【爬虫】python爬取微信公众号文章
背景:利用代理池爬取微信公众号文章并保存
架构:
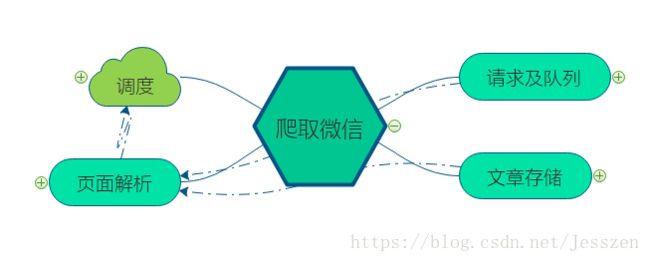
巨坑:实例的名不可于类的名重复。
第一:请求及请求队列

1、为什么要创建weixinrequest()?
因为Sogou微信搜索反爬虫能力强,response.status_code容易出现302,也就是需要输入验证码。当然解决这个问题有两个途径,一个是调用验证码自动识别,另一个是将该302连接重新放回请求队列,更好代理继续。
继承requests库的request类,创建一个weixinququest类,主要添加额为四个属性,callback、need_proxy,failtime,timeout。callback实现每个连接的回调对应方法解析,needproxy是否需要代理,failtime,允许失败的最大次数,已经连接最大响应时间。
from requests import Request
from config import *
class weixinrequest(Request):
"""
super().__init__(a,b,c)继承类时,当子类重写init方法,遇到和父类同样的属性。直接显示引用属性
(a,b,c)中的abc为子类init()中传入的参数,且传入的参数要与要父类中属性先后顺序一致。
"""
def __init__(self,url,callback,method='GET',headers=None,need_proxy=False,fail_time=0,timeout=TIMEOUT):
super(weixinrequest,self).__init__(method,url,headers)#显示调用指定父类init这个三个属性,其他父类属性则相当于丢弃!!这三个属性,要和源码中属性出现的顺序对应
self.callback=callback
self.need_proxy=need_proxy
self.fail_time=fail_time
self.timeout=timeout
2、请求怎么保存?
每一个链接对应一个请求,我们要实现请求的放回,所有需要一个存储结构保存请求,选用了redis数据库中的列表形式来实现。基于redist列表创建一个redisqueue类,此外,由于redis的列表只允许插入字符性数据,所有需要把请求【weixinrequest实例】序列化,应用到pickle的两个函数,dumps序列化;取出后loads反序列化。
该类主要实现的三个方法:a、请求添加到队列:db.rpush(redis_key,dumps(wexrequest)),如果对应的列表redis_key不存 在,则新建一个列表
b、请求队列取出:loads(db.lpop(redis_key))从列表【redis_key】左侧取出一个队列,并反序列化
c、请求队列是否为空:db.llen(redis_key)
class RedisQueue():
"""
反爬虫,我们把需要爬去的request(默认的,包含url,headers,mehtod请求方式get,等等
我们又新加了几个属性,是否需要代理,爬取失败次数,该请求的回调等)
重点!!!每定义方法都要return 对应的结果
"""
def __init__(self,host=Redis_host,password=Redis_password,port=REdis_port):
self.db=redis.StrictRedis(port=port,host=host,password=password)
def add(self,request):
"""
向队列添加符合weixinrequest的信心
redis的列表形式添加
:param request:
:return:
"""
if isinstance(request,weixinrequest):
return self.db.rpush(Redis_key,dumps(request))#向队列添加序列化的request 因为redis的列表只接受字符串形式,而我们的weixinrequest类似字典的结构
else: #如果db.lpush列表Redis_key不存在,则新建一个名称Redis_key的空列表
return False
def pop(self):
"""
从redis队列中取出请求
:return:
"""
if self.db.llen(Redis_key):#这个列表名Redis_key是从config引用过来的
return loads(self.db.lpop(Redis_key)) #从队列头部第一个元素值,并在列表中删除该元素值
else:
return False
def clear(self):
self.db.delete(Redis_key)#删除列表
def empty(self):
return self.db.llen(Redis_key) == 0#返回列表是否为空第二:文章保存

保存到mysql数据库中,传统的关系型数据库,所有事先创建数据库,表,字段设置。
然后,定义一个对应的mysql1()类,实现文章的insert语句。
一个技巧是,我们用占位符来表示,避免拼接字符串。
坑:re正则表达式,匹配的结果可能是个列表【网页的部分信息以script形式加载,传统的xpath或者pyquery解析不到】
import MySQLdb
from config import *
class mysql():
"""
定义了个mysql的链接,和db中的redis类不同的是,我们保存到mysql中,没有在读取出来,所有定义的方法很少,也没有定义拿出来的方法
"""
def __init__(self):
try:
self.sql=MySQLdb.Connect(host=Mysql_host,password=Mysql_password,user=Mysql_user,charset='utf8',database='wx')
self.cursor=self.sql.cursor()
except MySQLdb.MySQLError as e:
print(e)
def insert(self,table,data):
keys = ', '.join(data.keys())#取data的字段名
values = ', '.join(['%s'] * len(data.keys()))#取data对应的values个数,用占位符表示
sql_query= 'insert into %s (%s) values (%s)' % (table, keys, values)#values嵌套了个占位符
try:
self.cursor.execute(sql_query, tuple(data.values())) #因为sql_query中的values嵌套占位符,这样后的tuple元组形式填充
self.sql.commit() #每个操作要commit下才执行
except MySQLdb.MySQLError as e:
print(e)
self.sql.rollback()#如果有错误则回滚第三:网页解析

