hadoop集群安装及测试
在低配置虚拟机环境下测试安装hadoop集群环境。
1、集群实现准备
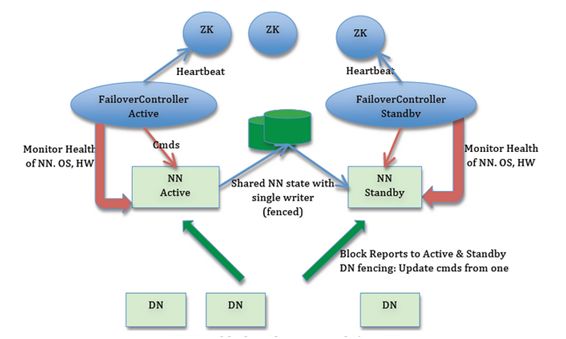
1.1 集群实现思路
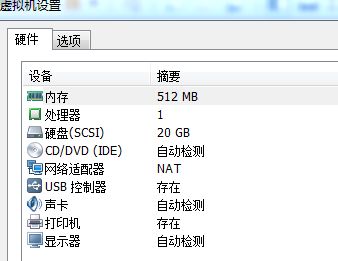
1.2 虚拟机配置
建议配置:1G内存,2个CPU
由于测试机器配置有限,实际设置4台虚拟机,每台分配512M内存,1个CPU
1.3 集群节点分配
为避免单点故障,NameNode 、ResourceManager均配置热备节点
Park01
Zookeeper
NameNode (active)
ResourceManager (active)
Park02
Zookeeper
NameNode (standby)
Park03
Zookeeper
ResourceManager (standby)
Park04
DataNode
NodeManager
JournalNode
Park05
DataNode
NodeManager
JournalNode
2、具体安装步骤
2.1 克隆5台虚拟机,做好下列步骤
1、安装好jdk,版本:jdk1.8.0_65
2、lrzsz:方便从本机上传软件到虚拟机
3、配置固定ip:避免自动获取ip,在虚拟机重启后分配不同的ip地址
192.168.226.151
192.168.226.152
192.168.226.153
192.168.226.154
192.168.226.155
4、远程客户端配置对应的连接,可用scrt、xshell等
2.2 永久关闭每台机器的防火墙
service iptables stop
chkconfig iptables off(重启后有效)
2.3 设置每台机器的主机名和host文件
NETWORKING=yes
HOSTNAME=hadoop01
NETWORKING=yes
HOSTNAME=hadoop02
NETWORKING=yes
HOSTNAME=hadoop03
NETWORKING=yes
HOSTNAME=hadoop04
NETWORKING=yes
HOSTNAME=hadoop04
[root@hadoop05 ~]# cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop04
127.0.0.1 localhost
::1 localhost
192.168.226.151 hadoop01
192.168.226.152 hadoop02
192.168.226.153 hadoop03
192.168.226.154 hadoop04
192.168.226.155 hadoop05
2.4 每台机器配置ssh免秘钥登录
例如:hadoop01上执行(其他机器相同操作)
ssh-keygen
ssh-copy-id -i root@hadoop01 (分别发送到4台节点上)
2.5 在hadoop01、hadoop02、hadoop03上安装zookeeper及配置
1、上传并解压zookeeper, zookeeper-3.4.7.tar.gz2、在conf目录下拷贝配置文件
[root@hadoop01 conf]# cp zoo_sample.cfg zoo.cfg
3、修改配置文件zoo.cfg,设置以下内容:
dataDir=/usr/soft/zookeeper-3.4.7/tmp
server.1=192.168.226.151:2888:3888
server.2=192.168.226.152:2888:3888
server.3=192.168.226.153:2888:3888
4、创建tmp目录,并在其下设置myid文件
创建tmp目录
/usr/soft/zookeeper-3.4.7/tmp
设置myid文件内容如下:
1
5、将zookeeper程序文件打包,并scp到另外两台机器(hadoop02、hadoop03)的/usr/soft目录下
[root@hadoop01 soft]# tar -zcvf zookeeper-3.4.7.tar.gz zookeeper-3.4.7
[root@hadoop01 soft]# scp zookeeper-3.4.7.tar.gz root@hadoop02:/usr/soft
6、在hadoop02、hadoop03下的/usr/soft目录下解压,并修改myid文件内容,分别为2、3
2.6 在hadoop01上安装及配置hadoop程序
1、上传hadoop文件及解压,hadoop-2.7.1.tar.gz。配置文件路径,hadoop目录下的etc/hadoop目录
2、配置hadoop-env.sh,设置jdk及hadoop配置文件目录
export JAVA_HOME=/usr/soft/jdk1.8.0_65
export HADOOP_CONF_DIR=/usr/soft/hadoop-2.7.1/etc/hadoop
3、配置core-site.xml
4、配置hadoop01节点的hdfs-site.xml
5、配置mapred-site.xml
6、配置yarn-site.xml
7、配置slaves文件
hadoop04
hadoop05
8、配置hadoop的环境变量/etc/profile
export JAVA_HOME=/usr/soft/jdk1.8.0_65
export HADOOP_HOME=/usr/soft/hadoop-2.7.1
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
9、根据配置文件创建相关文件夹
创建journal目录
[[email protected]]# mkdir journal
创建tmp目录,并在其下创建namenode、datanode目录
[root@hadoop01 hadoop-2.7.1]# mkdir -p tmp/namenode tmp/datanode
10、打包、压缩hadoop程序文件,并通过scp发送到其他3台机器/usr/soft目录
[root@hadoop01 soft]# tar -zcvf hadoop-2.7.1.tar.gz hadoop-2.7.1
[root@hadoop01 soft]# scp hadoop-2.7.1.tar.gz root@hadoop02:/usr/soft
11、在另外3台机器解压hadoop程序文件
[root@hadoop02 soft]# tar -zxvf hadoop-2.7.1.tar.gz
[root@hadoop03 soft]# tar -zxvf hadoop-2.7.1.tar.gz
[root@hadoop04 soft]# tar -zxvf hadoop-2.7.1.tar.gz
[root@hadoop05 soft]# tar -zxvf hadoop-2.7.1.tar.gz
12、将hadoop01下的环境变量配置文件/etc/profile发送给其他3台机器,并通过source使其生效
[root@hadoop01 soft]# scp /etc/profile root@hadoop02:/etc
[root@hadoop01 soft]# scp /etc/profile root@hadoop03:/etc
[root@hadoop01 soft]# scp /etc/profile root@hadoop04:/etc
[root@hadoop01 soft]# scp /etc/profile root@hadoop05:/etc
3、启动hadoop集群
3.1 启动zookeeper
1、在hadoop01、hadoop02、hadoop03节点的zookeeper安装目录的bin目录下,启动
[root@hadoop01 bin]# ./zkServer.sh start
检查启动状态
[root@hadoop01 bin]# ./zkServer.sh status
2、在zookeeper集群上生成ha节点(ns节点)
在zookeeper集群的leader节点,执行
[root@hadoop02 bin]# hdfs zkfc -formatZK

