hadoop基础集群的安装
说明:该文章以4台centos系统为案例配置hadoop基础集群,节点名字分别为hadoop02,hadoop03,hadoop04,hadoop05
1.基础集群环境准备
1.1修改主机名
在root用户下:vi /etc/sysconfig/network
或者如何配置了hadoop账户的sudo权限,则在hadoop登陆情况下使用命令 sudo vi/etc/sysconfig/network
修改里面的HOSTNAME=hadoop02 保存退出
1.2设置系统默认启动级别
在root用户下 vi/etc/inittab 改默认启动级别为3
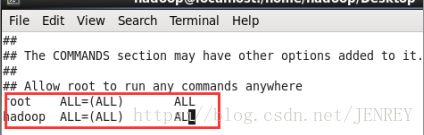
1.3配置hadoop用户sudoer权限
在root用户下输入 vi/etc/sudoers
1.4配置IP地址
1.5关闭防火墙和Selinux
查看防火墙状态 service iptables status
关闭防火墙 service iptables stop
开启防火墙 service iptables start
重启防火墙 service iptables restart
关闭防火墙开机启动 chkconfig iptables off
开启防火墙开机启动 chkconfig iptables on
关闭Selinux vim /etc/selinux/config 配置文件中的SELINUX=disabled
1.6添加内网域名映射
vi /etc/hosts
格式为
192.168.123.102 hadoop02
192.168.123.103 hadoop03
192.168.123.104 hadoop04
192.168.123.105 hadoop05
1.7安装JDK
先查看系统自带的jdk
rpm -qa |grep jdk
再卸载系统自带jdk
rpm -e --nodeps java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
上传jdk-8u73-linux-x64.tar.gz(使用SecureCRT软件,Alt+P,拖拽文件进行上传)
tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr/local
配置环境变量 vi /etc/profile
在最后两行加入
export JAVA_HOME=/usr/local/jdk1.8.0_73
export PATH=$PATH:$JAVA_HOME/bin
保存退出
刷新环境变量 source /etc/profile
检查是否安装成功 java -version
1.8同步服务器时间
ntpdate 202.120.2.101
1.9配置免密登陆
打开SecureCRT软件如图所示进行配置
右键调出该模式

先使用 ssh-keygen 生成秘钥
此时会在/home/hadoop/.ssh 目录下生成了公钥文件
使用 下图命令
ssh-copy-id hadoop02
ssh-copy-id hadoop03
ssh-copy-id hadoop04
ssh-copy-id hadoop05
2.Hadoop集群环境安装
2.1创建apps文件夹便于管理
mkdir /home/hadoop/apps
2.2上传hadoop安装包(本文以hadoop-2.7.5-centos-6.7.tar.gz为例)
2.3解压缩hadoop安装包
tar -zxvf hadoop-2.7.5-centos-6.7.tar.gz -C ~/apps/
2.4进入配置文件所在目录
cd /home/hadoop/apps/hadoop-2.7.5/etc/hadoop
2.5修改 hadoop-env.sh 文件
修改JAVA_HOME
把 export JAVA_HOME=${JAVA_HOME}
改成 export JAVA_HOME=/usr/local/java/jdk1.8.0_73
2.6 修改core-site.xml 文件
2.7修改hdfs-site.xml
2.8修改mapred-site.xml文件(把mapred-site.xml.template改名为mapred-site.xml)
先使用 mv mapred-site.xml.template mapred-site.xml进行改名
2.9修改 yarn-site.xml 文件
2.10修改 slaves 文件(非必须项)
hadoop02
hadoop03
hadoop04
hadoop05
2.11 分发hadoop文件
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致!!!
scp -r hadoop-2.7.5/ hadoop@hadoop03:~/apps/
scp -r hadoop-2.7.5/ hadoop@hadoop04:~/apps/
scp -r hadoop-2.7.5/ hadoop@hadoop05:~/apps/
2.12 配置环境变量
如果你使用root用户进行安装。 vi /etc/profile 即可 系统变量
如果你使用hadoop用户进行安装。 vi ~/.bashrc 用户变量
刷新环境变量 source .bashrc
2.13 初始化hadoop
只能在HDFS的主节点进行
hadoop namenode -format
2.14 启动
启动HDFS : 不管在集群中的那个节点都可以
start-dfs.sh
启动YARN : 只能在YARN主节点中进行启动
start-yarn.sh
2.15 检测 或者 验证是否成功
jps 命令 查看 对应的守护进行是否都启动成功
HDFS : http://hadoop02:50070
YARN : http://hadoop05:8088
2.16简单实用
HDFS :
上传文件:~/apps/hadoop-2.7.5/bin/hadoop fs -put zookeeper.out /
下载文件:~/apps/hadoop-2.7.5/bin/hadoop fs -get /zookeeper.out
YARN :
假如现在有一个文件: /wc/input/words.txt
hello huangbohello xuzheng
hello wangbaoqiang
~/apps/hadoop-2.7.5/bin/hadoop fs -mkdir -p /wc/input
运行一个mapreduce的例子程序: wordcount
命令:
~/apps/hadoop-2.7.5/bin/hadoop jar ~/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /wc/input /wc/output
查看最终结果:
~/apps/hadoop-2.7.5/bin/hadoop fs -cat /wc/output/part-r-00000