使用集成学习构建机器学习预测模型
前段时间参加了一家量化投资公司的面试,其中用了集成学习算法,发现效果很好,现在将代码公布出来,以便小白学习,大神请绕道!!!
原问题:请结合附件Excel表中的数据完成下列问题:
模型
1)以投资金额为目标变量建立一个线性模型。
2)以投资金额高低区分高投资与低投资用户,以此为目标变量建立逻辑回归模型。
3)以投资金额高低区分高投资与低投资用户,以此为目标变量建立一至两个机器学习模型(GBM, Random Forrest, Neural Network, SVM 等等)
附加了集成学习算法以此来提高模型性能
——————————————————–
可以看出问题是一个二分类的问题,本教程教你如何利用机器学习算法对用户分类-以人人贷数据为例,亮点主要是集成学习算法,废话不多说,直接上干货。
首先源数据长这样
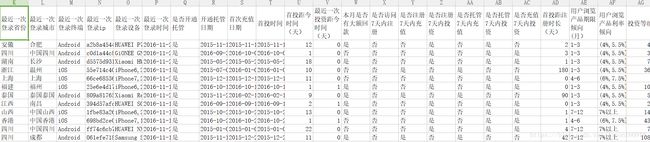
可以看出数据清洗还挺复杂的,别慌,我们慢慢来!
#导入所用的工具包
import pandas as pd
import numpy as np
import redata=pd.read_excel(r"./模型算法-02-Quantum One 面试数据集.xlsx")#读取数据,后面有数据链接SEED=123#设立随机种子以便结果复现
np.random.seed(SEED)data.info()#查看数据基本信息运行可以得到以下结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5000 entries, 0 to 4999
Data columns (total 33 columns):
用户id 5000 non-null object
投资金额 5000 non-null float64
年龄 5000 non-null int64
性别 5000 non-null object
手机省份 4994 non-null object
手机城市 4994 non-null object
注册时间 5000 non-null object
用户注册终端 5000 non-null object
用户注册渠道 670 non-null object
会员级别 5000 non-null object
最近一次登录省份 4982 non-null object
最近一次登录城市 4982 non-null object
最近一次登录终端 4995 non-null object
最近一次登录ip 4982 non-null object
最近一次登录设备 4018 non-null object
最近一次登录时间 4995 non-null object
是否开通托管 5000 non-null object
开通托管日期 4999 non-null object
首次充值日期 4990 non-null object
首投时间 4986 non-null object
首投距今时间(天) 4986 non-null float64
最近一次投资距今时间(天) 4986 non-null float64
本月是否有大额回款 5000 non-null object
是否访问7天内注册 5000 non-null object
是否注册7天内充值 5000 non-null object
是否注册7天内投资 5000 non-null object
是否托管7天内充值 5000 non-null object
是否托管7天内投资 5000 non-null object
是否充值7天内投资 5000 non-null object
首投距注册时长(天) 4986 non-null float64
用户浏览产品期限倾向(月) 4220 non-null object
用户浏览产品利率倾向 4221 non-null object
投资等级 5000 non-null int64
dtypes: float64(4), int64(2), object(27)
memory usage: 1.3+ MB可以看出,样本量是5000行,30个变量,大部分变量都有缺失值,有27个object对象,之后要对这些非数值变量进行量化处理才行。
data=data.drop(["最近一次登录ip","用户注册渠道"],axis=1)#考虑到用户注册渠道变量缺失值太多,直接删除,然后最近一次登录IP没有对它解析,这个也暂时删除掉。data=data.fillna(method='pad')#填补缺失值,用的是pad平滑数据的方法,一定要记得加method=哦,要不然有时候会把pad当做字符串填进去的data.info()#再次查看数据信息,缺失值填充完毕<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5000 entries, 0 to 4999
Data columns (total 31 columns):
用户id 5000 non-null object
投资金额 5000 non-null float64
年龄 5000 non-null int64
性别 5000 non-null object
手机省份 5000 non-null object
手机城市 5000 non-null object
注册时间 5000 non-null object
