【数据可视化】matplotlib、seaborn、pycharts
数据分析第一件事就是数据审查。
内容包括,特征变量的含义、类型、分布、缺失值、异常值等,方便下一步的数据预处理和特征的构造。
数据可视化在这个阶段,很方便展示。
第一:数据的特征
选取的数据是,电商相关数据。

第二:查看类型、统计变量
raw_data.describe()
raw_data.dtypes
raw_data.columns
raw_data.sample(10)
raw_data.isnull().any()
raw_data.isnull().any().sum()第三:groupby查看
1、应用于整个数据集
raw_data.groupby(by=['pay_type','cat']).sum()print的结果,是分类汇总结果:一级分类 pay type,二级分类cat,sum()方法对类型是数值型的所有特征执行。
同样可以应用count()方法,该方法对所有特征执行
raw_data.groupby(by=['pay_type','cat']).count()2、 以上的count和sum方法,最终打印的结果,太长不方便查阅,我们可以应用size()方法
raw_data.groupby(by=['pay_type','cat']).size()size方法,查阅效果好,相当于筛选单独的一个特征,应用count。
3、应用于特定的特征变量
raw_data['total_money'].groupby(raw_data['cat']).sum()第四:groupby拓展新特征
1、count方法,不要求transfrom前的特征类型为数值型
trans_cat=raw_data.groupby(by=['pay_type','order_source'])['order_source'].transform('count').astype(np.int16)print的结果是,行数和数据集相同,每一行的值,表示的意思在'pay_type' &'order_source'分组条件下,针对['order_source'].transform('count'),计数。
2、sum方法,要求transfrom前的特征类型为数值型
raw_data.groupby(by=['use_id'])['total_money'].transform('sum').astype(np.float)打印的结果:行数和数据集相同,每一行的值,表示该行的use id所有的total money求和。【所以会有很多重复值】
第四:日期处理
原始数据,日期和时间分开,其各自格式为文本格式,所以我们新建一列合并数据集,并拓展出其他时间粒度的特征;
同时我们把原数据集的order date 格式,改成Date格式。
#合并日期和时间,且新建列中
raw_data['new_date']=raw_data['order_date'].str.cat(raw_data['order_time'],sep=' ')
print('{:*^80}'.format('head'))
#pd.to_datetime 需要加上fromat
raw_data['new_date']=pd.to_datetime(raw_data['new_date'],format='%Y-%m-%d %H:%M:%S')
print(raw_data.head(10))
raw_data['order_date']=pd.to_datetime(raw_data['order_date'])
print(raw_data.isnull().any())
#时间粒度调整
