Hadoop2.0高可用集群搭建
0、集群节点分配
Hadoop01:
Zookeeper
NameNode(active)
DataNode
NodeManager
JournalNode
ResourceManager(active)
Hadoop02:
Zookeeper
DataNode
NodeManager
JournalNode
NameNode(standby)
Hadoop03:
Zookeeper
DataNode
NodeManager
JournalNode
ResourceManager(standby)
1、安装和配置01节点的Hadoop
- 将压缩包上传到/home/software目录下,进行解压
| [root@hadoop01 software]# pwd /home/software [root@hadoop01 software]# ll 总用量 205680 -rw-r--r-- 1 root root 210606807 12月 3 14:47 hadoop-2.7.1_64bit.tar.gz drwxr-xr-x 8 uucp 143 4096 3月 15 2017 jdk1.8 drwxr-xr-x 12 1000 1000 4096 12月 3 14:16 zookeeper [root@hadoop01 software]# tar -xf hadoop-2.7.1_64bit.tar.gz [root@hadoop01 software]# ll 总用量 205684 drwxr-xr-x 9 10021 10021 4096 6月 29 2015 hadoop-2.7.1 -rw-r--r-- 1 root root 210606807 12月 3 14:47 hadoop-2.7.1_64bit.tar.gz drwxr-xr-x 8 uucp 143 4096 3月 15 2017 jdk1.8 drwxr-xr-x 12 1000 1000 4096 12月 3 14:16 zookeeper [root@hadoop01 software]# rm hadoop-2.7.1_64bit.tar.gz rm:是否删除普通文件 "hadoop-2.7.1_64bit.tar.gz"?yes [root@hadoop01 software]# ll 总用量 12 drwxr-xr-x 9 10021 10021 4096 6月 29 2015 hadoop-2.7.1 drwxr-xr-x 8 uucp 143 4096 3月 15 2017 jdk1.8 drwxr-xr-x 12 1000 1000 4096 12月 3 14:16 zookeeper [root@hadoop01 software]# |
- 进入安装目录的/etc/hadoop目录下,修改hadoop-env.sh文件
| [root@hadoop01 hadoop]# pwd /home/software/hadoop-2.7.1/etc/hadoop [root@hadoop01 hadoop]# ll 总用量 152 -rw-r--r-- 1 10021 10021 4436 6月 29 2015 capacity-scheduler.xml -rw-r--r-- 1 10021 10021 1335 6月 29 2015 configuration.xsl -rw-r--r-- 1 10021 10021 318 6月 29 2015 container-executor.cfg -rw-r--r-- 1 10021 10021 774 6月 29 2015 core-site.xml -rw-r--r-- 1 10021 10021 3670 6月 29 2015 hadoop-env.cmd -rw-r--r-- 1 10021 10021 4224 6月 29 2015 hadoop-env.sh -rw-r--r-- 1 10021 10021 2598 6月 29 2015 hadoop-metrics2.properties -rw-r--r-- 1 10021 10021 2490 6月 29 2015 hadoop-metrics.properties -rw-r--r-- 1 10021 10021 9683 6月 29 2015 hadoop-policy.xml -rw-r--r-- 1 10021 10021 775 6月 29 2015 hdfs-site.xml -rw-r--r-- 1 10021 10021 1449 6月 29 2015 httpfs-env.sh -rw-r--r-- 1 10021 10021 1657 6月 29 2015 httpfs-log4j.properties -rw-r--r-- 1 10021 10021 21 6月 29 2015 httpfs-signature.secret -rw-r--r-- 1 10021 10021 620 6月 29 2015 httpfs-site.xml -rw-r--r-- 1 10021 10021 3518 6月 29 2015 kms-acls.xml -rw-r--r-- 1 10021 10021 1527 6月 29 2015 kms-env.sh -rw-r--r-- 1 10021 10021 1631 6月 29 2015 kms-log4j.properties -rw-r--r-- 1 10021 10021 5511 6月 29 2015 kms-site.xml -rw-r--r-- 1 10021 10021 11237 6月 29 2015 log4j.properties -rw-r--r-- 1 10021 10021 951 6月 29 2015 mapred-env.cmd -rw-r--r-- 1 10021 10021 1383 6月 29 2015 mapred-env.sh -rw-r--r-- 1 10021 10021 4113 6月 29 2015 mapred-queues.xml.template -rw-r--r-- 1 10021 10021 758 6月 29 2015 mapred-site.xml.template -rw-r--r-- 1 10021 10021 10 6月 29 2015 slaves -rw-r--r-- 1 10021 10021 2316 6月 29 2015 ssl-client.xml.example -rw-r--r-- 1 10021 10021 2268 6月 29 2015 ssl-server.xml.example -rw-r--r-- 1 10021 10021 2250 6月 29 2015 yarn-env.cmd -rw-r--r-- 1 10021 10021 4567 6月 29 2015 yarn-env.sh -rw-r--r-- 1 10021 10021 690 6月 29 2015 yarn-site.xml [root@hadoop01 hadoop]# vim hadoop-env.sh |