用户注册终端 5000 non-null object
会员级别 5000 non-null object
最近一次登录省份 5000 non-null object
最近一次登录城市 5000 non-null object
最近一次登录终端 5000 non-null object
最近一次登录设备 5000 non-null object
最近一次登录时间 5000 non-null object
是否开通托管 5000 non-null object
开通托管日期 5000 non-null object
首次充值日期 5000 non-null object
首投时间 5000 non-null object
首投距今时间(天) 5000 non-null float64
最近一次投资距今时间(天) 5000 non-null float64
本月是否有大额回款 5000 non-null object
是否访问7天内注册 5000 non-null object
是否注册7天内充值 5000 non-null object
是否注册7天内投资 5000 non-null object
是否托管7天内充值 5000 non-null object
是否托管7天内投资 5000 non-null object
是否充值7天内投资 5000 non-null object
首投距注册时长(天) 5000 non-null float64
用户浏览产品期限倾向(月) 5000 non-null object
用户浏览产品利率倾向 5000 non-null object
投资等级 5000 non-null int64
dtypes: float64(4), int64(2), object(25)
memory usage: 1.2+ MB连续数据离散化
#用describe方法查看哪些变量需要离散化,一般是float对象都需要离散化
data[["年龄","投资等级","首投距今时间(天)","最近一次投资距今时间(天)","首投距注册时长(天)","投资金额"]].describe()得到以下结果:
年龄 投资等级 首投距今时间(天)最近一次投资距今时间(天)首投距注册时长(天)投资金额
count 5000.000000 5000.000000 5000.000000 5000.000000 5000.000000 5.000000e+03
mean 40.943400 195.278000 8.769400 0.506800 34.208800 1.955289e+05
std 11.532042 703.234875 6.502452 0.887531 89.600659 7.032177e+05
min 10.000000 0.000000 0.000000 0.000000 0.000000 7.200000e+02
25% 32.000000 36.000000 2.000000 0.000000 0.000000 3.600000e+04
50% 40.000000 72.000000 8.000000 0.000000 2.000000 7.200000e+04
75% 48.000000 144.000000 14.000000 1.000000 13.250000 1.440000e+05
max 87.000000 29880.000000 23.000000 18.000000 689.000000 2.988000e+07考虑采用四分位数划分的方法进行离散化,划分为4类
将用abcd代替四分类,0到25%=a,25%到50%=b,以此类推
def split0(x,col):
if np.percentile(col,25)>x>=min(col):
x="a"
elif np.percentile(col,50)>x>=np.percentile(col,25):
x="b"
elif np.percentile(col,75)>x>=np.percentile(col,50):
x="c"
else:
x="d"
return x #不能少
for y in ["年龄","投资等级","首投距今时间(天)","最近一次投资距今时间(天)","首投距注册时长(天)"]:
data[y]=data[y].apply(lambda x:split0(x,data[y]))将变量名含有“是否”用正则化匹配出来,并将取值为是否替换为1和0,为了下一步哑变量处理,但后来博主发现,并不需要用01代替,算法会自动识别:)
for i in data.columns:
if re.search("是否",i):
data[i]=data[i].map({"是":1,"否":0})将变量名含有“时间和日期”用正则化匹配出来,并将其取值包含2015和2016字符替换为1和0
def match_col(x):
if re.search("2015",x):
x=0
elif re.search("2016",x):
x=1
else:pass
return x
for i in data.columns:
if re.search('日期',i) or re.search('时间',i):
data[i]=data[i].apply(lambda x: match_col(x))
print("匹配了这些列",i)匹配了这些列 注册时间