raw_data['new_date1']=raw_data['new_date'].apply(lambda k:k.month)
raw_data['new_date2']=raw_data['new_date'].apply(lambda k:k.day)
raw_data['new_date3']=raw_data['new_date'].apply(lambda k:k.dayofyear)第五:利用matplotlib画图
1、x轴日期,y轴为total money的line图
a、应用groupby分组求和
kkk=raw_data['total_money'].groupby(raw_data['order_date']).sum()
plt.figure()
plt.plot(kkk)
plt.show()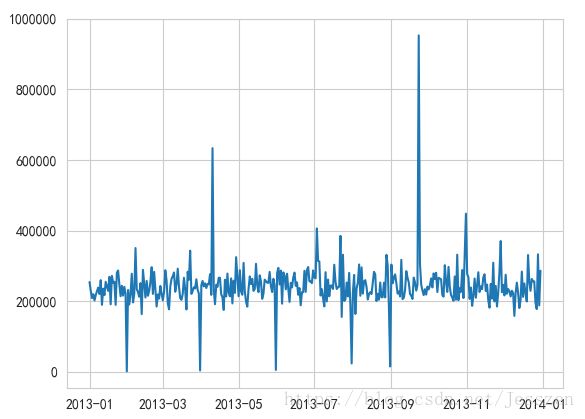
b、取单独total money列,重新设置索引,再次分组求和【重新设置索引的两种方法】
ts=pd.DataFrame(raw_data['total_money'])
ts.index=raw_data['order_date']
#等价的
#ts=ts.set_index(raw_data['new_date'])
ttt=ts.groupby(ts.index).sum()
plt.figure()
plt.plot(ttt)
plt.show()2、画直方图和折线图
kk=raw_data['total_money'].groupby(raw_data['new_date1']).sum()
plt.figure()
plt.ylim(6000000,8500000)
plt.plot(kk,color='red')
plt.bar(x=list(kk.index),height=kk)
plt.show()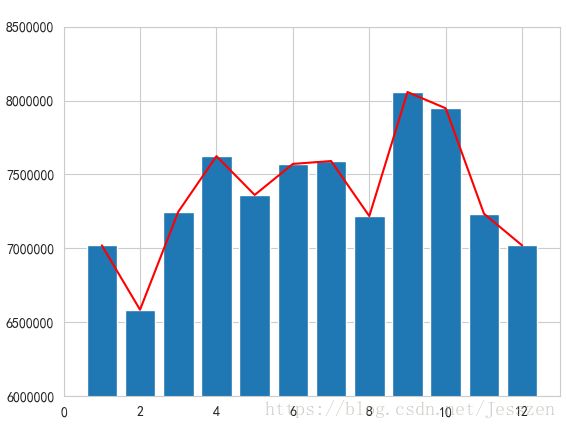
第六:应用seaborn画图
matplotlib画图,我们都要先groupby分组求和,而应用了seaborn就不需要了
【sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']})】防止中文乱码
1、画时序图 seaborn.lineplot()
plt.figure()
sns.lineplot(x='order_date',y='total_money',data=raw_data,estimator='sum')
plt.show()x y轴都是引用的列名,并且estmator参数传入的可以是sum,mean,max等等,逻辑运算封装在画图函数里,很简洁。
2、画条形图 seaborn.countplot()
#计数图
plt.figure()
#计数
#设置坐标轴文字方向
plt.xticks(rotation=-90)
sns.countplot(x="cat",data=raw_data)
plt.show()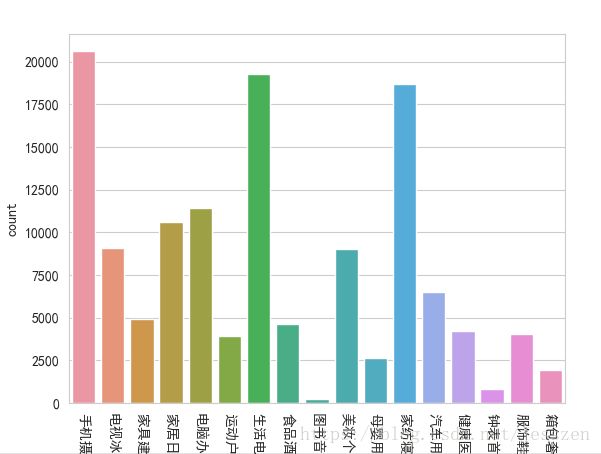
3、画折线图+直方图 sns.pointplot + sns.barplot
- lineplot不行,因为x轴会偏移一个单位,所以pointplot
- 同时,保存了图片
- 黑色的竖线:ci=95,显示置信区间;ci="sd",也可以设置为标准差
hue是指列名,可以指定分组
f=plt.figure()
#默认是均值,设置estimator
#plt.xticks(rotation=-90)
plt.ylim(6000000,8500000)