注:3.3--3.5步可以用一步来替代:进入hadoop安装目录的sbin目录,执行:start-dfs.sh
3.2 启动journalnode集群
1、在hadoop04上的hadoop安装目录的sbin目录下执行,
sh hadoop-daemons.sh start journalnode

3.3 启动namenode节点
1、格式化hadoop01节点的namenode
[root@hadoop01 bin]# hadoop namenode -format

2、启动hadoop01节点的namenode
[root@hadoop01 bin]# hadoop-daemon.sh start namenode

3、把hadoop02节点的 namenode节点变为standbynamenode节点
在hadoop02节点上执行:
[root@hadoop02 bin]# hdfs namenode -bootstrapStandby

4、启动hadoop02节点的namenode
[root@hadoop02 bin]# hadoop-daemon.sh start namenode

3.4 启动datanode节点
1、启动hadoop04、hadoop05节点的datanode节点
[root@hadoop04 sbin]# hadoop-daemon.sh start datanode

[root@hadoop05 sbin]# hadoop-daemon.sh start datanode

3.5 启动zkfc(启动FalioverControllerActive)
1、在hadoop01,hadoop02节点上执行:hadoop-daemon.sh start zkfc


3.6 启动ResourceManager
1、在hadoop01节点上启动主ResourceManager
[root@hadoop01 bin]# start-yarn.sh

同时hadoop04、hadoop05节点上同时自动启动nodemanager

2、在hadoop03节点上启动副ResourceManager
[root@hadoop03 bin]# yarn-daemon.sh start resourcemanager

