利用TensorRT对深度学习进行加速
关于本文章的最新更新请查看:oldpan博客
前言
TensorRT是什么,TensorRT是英伟达公司出品的高性能的推断C++库,专门应用于边缘设备的推断,TensorRT可以将我们训练好的模型分解再进行融合,融合后的模型具有高度的集合度。例如卷积层和激活层进行融合后,计算速度可以就进行提升。当然,TensorRT远远不止这个:
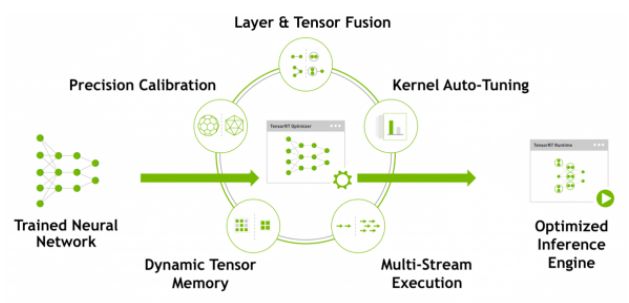
我们平时所见到了深度学习落地技术:模型量化、动态内存优化以及其他的一些优化技术TensorRT都已经有实现,更主要的,其推断代码是直接利用cuda语言在显卡上运行的,所有的代码库仅仅包括C++和cuda,当然也有python的包装,我们在利用这个优化库运行我们训练好的代码后,运行速度和所占内存的大小都会大大缩减。
在Oldpan博客的之前文章中也有所提及:新显卡出世,我们来谈谈与深度学习有关的显卡架构和相关技术
总之,这个库是所有需要部署同志需要理解并精通的一项技能,毕竟Nvidia自己开发的,性能相比其他类似产品当然是最好的(目前该库貌似并不开源)。
TensorRT
那我们开始使用它吧,之后TensorRT简称为TRT。
其实类似TensorRT具体工作的有很多,例如TVM、TC(Tensor Comprehensions),都做了一些类似于TensorRT的工作,将训练好的模型转化为运行在特定端(例如GPU)的进行模型优化等一系列操作后的代码,从而达到快速预测的效果。
那么为什么要选择TensorRT呢?很简单,因为我们目前主要使用的还是Nvidia的计算设备,在Nvidia端的话肯定要用Nvidia亲儿子了。
那么开始吧,首先我们在官网进行下载:https://developer.nvidia.com/tensorrt
对于我来说,因为自己的环境中有cuda9.0 + cuda9.2,而目前最新可下载TRT版本为5(我们也可以下载其他版本),该版本支持cuda10和cuda9.0。因此我选择了最新的版本(TensorRT-4版本其实也装了)。下载的童鞋记得要提前了解自己的版本是否合适,这里推荐下载最新的版本,因为TensorRT更新较快,为了避免一些重复造轮子的操作,最好还是下载最新版本。
至于下载的类型,由于我之前的cuda安装方式是runtime,所以我选择了tar package来下载TensorRT(如下图),至于为什么下面会说。
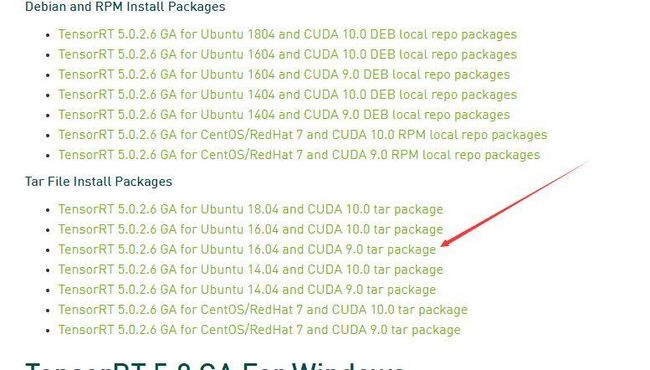
TensorRT安装
一开始我选择了 Debian Installation 的方式,也就是下载的DEB的安装包,但是在安装过程中提示:
...
sudo apt-get install tensorrt
...
tensorrt : Depends: libnvinfer4 (>= 4.1.2) but it is not going to be installed
...