匹配了这些列 最近一次登录时间
匹配了这些列 开通托管日期
匹配了这些列 首次充值日期
匹配了这些列 首投时间
匹配了这些列 首投距今时间(天)
匹配了这些列 最近一次投资距今时间(天)
将登录设备列也进行处理,以便后续分析,把所有苹果手机分为一类,所有小米手机分为一类,以此类推
def split2(x):
if re.search("iphone",x):
x="a"
elif re.search("HUAWEI",x):
x="b"
elif re.search("Xiaomi",x):
x="c"
else:x="d"
return x
data["最近一次登录设备"]=data["最近一次登录设备"].apply(split2)提取目标变量并命名为Y
Y=data.pop("投资金额")
#为了后面用梯度下降法计算w,所以这里需要reshape为2维
Y=pd.DataFrame(Y.values.reshape((5000,1)))数据清洗完毕之后,将除用户id之外的所有变量进行哑变量处理,目的是将不能够定量处理的变量量化
X=pd.get_dummies(data[data.columns.drop("用户id")])接下来针对第一问求解线性模型
X=X.add(np.ones(len(X)),axis=0)#增加偏置列,默认为1
def scale(x):#进行数据标准化,防止过拟合
x=(x-x.mean())/(x.std()+0.0001)
return x
X=X.apply(scale,axis=0)from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=SEED)#划分数据集建立线性回归模型,由于输入数据是奇异矩阵,不可逆,所以直接求w无效,采取利用随机梯度下降算法求近似解
更新方式如下:
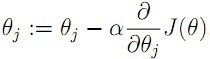
更新公式为:

def linear_regression_by_gd(X, Y, gamma=0.000001, eps=0.0001, max_iter=100): #梯度下降求线性回归
pre_w = np.array(np.ones((X.shape[1], 1)))
cur_w = np.array(np.zeros((X.shape[1], 1)))
count = 1
while (cur_w - pre_w).T.dot(cur_w - pre_w) > eps and count < max_iter:
pre_w = cur_w
cur_w = cur_w - np.array(gamma / np.sqrt(count) * X.T.dot( X.dot(cur_w) - Y))
count += 1
return cur_w求得线性模型的系数W
w = linear_regression_by_gd(x_train, y_train)以投资金额超过该值的中位数设为高投资用户
以投资金额不超过该值的中位数设为低投资用户
以此为目标变量建立逻辑回归模型
import os
import numpy as np
if __name__ == "__main__":
print ("linear regression")
print ("\t training start ...")
threshold = Y.median()
gamma, eps, max_iter = 0.01, 0.001, 10
print ("\t training done !")
train_y_predict = x_train.dot(w)
test_y_predict = x_test.dot(w)
print ("\t train predict error\t: %f"%(sum( abs( (2**(train_y_predict > threshold) - 1) - (2**(y_train > threshold) -1) ))/ (len(y_train) + 0.0)))
print ("\t test predict error \t: %f"%(sum( abs( (2**(test_y_predict > threshold) - 1) - (2**(y_test > threshold) - 1) )) / (len(y_test) + 0.0)))#打印收敛时的权重W
print(w)y_train=2**(y_train > Y.median()) -1#将连续目标变量转换为2分类变量,median表示中位数值
y_train1 = np.ravel(y_train)
y_test=2**(y_test > Y.median()) -1
y_test1 = np.ravel(y_test)构造多个机器学习模型进行集成,思路是定义一些基学习器和一个元学习器,如下图所示:
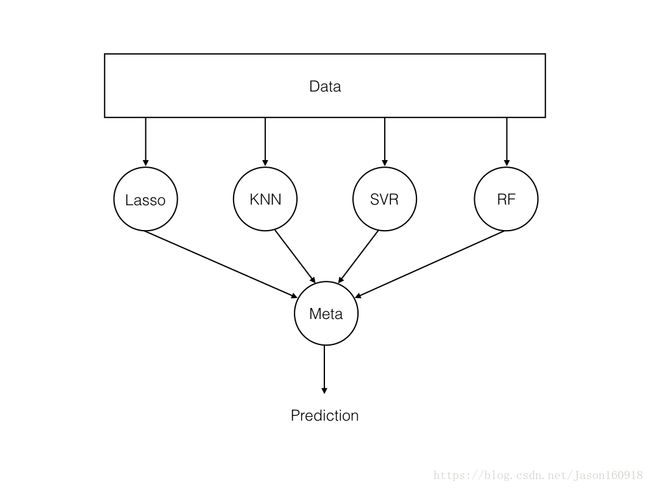
基学习器如下:
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
import lightgbm as lgb_model
def get_models():
#"""Generate a library of base learners."""