定义一个spider()类,来实现网页解析
1、传入相关全局变量,完整的headers和url等
2、类方法:start()第一个请求加入对应
3、类方法:getrequest():返回网页response。用到cookie,自然就需要requests库中的session()功能,在session.send(),需要对请求实例weixinrequest进行prepare()预处理。
4、类方法:parse_index()解析getrequest方法返回的response【网页搜索结果】,yield文章链接请求【设置回调方法parse_detail】;yield下一页请求,并放入队列
5、类方法:parse_detail()解析文章,以字典形式提取,并yield
6、类方法:error(),如果请求失败,利用weixinrequest的fialtime属性计数;最大允许范围里,重新加入请求队列,超过则不放回
class spider(object):
base_url='http://weixin.sogou.com/weixin'
headers={
'Accept': 'image / webp, image / apng, image / *, * / *;q = 0.8',
'Accept - Encoding': 'gzip, deflate,UTF-8',
'Accept - Language': 'zh-CN,zh;q=0.8,en;q=0.6,ja;q=0.4,zh-TW;q=0.2,mt;q=0.2',
'Connection': 'keep - alive',
'Host': 'pb.sogou.com',
'Referer': 'http: // wx.sogou.com /',
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 YaBrowser/18.6.1.770 Yowser/2.5 Safari/537.36'
}
ruler=re.compile(r'var publish_time = "(\d+.\d+.\d+)')
keywords='保加利亚妖王'
session=requests.Session()
queue=RedisQueue()
mysql1=mysql()
def get_proxy(self):
"""
代理池的web接口获取代理
:return:
"""
try:
response = requests.get(proxy_pool_web)
if response.status_code == 200:
print(response.text)
return response.text
return None
except requests.ConnectionError:
return None
def start(self):
"""
初始化
:return:
"""
self.session.headers.update(self.headers)
start_url = self.base_url +'?'+ urlencode({'query':self.keywords,'type':2})# 不如直接formate
weixin_request= weixinrequest(callback=self.parse_index,url=start_url,need_proxy=False)#构造第一个请求,以我们定义的类呈现
self.queue.add(weixin_request)#加入队列
def parse_index(self,response):
response.encoding='utf-8'
doc=etree.HTML(response.text)
url_details=doc.xpath('//div[@class="txt-box"]/h3/a/@href')
print('开始解析')
print(url_details)
#print(response.text)
for i in url_details:
#time.sleep(1)
wei=weixinrequest(url=i,callback=self.parse_detail,need_proxy=True)
print(wei.url)
yield wei
next_page=doc.xpath('//a[@id="sogou_next"]/@href')
if next_page:
time.sleep(2)
url_nex=self.base_url + str(next_page[0])
wei_nex=weixinrequest(url=url_nex,callback=self.parse_index,need_proxy=False)
yield wei_nex
def parse_detail(self,reponse):
time.sleep(1)
reponse.encoding='utf-8'
doc=pq(reponse.text)
print("细节解析")
data={
'titles': doc('#activity-name').text(),
'contens':doc('#js_content').text(),
'date': self.ruler.findall(reponse.text)[0],
'wechat': doc('#js_name').text()
}
print(data)
yield data
def requesttt(self,wx):
"""
:param wx: prepare()方法,转化为prepared request请求
:return: 响应值,和request.get()得到的reponse差不多
"""
try:
if wx.need_proxy:
proxy=self.get_proxy()
proxies={
'http': 'http://' + proxy,
'https': 'https://' + proxy#你需要对 body 或者 header (或者别的什么东西)做一些额外处理,,,,prepare()
}
return self.session.send(wx.prepare(),timeout=wx.timeout,allow_redirects=True,proxies=proxies) #.prepare()方法,把weixinrequest中封装的参数,进行预处理,结束后,send()出去,得到reaponse
return self.session.send(wx.prepare(),timeout=wx.timeout,allow_redirects=True)
except (requests.ConnectionError,requests.ConnectTimeout) as e:
print(e.args)
def error(self,wx):
wx.fail_time=wx.fail_time +1
print('request failed %s times %s '%(wx.fail_time,wx.url))
if wx.fail_time <= Max_failed_time:
self.queue.add(wx)第四:调度
调本也封装在了spider()类中,主要顺序

def scheduler(self):
while not self.queue.empty():
wx=self.queue.pop()
callback=wx.callback
print('schedule %s'% wx.url)
rseponse=self.requesttt(wx)
if rseponse and rseponse.status_code in Valid_statues:
print('zhix')
results = list(callback(rseponse))
if results:
for result in results:
if isinstance(result,weixinrequest):
self.queue.add(result)
if isinstance(result,dict):
self.mysql1.insert('articles',result)
else:
self.error(wx)
else:
self.error(wx)
def run(self):
self.start()
self.scheduler()第五:配置文档
数据库链接的相关信息等
第六:日志模块
这个demo暂时没有加上日志,,,,以后不是