配置jdk安装所在目录
配置hadoop配置文件所在目录
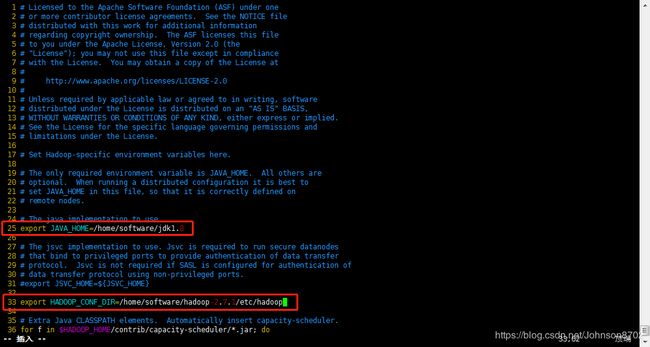
配置完成,执行source hadoop-env.sh,使配置立即生效
| [root@hadoop01 hadoop]# source hadoop-env.sh [root@hadoop01 hadoop]# |
- 配置core-site.xml文件
| [root@hadoop01 hadoop]# vim core-site.xml |
在文件的末尾,配置如下:
| |
- 配置hdfs-site.xml文件
| [root@hadoop01 hadoop]# vim hdfs-site.xml |
在文件的末尾,配置如下:
|
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider |
- 配置mapred-site.xml文件
这个文件初始是没有的,有的是模板文件,需要拷贝一份,然后进行配置
| [root@hadoop01 hadoop]# pwd [root@hadoop01 hadoop]# ll |
在文件的末尾,配置如下:
| |
- 配置yarn-site.xml
| [root@hadoop01 hadoop]# pwd /home/software/hadoop-2.7.1/etc/hadoop [root@hadoop01 hadoop]# vim yarn-site.xml |
在文件的末尾,配置如下:
| org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore |
- 配置slaves文件
| [root@hadoop01 hadoop]# pwd /home/software/hadoop-2.7.1/etc/hadoop [root@hadoop01 hadoop]# vim slaves |
修改文件,配置如下:
| hadoop01 hadoop02 hadoop03 |
- 配置Hadoop的环境变量(可不配)
修改/etc/profile文件
| [root@hadoop01 hadoop]# vim /etc/profile |
配置如下:

- 根据配置文件,创建相关的文件夹,用来存放对应数据
在hadoop-2.7.1目录下创建
①journal目录
②tmp目录
③在tmp目录下,分别创建namenode目录和datanode目录
| [root@hadoop01 hadoop-2.7.1]# pwd /home/software/hadoop-2.7.1 [root@hadoop01 hadoop-2.7.1]# mkdir journal [root@hadoop01 hadoop-2.7.1]# mkdir tmp [root@hadoop01 hadoop-2.7.1]# cd tmp [root@hadoop01 tmp]# pwd /home/software/hadoop-2.7.1/tmp [root@hadoop01 tmp]# mkdir namenode [root@hadoop01 tmp]# mkdir datanode [root@hadoop01 tmp]# |
2、通过scp命令,将hadoop安装目录远程copy到其他几台机器上
向hadoop02机器传输:
| [root@hadoop01 software]# pwd /home/software [root@hadoop01 software]# scp -r hadoop-2.7.1/ root@hadoop02:/home/software/ |
向hadoop03机器传输:
| [root@hadoop01 software]# pwd /home/software [root@hadoop01 software]# scp -r hadoop-2.7.1/ root@hadoop03:/home/software/ |
3、启动Hadoop集群
①启动zookeeper集群
在zookeeper安装目录的bin目录下执行:./zkServer.sh star
| [root@hadoop01 bin]# pwd /home/software/zookeeper/bin [root@hadoop01 bin]# ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /home/software/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@hadoop01 bin]# ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/software/zookeeper/bin/../conf/zoo.cfg Mode: follower [root@hadoop01 bin]# |
②格式化zookeeper(仅在第一次配置Hadoop时执行)
在zk的leader节点执行:hdfs zkfc-formatZK
| [root@hadoop02 bin]# pwd /home/software/zookeeper/bin [root@hadoop02 bin]# ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/software/zookeeper/bin/../conf/zoo.cfg Mode: leader [root@hadoop02 bin]# hdfs zkfc -formatZK |