nb = GaussianNB()#朴素贝叶斯
svc = SVC(C=1,random_state=SEED,kernel="linear" ,probability=True)#kernel选用线性最好,因为kerenl太复杂容易过拟合,支持向量机
knn = KNeighborsClassifier(n_neighbors=3)#K近邻聚类
lr = LogisticRegression(C=100, random_state=SEED)#逻辑回归
nn = MLPClassifier((80, 10), early_stopping=False, random_state=SEED)#多层感知器
gb = GradientBoostingClassifier(n_estimators=100, random_state=SEED)#GDBT
rf = RandomForestClassifier(n_estimators=10, max_features=3, random_state=SEED)#随机森林
etree=ExtraTreesClassifier(random_state=SEED)#etree
adaboost=AdaBoostClassifier(random_state=SEED)#adaboost
dtree=DecisionTreeClassifier(random_state=SEED)#决策树
lightgbmlgb=lgb_model.sklearn.LGBMClassifier(is_unbalance=False,learning_rate=0.04,n_estimators=110,max_bin=400,scale_pos_weight=0.8)#lightGBM,需要安装lightGBM,pip3 install lightGBM
models = {
'svm': svc,
'knn': knn,
'naive bayes': nb,
'mlp-nn': nn,
'random forest': rf,
'gbm': gb,
'logistic': lr,
'etree': etree,
'adaboost': adaboost,
'dtree': dtree,
'lgb': lgb,
}
return models
def train_predict(model_list):#预测
"""将每个模型的预测值保留在DataFrame中,行是每个样本预测值,列是模型"""
P = np.zeros((y_test.shape[0], len(model_list)))
P = pd.DataFrame(P)
print("Fitting models.")
cols = list()
for i, (name, m) in enumerate(model_list.items()):
print("%s..." % name, end=" ", flush=False)
m.fit(x_train, y_train1)
P.iloc[:, i] = m.predict(x_test)
cols.append(name)
print("done")
P.columns = cols
print("ALL model Done.\n")
return P
def score_models(P, y):#打印AUC值
#"""Score model in prediction DF"""
print("Scoring AUC的值models.")
for m in P.columns:
score = roc_auc_score(y, P.loc[:, m])
print("%-26s: %.3f" % (m, score))
print("Done.\n")查看其模型预测AUC分数
from sklearn.metrics import roc_auc_score
base_learners = get_models()
P = train_predict(base_learners)
score_models(P, y_test1)查看各个模型结果之间的相关性,相关性低的话集成的效果越好
from mlens.visualization import corrmat
import matplotlib.pyplot as plt
corrmat(P.corr(), inflate=False)
plt.show()得出以下结果
Scoring models.
svm : 0.888
knn : 0.585
naive bayes : 0.832
mlp-nn : 0.838
random forest : 0.750
gbm : 0.902
logistic : 0.870
etree : 0.891
adaboost : 0.888
dtree : 0.882
lgb : 0.896
Done.可以发现各个模型的AUC值都较高,超过了0.5,其实可以删除KNN,因为其效果太差,博主懒,没有删除:)
可以得出以下相关矩阵图

发现有部分模型之间的相关性较弱,考虑集成学习以提高精度,baseline为上述模型的最大值,为0.902,我们的目标是集成之后的准确率超过baseline
定义元学习器GBDT
meta_learner = GradientBoostingClassifier(
n_estimators=1000,