#黑色的竖线:ci=95,显示置信区间;ci="sd",也可以设置为标准差
#hue是指列名,可以指定分组
#sns.barplot(x='pay_type',y='total_quantity',hue='order_source',data=raw_data[raw_data['order_source']!='主站'],estimator=np.sum)
sns.pointplot(x='new_date1',y='total_money',data=raw_data,estimator=np.sum)
#lineplot坐标偏移,改成pointplot就好
#sns.lineplot(x='new_date1',y='total_money',data=raw_data,estimator='sum')
sns.barplot(x='new_date1',y='total_money',data=raw_data,estimator=np.sum)
plt.show()
f.savefig('直方图_折线图.jpg')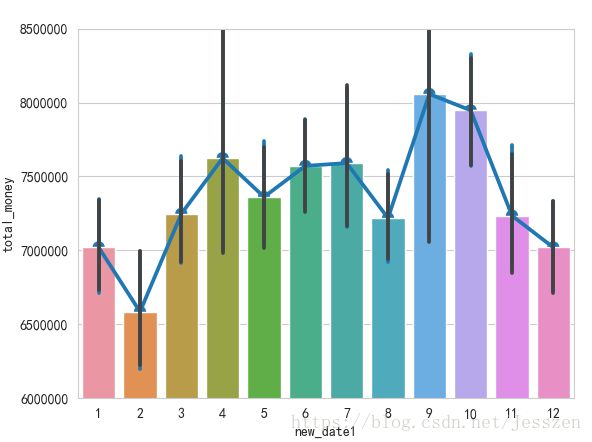
4、画散点图sns.scatterplot
散点图,可以方便看出是否存在异常值
#画散点图
plt.figure()
sns.scatterplot(x='new_date2',y='total_quantity',data=raw_data)
plt.show()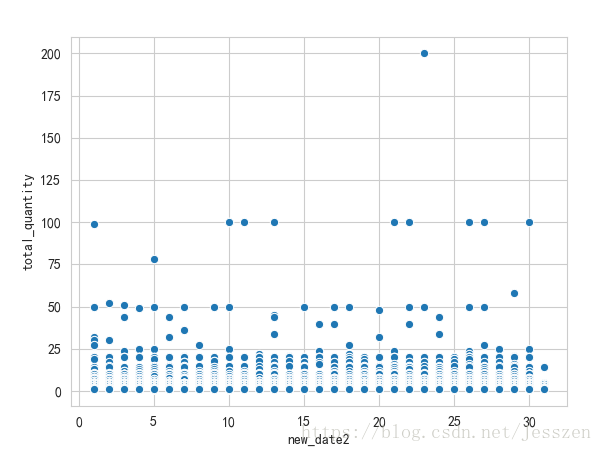
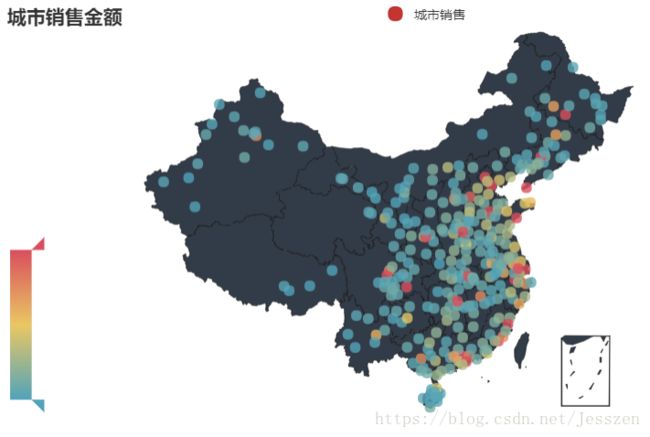
第七:应用pycharts画地图
1、画出每个城市对应的total money
2、出现的问题
a、数据集city部分值,不是城市名,需要删掉
b、city中部分城市,pycharts没有收录其经纬度,也需要删掉【问题是怎么判断】
#打印城市名称大于5个字符
print(raw_data['city'][list(map(lambda k:len(k)>5,raw_data['city']))].unique())
#等价于以上语句
print(raw_data['city'][raw_data['city'].str.len() >5].unique())
#~相当于否定语句,此相当于删除city字段包含其他城市的行
raw_data=raw_data[~raw_data['city'].str.contains('其他城市')]
print(raw_data.shape)
#利用pandas 数据框的apply的方法,替代map函数,并赋值给源数据框新的一列
raw_data['zuobiao']=raw_data['city'].apply(lambda k: get_coordinate(k))
print(raw_data.dtypes)
#因为pyecharts 经纬度数据补全,部分城市没有维度信息,这部分数据需要删除
raw_data=raw_data.dropna()3、画图
city_group=raw_data['total_quantity'].groupby(raw_data['city']).sum()
geo=Geo(title='城市销售金额')
geo.add('城市销售 ',city_group.index,city_group, visual_range=[0, 1500],maptype='china',visual_text_color="#fff",
symbol_size=10, is_visualmap=True)
geo.render('城市销售金额.html')