如何搭建量化投资研究系统?(数据篇)
一、量化投资,数据是基础
量化投资的理念现在越来越被人熟知,不论是在学校还是在职场,对量化投资感兴趣,想要一试身手,甚至是将Quant定为职业目标的人也越来越多。不过许多朋友现在还只是临时搜罗有限的数据,做一些零星的研究、测试和计算。与其这样没有明确目标地小打小闹,不如着手建立一个比较完善的“量化投资研究系统”,下面我将和朋友们分享一下我在这方面尝试的心得。
中国有句古话叫做“兵马未动,粮草先行”,对于量化投资研究而言应该改为“模型未动,数据先行”,高质量的数据是出色研究的基础。需求决定功能,我们要做哪方面的量化投资研究,决定了我们需要哪些数据。
我所理解的量化投资研究大致包括3块内容:
- 学术化的研究工作,例如金融时间序列分析,这一块研究主要集中在各种金融产品的交易数据上,例如股票、期货、期权的价格,基金净值等等;
- 构建交易策略或投资组合,这一块研究需要交易数据、宏观经济指标和公司财务数据等等;
- 策略回测,这一块研究需要大量历史交易数据,用来测试评估交易策略和投资组合。
“天下没有免费的午餐”,为了获得数据,要么付出金钱成本,购买数据终端(例如Wind终端);要么付出时间成本,自己动手搭建维护一个金融数据库。如果没有机会摆弄万得、彭博,还是毛主席那句话——“自己动手,丰衣足食”。
信息时代,最大的数据源就是互联网,而且在绝大部分情况下,互联网可以提供公开免费的数据。所以我们要搭建的数据库实际上是依赖“网络爬虫”获取互联网上的数据。不过在讨论如何获取数据之前,为了确保将来的工作简单高效,先要“约法三章”:
- 尽量以下载文件,而不是抓取网页内容的方式获得数据;
- 尽量减少抓取网页的次数,换言之,一张网页上的数据要尽可能的多;
- 尽量抓取静态网页内容,而不是动态网页。(有一个简单的规则区别静态和动态网页,如果网页内容变化之后,地址栏里的URL链接跟着变化,就是静态网页,反之则是动态的。)
二、寻找金融数据源
废话不多说,下面正式讨论如建立自己的金融数据库(目前只限于股票和基金数据)。
首先来到上交所和深交所的网站,目的是找到股票代码和指数代码列表。深交所以文件下载的方式提供股票和指数代码(业界良心),上交所则是以网页形式提供。天天基金网以网页的形式提供了基金代码列表(网址http://www.1234567.com.cn/allfund.html)。

基金代码(天天基金网)
接下来看股票和指数的交易数据,要想获得这些数据,一个最自然的想法就是到主流门户网站上去找。事实上网易、新浪、和讯和东方财富等门户网站都以网页的形式提供每日交易数据。不过网易这一次成为了业界良心,网易提供数据下载服务,可以下载csv文件获得股票和指数的历史交易数据,以及股票最近一周的高频交易数据。网易提供的数据甚至包括除权调整过的昨收数据(妈妈再也不用担心我计算收益率了,真是业界良心啊)。
 历史交易数据(平安银行)
历史交易数据(平安银行)
成交明细(平安银行)
和交易相关的另一种重要数据是“复权因子”,可惜提供复权因子数据的网站并不多,新浪这一次成为了业界良心,新浪以静态网页的形式提供每日的复权因子。

复权因子(平安银行)
基金净值数据,和股票跟指数一样,门户网站大多以网页的形式提供历史净值数据,不过和讯这一次做了业界良心,和讯在基金的历史净值网页上展示了该基金所有的历史净值数据。

基金净值(华夏成长)
一些基本资料层面的数据,例如上市公司的基本资料,基金的基本资料等,对于这些数据,网站之间的大同小异区别不大。
最后看上市公司的财务数据,有些类型的量化投资特别需要研究公司财务数据,尤其是量化选股,需要大量财务数据构造因子,用来对股票估值和预测未来收益率。不过对比多家网站之后,不幸地发现不同网站提供的财务数据格式不尽相同,数据内容也是有出入。这一部分数据的搜集比想象的要复杂得多,将来会专门写一篇文章讨论这个问题,暂时搁置一下。
三、开始搭建金融数据库
通过上面的文章,数据源已经基本确定了,接下来就要“修渠引水,汇入水库”。水库的话,就选择最常用的数据库MySQL;水渠的话,这里用R语言。