那是因为如果我们之前的cuda toolkit是通过runtime方式安装的话,没有上述的动态链接库,所以在安装TensorRT的时候会导致失败,这里我比较懒,不想再安装一遍cuda所以采取了第二种安装TensorRT的方式。
相关问题:https://devtalk.nvidia.com/default/topic/1027490/tensorrt/tensorrt-3-0-installation-with-cuda-toolkit-9-1-cublas-error/
tar 安装
其实安装一个库的话,在Linux中无非我们进行的操作是将其安装到系统地址中,然后添加环境变量,而TensorRT库其实也就是包含了动态链接、静态链接还有头文件的一个文件夹,我们在下载官方的tar包之后进行解压:
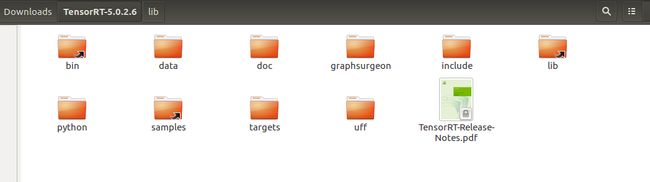
lib中存放最重要的链接库,我们上述中DEB方式安装缺少的文件就在这里,这里我们解压后,为了之后的方便使用,我们添加以下环境变量:
sudo gedit ~/.bashrc
# 在其中添加
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/prototype/Downloads/TensorRT-5.0.2.6/lib
# 别忘了source
source ~/.bashrc
理论上,这样就安装完了。
python端安装TensorRT
这里提一下python端的安装,因为TensorRT强调的是性能, 因此个人认为主要的执行环境还是放在纯C++中较好一些,所以python端的接口只进行下简单的展示,python端安装还是比较简单的,在一切前提步骤都执行好,也就是环境变量设置正确的情况下直接进行安装即可:

找到存放.whl文件的位置,利用pip安装:
sudo pip install /home/prototype/Downloads/TensorRT-5.0.2.6/python/tensorrt-5.0.2.6-py2.py3-none-any.whl
安装没问题之后,我们进入python环境执行以下命令,
Python 3.5.2 (default, Nov 12 2018, 13:43:14)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorrt
>>> tensorrt.__version__
'5.0.2.6'
以上内容基于官方的安装指南:https://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html
测试程序
好了,安装后先验证下,让我们跑一下官方的代码,首先进入samples目录:
执行CUDNN_INSTALL_DIR=/usr/local/cuda/ make -j8 进行编译。
这里因为我在编译时提示没有找到cudnn的目录,因此加了CUDNN_INSTALL_DIR=/usr/local/cuda/这个命令,正常情况下直接make即可。
编译后,所有的可执行文件都放到了bin中,我们进入bin文件夹,执行以下示例程序:
首先这个是TensorRT-4版本的:
prototype@prototype-X299-UD4-Pro:~/Downloads/TensorRT-4.0.1.6/bin$ ./sample_int8 mnist
FP32 run:400 batches of size 100 starting at 100
........................................
Top1: 0.9904, Top5: 1
Processing 40000 images averaged 0.00157702 ms/image and 0.157702 ms/batch.
FP16 run:400 batches of size 100 starting at 100
Engine could not be created at this precision
INT8 run:400 batches of size 100 starting at 100
........................................
Top1: 0.9908, Top5: 1
Processing 40000 images averaged 0.00122583 ms/image and 0.122583 ms/batch.
可以看到提速比22%,再来看TensorRT-5版本的
FP32 run:400 batches of size 100 starting at 100
........................................
Top1: 0.9904, Top5: 1
Processing 40000 images averaged 0.00165246 ms/image and 0.165246 ms/batch.
FP16 run:400 batches of size 100 starting at 100
Engine could not be created at this precision
INT8 run:400 batches of size 100 starting at 100
........................................