4、测试
4.1 测试namenode节点
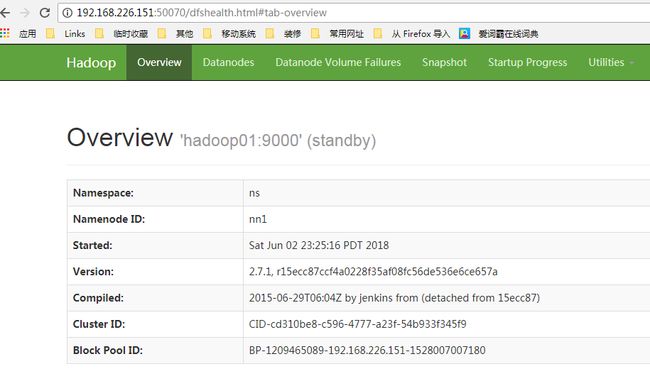
1、输入地址:http://192.168.226.151:50070/
standby状态?
2、输入地址:http://192.168.226.152:50070/
active状态?
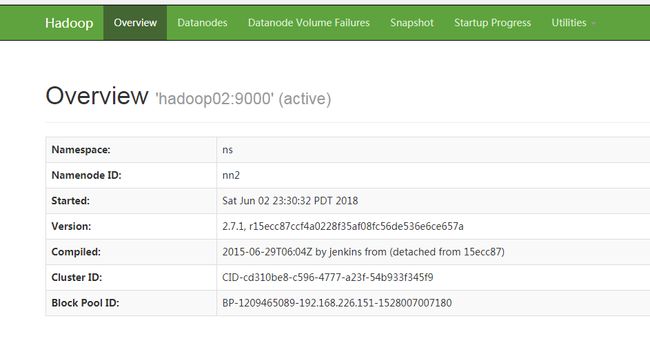
3、停止hadoop02机器的namenode节点
[root@hadoop02 bin]# hadoop-daemon.sh stop namenode
hadoop01的namenode节点状态,变为active

4、再次启动hadoop02机器的namenode节点
[root@hadoop02 bin]# hadoop-daemon.sh start namenode
hadoop02的namenode节点状态,变为standby
4.2 测试resourcemanager节点
1、查看hadoop01机器的,resourcemanager节点
http://192.168.226.151:8088/
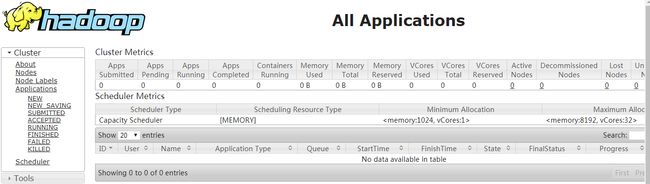
此时,hadoop03机器的resourcemanager节点无法访问
2、停止hadoop01机器的resourcemanager节点
[root@hadoop01 bin]# yarn-daemon.sh stop resourcemanager
此时,resourcemanager节点切换到hadoop03上,hadoop01节点无法访问
4.3 查看hadoop使用情况
使用hadoop dfsadmin -report查看使用情况
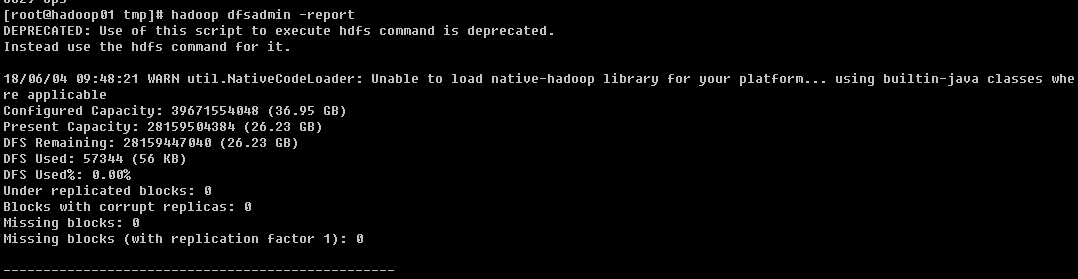


4.4 疑问
开始时将hadoop01节点设置为namenode主节点,但是测试时,却为standby状态?
5、排错
1、排查防火墙
2、排查ip,如果不是固定ip的话,要看下ip是否被更换
3、主机名
4、hosts ip和主机名是否对应上
5、排查zk的配置文件
6、 排查 hadoop 的配置文件