loss="exponential",
max_features=3,
max_depth=5,
subsample=0.8,
learning_rate=0.05,
random_state=SEED
)meta_learner.fit(P, y_test1)#用基学习器的预测值作为元学习器的输入,并拟合元学习器,元学习器一定要拟合,不然无法集成。输出如下:
GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.05, loss='exponential', max_depth=5,
max_features=3, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=1000,
presort='auto', random_state=123, subsample=0.8, verbose=0,
warm_start=False)利用stacking集成学习算法进行集成,stacking算法如下:
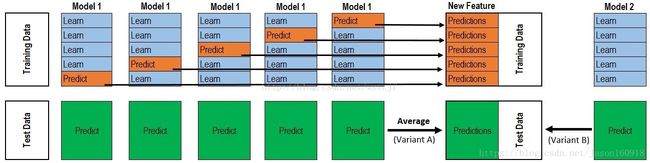
定义一个超级学习器Superlearner,需要首先安装集成学习包mlens—pips3 install mlens
from mlens.ensemble import SuperLearner
#5折集成
sl = SuperLearner(
folds=5,
random_state=SEED,
verbose=2,
backend="multiprocessing"
)
sl.add(list(base_learners.values()), proba=True) # 加入基学习器
sl.add_meta(meta_learner, proba=True)# 加入元学习器
# 训练集成模型
sl.fit(x_train[:1000], y_train1[:1000])
# 预测
p_sl = sl.predict_proba(x_test)
print("\n超级学习器的AUC值: %.3f" % roc_auc_score(y_test1, p_sl[:, 1]))可以得到以下输出
[MLENS] backend: threading
[MLENS] Found 1 residual cache(s):
1 (4096): C:\Users\ADMINI~1\AppData\Local\Temp\.mlens_tmp_cache_286mdeqo
Total size: 4096
[MLENS] Removing... done.
Processing layer-1 done | 00:00:37
Processing layer-2 done | 00:00:01
Fit complete | 00:00:38
Predicting 2 layers
Processing layer-1 done | 00:00:04
Processing layer-2 done | 00:00:00
Predict complete | 00:00:05
超级学习器的ROC-AUC值: 0.9660.966远大于0.902,表明集成模型性能表现不错
画ROC曲线对模型性能进行比较
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
#画roc曲线
def plot_roc_curve(ytest, P_base_learners, P_ensemble, labels, ens_label):
"""Plot the roc curve for base learners and ensemble."""
plt.figure(figsize=(10, 8))
plt.plot([0, 1], [0, 1], 'k--')
cm = [plt.cm.rainbow(i)
for i in np.linspace(0, 1.0, P_base_learners.shape[1] + 1)]
for i in range(P_base_learners.shape[1]):
p = P_base_learners[:, i]
fpr, tpr, _ = roc_curve(ytest, p)
plt.plot(fpr, tpr, label=labels[i], c=cm[i + 1])
fpr, tpr, _ = roc_curve(ytest, P_ensemble)
plt.plot(fpr, tpr, label=ens_label, c=cm[0])
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.legend(loc="lower right",frameon=False)
plt.show()plot_roc_curve(y_test1, P.values, p_sl[:,1], list(P.columns), "Super Learner")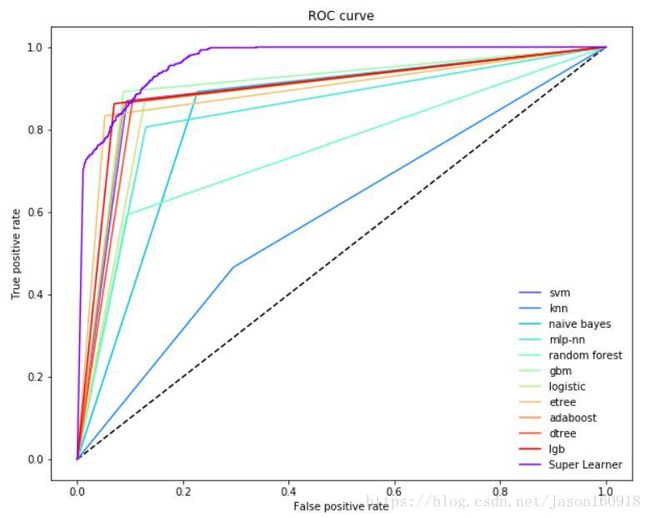
可以看出Superlearner的性能最佳,至此集成完毕,效果非常不错!下一步考虑将深度学习模型进行集成。
数据连接:https://pan.baidu.com/s/10dchvkOsPqAcPsPe5lv76A 密码:vzww