Top1: 0.9908, Top5: 1
Processing 40000 images averaged 0.0011709 ms/image and 0.11709 ms/batch.
貌似新版本的增速幅度稍微大一些…因为我是1080Ti,计算能力6.1,并不支持FP16,但是int8的量化还是可以使用的,可以看到int8的量化模型提速了20%多,还算不错,因为这仅仅是个小任务,在大型任务中提速只会更快。
示例库中还有ONNX的示例程序sampleOnnxMNIST,我们也可以执行测试,通过解析读取mnist.onnx模型然后进行预测。而在TensorRT中对ONNX模型进行解析的工具就是ONNX-TensorRT。
ONNX-TensorRT
这个是NVIDIA和ONNX官方维护的一个ONNX模型转化TensorRT模型的一个开源库,主要的功能是将ONNX格式的权重模型转化为TensorRT格式的model从而再进行推断操作。
让我们来看一下具体是什么样的转化过程:

其中主要的转化工作是ONNX-TensorRT执行的,TensorRT的tar压缩包中的动态链接库中就包含了ONNX-TensorRT编译后的动态库,如果我们这个库是开源的,我们可以自行对其进行编译,然后在链接程序的时候添加上其动态库即可。
我们修改一下官方的sample中的sampleOnnxMNIST中的代码:
...
int main(int argc, char** argv)
{
gUseDLACore = samplesCommon::parseDLA(argc, argv);
// create a TensorRT model from the onnx model and serialize it to a stream
IHostMemory* trtModelStream{nullptr};
// 我们将官方的 mnist.onnx 换为我们自己导出的类mobilenet模型
onnxToTRTModel("mobilenetv2-128.onnx", 1, trtModelStream);
assert(trtModelStream != nullptr);
// read a random digit file
srand(unsigned(time(nullptr)));
uint8_t fileData[INPUT_H * INPUT_W];
int num = rand() % 10;
readPGMFile(locateFile(std::to_string(num) + ".pgm", directories), fileData);
...
编译一下再执行:
prototype@prototype-X299-UD4-Pro:~/Downloads/TensorRT-5.0.2.6/bin$ ./sample_onnx_mnist
----------------------------------------------------------------
Input filename: ../../../data/mnist/mobilenetv2-128.onnx
ONNX IR version: 0.0.3
Opset version: 9
Producer name: pytorch
Producer version: 0.4
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
While parsing node number 154 [Gather -> "481"]:
ERROR: /home/erisuser/p4sw/sw/gpgpu/MachineLearning/DIT/release/5.0/parsers/onnxOpenSource/ModelImporter.cpp:142 In function importNode:
[8] No importer registered for op: Gather
ERROR: failed to parse onnx file
可以发现TensorRT中的ONNX-TensorRT不支持我们这个.onnx中的Gather操作。这时我们可以等待官方更新或者下载ONNX-TensorRT库的源码自己进行修改,然后编译链接即可。
目前TensorRT对ONNX模型的支持程度:

protobuf
protobuf全称为ProtoBuffer,是由Goodle开发的一种可以实现内存与硬盘文件交换的协议接口,说白了就是一种可以我们自己定规则协议的一套工具,我们通过自己编写统一的参数描述文件proto,然后利用protoc编译就能生成可以读取信息的代码,非常方便,其中ONNX的协议就是使用Protobuf开发的。
Protobuf如果在Ubuntu系统中直接下载很容易造成lib库的编译protoc的版本不匹配,这里建议直接通过conda下载libprotobuf然后将其提出来,在之后的编译程序中进行链接(例如我们编译ONNX-TensorRT时如果找不到protobuf,在cmake中添加 -DCMAKE_PREFIX_PATH=/home/prototype/Documents/libprotobuf-3.6.1即可):
一定要安装正确protobuf库,因为无论是ONNX-TensorRT还是TensorRT都需要protobuf的支持。
未完待续
之后会详细讲解如何具体地部署。
参考链接
https://github.com/dusty-nv/jetson-inference
https://blog.csdn.net/arackethis/article/details/43488021