre-split your table
appropriately. Read up more on pre-splitting at
但是我已经预分区了
查看regions相关信息:
list_regions 'table'hbase hbck -details 'table- master的16010端口
发现数据Hash不均匀:
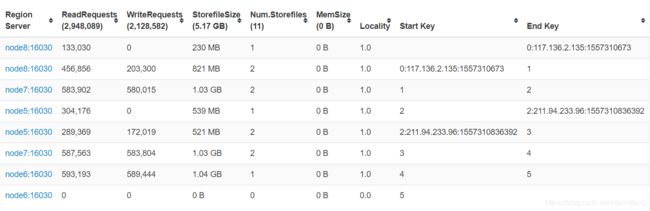
该网页源码
但也不能解释5个reducer tasks只有一个真正运行
六、进一步优化
6-1、修改代码
- 修改序列化为
KryoSerializer - 使用随机数取余对rowkey加盐,避免hash不均匀
- 转为使用
saveAsNewAPIHadoopFile,而不是saveAsNewAPIHadoopDataset(不知道后者到底是自己计算的rowkey边界还是使用的预分区边界) - log清洗改为返回数组,之前是返回元组(这里我不需要元组,我认为元组比数组更耗内存)
6-2、修改spark.storage.memoryFraction与spark.shuffle.memoryFraction、executor-memory
sudo -u hdfs spark-submit \
--class core.BulkLoadPut \
--master yarn \
--deploy-mode cluster \
--driver-memory 2G \
--num-executors 50 \
--executor-memory 4G \
--executor-cores 5 \
--conf spark.default.parallelism=600 \
--conf spark.storage.memoryFraction=0.4 \
--conf spark.shuffle.memoryFraction=0.5 \
/cluster_jars/devbigdata.jar \
filePath \
150
此时stage0耗时11min
上面的设置,num-executors * executor-cores超过了总的cores,所以containers分配不为预期?继续修改如下:
sudo -u hdfs spark-submit \
--class core.BulkLoadPut \
--master yarn \
--deploy-mode cluster \
--driver-memory 2G \
--num-executors 20 \
--executor-memory 6G \
--executor-cores 4 \
--conf spark.default.parallelism=300 \
--conf spark.storage.memoryFraction=0.4 \
--conf spark.shuffle.memoryFraction=0.5 \
/cluster_jars/devbigdata.jar \
filePath \
60
…迷
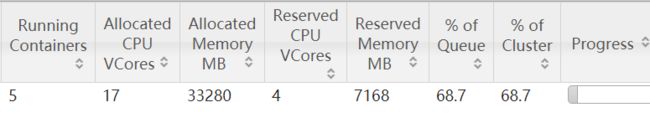
疑惑:
运行期间,重新请求了容器???有容器失效???
然后发现任务全部重新计算,但是我这里只有窄依赖啊?没必要从头计算啊???
2019/5/29补充
修改yarn的一些参数后:
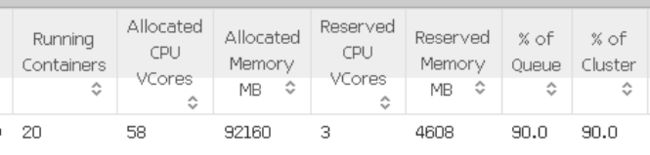
要查看每个节点的可用资源,您可以转到RM UI(http://
参考
1. 使用正确的并行度
2. spark.yarn.executor.memoryOverhead
3. min partitions
4. shuffle spill
5. How to optimize shuffle spill in Apache Spark application
6. yarn调参
7. Best Practices for YARN Resource Management