SLAM学习——回环检测
1.回环检测
回环检测的关键,就是如何有效的检测出相机经过同一个地方这件事。它关系到我们估计的轨迹和地图在长时间下的正确性。
由于回环检测提供了当前数据与所有历史数据的关联,在跟踪算法丢失后,我们还可以利用重定位。有些时候,我们把仅有前端和局部后端的系统称为VO,把带有回环检测和全局后端的系统称为SLAM。
回环检测的方法:基于里程计的几何关系和基于外观。
基于几何关系是说,当我们发现当前相机运动到了之前的某个位置时,检测它们有没有回环关系。但是由于误差积累的存在,我们往往没办法正确发现“运动到了之前的某个位置附近”这个事实。
基于外观的(主流做法),它和前端、后端的估计都无关,仅根据俩副图像的相似性确定回环检测关系,这种做法摆脱了积累误差,使回环检测模块成为SLAM一个相对独立的模块。
在基于外观回环检测算法中,核心问题是如何计算图像间的相似性。比如对于图像A和图像B,我们要计算它们之间的相似性评分:s(A,B)。如果单单用俩副图像相减然后取范数 s(A,B)=||A−B|| s ( A , B ) = | | A − B | | 。但是由于一副图像在不同角度或者不同光线下其结果会相差很多,所以不使用这个函数。
程序判断与实际总有误差,以下是我们的分类结果:

其中假阳性又称为感知偏差,假阴性称为感知变异。为方便,则真阳性(True Positive)简称TP,假阳性称为(False Positive)简称FP,以此类推。当然,所有的结果我们都希望FP和FN尽可能要低。对于某特定算法,我们可以统计它在某个数据集上的TP、FP、FP、FN的出现次数,并统计俩个统计量:准确率Presicion=TP/(TP+FP)和召回率Recall=TP/(TP+FN)。
从上述公式可以得到,准确率描述的是,算法提取的所有回环中确实是真实回环的概率。而召回率是说在所有真实回环中被正确检测出来的概率。一般而言,我们更倾向于提高算法的准确性,稍微牺牲下召回率。如果出现假阳性,那么就会在后端的Pose graph添加错误的边,导致误差不准。
2.词袋模型
1.确定概念,例如一副图像上有人、狗等,那么“人”“狗” 等概念就是Bag-of-Words中的“单词”,许多单词放在一起,组成了“字典”。
2.确定一副图像中出现了哪些在字典中定义的概念——用单词出现的情况(直方图)描述整副图像,转换成向量。
3.比较上一步中的描述的相似程度。
举个例子,若“人”“狗”都在字典里(这里的字典是已经知道的),不防设为 w1,w2 w 1 , w 2 ,假设A图像中有人没狗,则可以描述成: A=1∗w1+0∗w2 A = 1 ∗ w 1 + 0 ∗ w 2 ,由于字典是固定的,那么只需要一个向量就可以描述整副图像了,例如 A=[1,0]T A = [ 1 , 0 ] T
通过这个词袋模型,我们可以得到俩张图片在这个词袋里面的向量 a,b∈Rw a , b ∈ R w ,那么可以计算 s(a,b)=1−1W||a−b||1 s ( a , b ) = 1 − 1 W | | a − b | | 1 ,如果俩个向量相等,那么我们得到1,完全相反(即a为0的地方b为1)则得到0。
3.字典
假设我们对所有的图片进行特征点的提取,比如有N个。我们现在可以寻找一个有个单词的字典,每个单词可以看作相邻特征点的集合,可以用K-means均值来做:
1.随机选取k个中心点: c1,⋯cn c 1 , ⋯ c n 。
2.对每一个样本,计算它与每个中心点之间的距离,取最小的作为它的归类。
3.重新计算每个类的中心点。
4.如果每个中心点变化很小,那么退出,算法收敛;否则返回第二步。
K-means存在小问题,就是:需要指定聚类数量,随机选取中心点等。
为了解决这个问题,我们使用一种K叉树来表达字典。假定我们构建一个深度为d、每次分叉为k的树,那么做法如下:
1.在根节点上,用K-means把所有样本聚成k类(有时候为保证聚类均匀性会使用k-means++),这样得到了第一层。
2.对于第一层的每个节点,把属于该节点的样本再聚类k类,得到下一层。
3.以此类推,最后得到叶子层。叶子层即所谓的Words。
一方面,这样一个k分支,深度为d的树,可以容纳 kd k d 个单词。另一方面,在查找某个特征对应的单词时,只需要将它与每个中间节点的聚类中心比较(一共d次),即可找到最后的单词。
紧接着我们创建字典,直接上代码:(高博用的是opencv3,我用的是opencv2,略有不同)
#include "DBoW3/DBoW3.h" //使用了BOW这个库