前面讲过了,整个数据库依赖网络爬虫获得数据,所以修水渠之前要先掌握下面几个方面的基本知识:
- R的语法,以及如何使用RCurl、XML、xml2等R包设计爬虫;
- 网页的基本结构,以及如何利用FireFox浏览器的FireBug插件或Chrome浏览器研究网页结构;
- 正则表达式;
- XPath语法,以及使用XPath提取html文件中的特定节点。
看起来需要很多的知识准备,不过以我个人的经验,每个方面只要掌握最基本的知识就可以利用R做出一个靠谱的爬虫。如果想要集中时间系统化的学习上述知识,这里推荐两本书《AutomatedData Collection with R》、《XML and WebTechnologies for Data Sciences with R》和一篇网络教程《55分钟学会正则表达式》。


接下来用一个实例演示如何获得数据。
首先,到交易所网站手工收集整理A股的股票代码和指数代码列表,分别保存在文件SH.A.list.txt、SH.IDX.list.txt、SS.A.list.txt、SS.IDX.list.txt中。用R函数readLines读取称为相应的字符串向量,接着构造“市场代码向量”用来标识股票和指数对应的市场,沪市记为0深市记为1,将这些向量组合成数据框(data.frame,R中常用的数据结构,类似excel表格)A.list和IDX.list。
第二步,找到包含所需信息的网页,解析网页链接的模式。
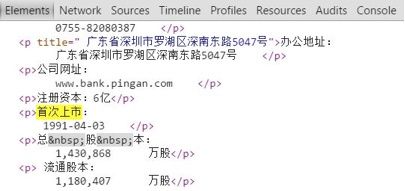
以平安银行为例,现在想要获得股票的首次上市日。网易平安银行的网页链接是http://quotes.money.163.com/1000001.html,1000001中开头的1是市场代码,000001是股票代码。在Chrome中打开网页,按F12打开网页分析工具,找到“首次上市”节点,右键复制XPath,即“/html/body/div[2]/div[22]/div[2]/p[9]”。
在R中运行下面的语句:
# 加载xml2和stringr包
library(xml2)
library(stringr)
# 链接
url <- "http://quotes.money.163.com/1000001.html"
# 读取网页
html <- read_html(url)
# XPath
path <- "/html/body/div[2]/div[22]/div[2]/p[9]"
# 找到“首次上市”节点
date <- xml_find_all(html,
xpath = path)
# 转化成文本
date <- xml_text(date)
date
# 如果乱码,修改编码
Encoding(date) <- "UTF-8"
date
# 用正则表达式提取日期
date <- str_extract(date,
"[0-9]{4}-[0-9]{2}-[0-9]{2}")
date
最后得到date=”1991-04-03”,正是想要的首次上市日期。
如果是下载文件的话,先要通过浏览器获得下载地址,例如

其中蓝色的是市场代码,红色的是股票代码,绿色的是日期,紫色的是数据项。
R中的download.file函数可以用于下载文件,或是借助RCurl中的getBinaryURL函数,并配合使用writeBin函数。在R中运行下面的语句:
url <- "http://quotes.money.163.com/service/chddata.html?
code=1000001&start=19910403&end=20150629&fields=TCLOSE;
HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;
VOTURNOVER;VATURNOVER;TCAP;MCAP"
# 方法一
download.file(url,
destfile = "000001.csv")
# 方法二
file <- getBinaryURL(url)
writeBin(file,
con = "000001.csv")
就可以下载平安银行的历史交易数据。
在成功获得数据,并保存到若干csv、txt文件之后,最后一步就是导入数据库MySQL。借助R包RMySQL,可以实现R和MySQL的连接,在R环境中直接操作MySQL数据库。
# 载入RMySQL包
library(RMySQL)
# 建立数据库连接
conn <- dbConnect(MySQL(),
dbname = "数据库名",
username = "用户名",
password = "密码")
# 启动非严格模式
dbSendQuery(conn,
"SET @@sql_mode=ANSI;")
# win7环境下如果汉字乱码,就运行这条命令
dbSendQuery(conn,
"SET NAMES GBK")
将文件中的数据导入数据库可以使用下面的R命令:
sql <- "load data infile ‘文件名’
into table 表名
character set GBK
fields terminated by ','
lines terminated by '\r\n';"
dbSendQuery(conn, sql)
至此,金融数据库从无到有。未来数据库的维护工作可以安排在周末,利用一个下午的时间,运行R程序获取这一周新增的数据,并导入MySQL。在实际操作中,建库和维护会遇到很多琐碎的细节问题,比如说网页编码、股票退市、新发股票、网站出现故障、表的设计等等,这里不能展开来讲,只能在动手的过程中自己摸索,具体问题具体分析具体解决。