#include vector images;
for ( int i=0; i<10; i++ )//这里选取了10张图片
{
string path = "/home/hansry/Slam_Book/src/Feature_traning/data/"+to_string(i+1)+".png";
images.push_back( imread(path) );
}
// detect ORB features
cout<<"detecting ORB features ... "< detector = ORB::create("FAST");//由于这里用的是opencv2,所以略有不同
vectorcout<<"vocabulary info: "<"vocabulary.yml.gz" );
cout<<"done"<return 0;
} Cmakelist如下:
cmake_minimum_required(VERSION 2.8.3)
project(Feature_traning)
set(CMAKE_CXX_FLAGS "-std=c++11 -O3")
find_package(OpenCV REQUIRED )
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.so" )
catkin_package(
# INCLUDE_DIRS include
# LIBRARIES test
# CATKIN_DEPENDS opencv roscpp
# DEPENDS system_lib
)
include_directories(include)
include_directories(
${catkin_INCLUDE_DIRS}
${OpenCV_INCLUDE_DIRS}
)
add_executable(Feature_traning src/Feature_traning.cpp)
target_link_libraries(Feature_traning
${catkin_LIBRARIES}
${OpenCV_LIBRARIES}
${DBoW3_LIBS}
)结果如下图所示:
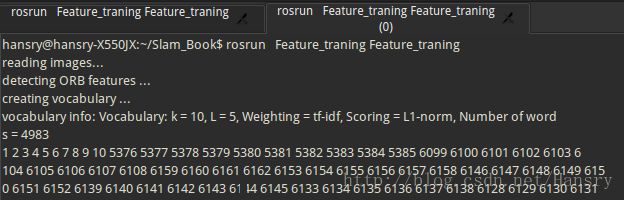
我们这里使用的是默认构造函数,所以默认分支数量为10,深度L为5,单词数量为4983,没有达到最大容量。weighting是权重,scoring是评分。
4.相似度计算
在上一part中,我们创建了字典,那么有了字典以后,给定任意特征点 fi f i ,只要在字典树中逐层查找,最后都能找到与之对应的单词 wj w j ,如果字典足够大,我们可以说这俩个来自同一类物体。
假设一副图像提取N个特征,找到这N个特征对应的单词之后,就相当于有了该图像在单词列表中的分布,相当于“这幅图里有一个人和一辆汽车”等。但是有的时候,我们会希望对单词的区分性或重要性加以评估,会给单词加权重。
这里,我们提供一种方法叫TF-IDE,TF的思想是:某单词在一副图像中经常出现,它的区分度就越高。另一方面,IDE的思想是,某单词在字典中出现的频率越低,则分类图像时的区分度越高。
对于IDF部分,假设所有特征数量为n,某个叶子节点的 wi w i 所含的数量特征为 ni n i ,那么该单词的IDF为:
IDFi=lognni I D F i = l o g n n i
TF是指某个特征在单副图像中出现的频率。假设图像A中单词 wi w i 出现了 ni n i 次,而一共出现的单词次数是n,那么TF为:
TFi=nin T F i = n i n
于是 wi w i 的权重等于TF乘IDF之积,即 ηi=TFi×IDFi η i = T F i × I D F i
考虑权重以后,对于某副图像,我们就可以得到许多个单词,得到BOW:
(A是一幅图像) A={(w1,η1),(w2,η2),⋯,(wn,ηn)}=ΔvA A = { ( w 1 , η 1 ) , ( w 2 , η 2 ) , ⋯ , ( w n , η n ) } = Δ v A (是一个向量,非零部分表示含有哪些单词)
如何计算俩副图像相似度,这里使用了 L1 L 1 范数形式:
s(vA−vB)=2∑Ni=1|vAi|+|vBi|−|vAi−vBi| s ( v A − v B ) = 2 ∑ i = 1 N | v A i | + | v B i | − | v A i − v B i |