出现下图所示提示,说明格式化成功:

③启动journalnode集群
在三个节点上执行以下操作
切换到hadoop的安装目录的sbin目录下,执行:./hadoop-deamons.sh start journalnode
| [root@hadoop01 sbin]# pwd hadoop02: starting journalnode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-journalnode-hadoop02.out |
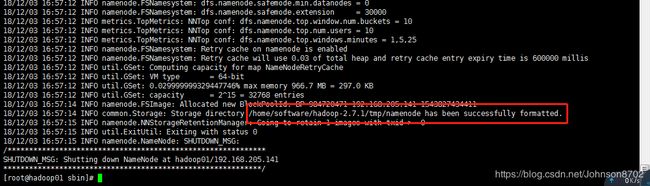
④格式化01节点的namenode
在01节点上执行:hadoop namenode -format
| [root@hadoop01 sbin]# hadoop namenode -format |
出现如下提示,说明格式化成功:
⑤启动01节点的namenode
在01节点上执行:hadoop-deamon.sh start namenode
| [root@hadoop01 sbin]# hadoop-daemon.sh start namenode starting namenode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-namenode-hadoop01.out [root@hadoop01 sbin]# jps 21760 JournalNode 21586 QuorumPeerMain 22002 Jps 21930 NameNode [root@hadoop01 sbin]# |
jps查看进程,会多出一个NameNode进程
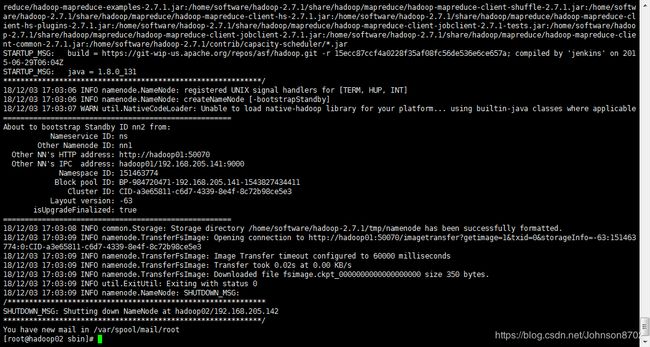
⑥把02节点的那么node节点变成standby namenode节点
在02节点上执行:hdfs namenode -bootstrapStandby
| [root@hadoop02 sbin]# hdfs namenode -bootstrapStandby |
出现如下提示,说明设置成功:
⑦启动02节点的namenode
在02节点上执行:hadoop-deamon.sh start namenode
| [root@hadoop02 sbin]# hadoop-daemon.sh start namenode starting namenode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-namenode-hadoop02.out [root@hadoop02 sbin]# jps 21537 QuorumPeerMain 22039 NameNode 22111 Jps 21887 JournalNode [root@hadoop02 sbin]# |
jps查看进程,会多出NameNode进程
⑧在三个节点上启动datanode
在三个节点上执行:hadoop-deamon.sh star datanode
| [root@hadoop01 sbin]# hadoop-daemon.sh start datanode starting datanode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-datanode-hadoop01.out [root@hadoop01 sbin]# jps 21760 JournalNode 21586 QuorumPeerMain 21930 NameNode 22186 Jps 22107 DataNode [root@hadoop01 sbin]# |
jps查看进程,会多出DataNode进程(此处以01节点为例进行展示,其他两个节点自行jps查看)
⑨启动zkfc(FailoverControllerActive)
在01节点执行:hadoop-deamon.sh start zkfc
| [root@hadoop01 sbin]# hadoop-daemon.sh start zkfc starting zkfc, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-zkfc-hadoop01.out [root@hadoop01 sbin]# jps 22256 DFSZKFailoverController 21760 JournalNode 22320 Jps 21586 QuorumPeerMain 21930 NameNode 22107 DataNode [root@hadoop01 sbin]# |
jps查看进程,会多出DFSZKFailoverController进程(此处以01节点为例进行展示,02节点自行jps查看)
⑩在01节点上启动主ResourceManager
在01节点上执行:start-yarn.sh
| [root@hadoop01 sbin]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-resourcemanager-hadoop01.out hadoop03: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop03.out hadoop02: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop02.out hadoop01: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop01.out [root@hadoop01 sbin]# jps 22256 DFSZKFailoverController 21760 JournalNode 21586 QuorumPeerMain 22499 Jps 22468 NodeManager 22374 ResourceManager 21930 NameNode 22107 DataNode [root@hadoop01 sbin]# |
jps查看进程,会多出ResourceManager进程(此处以01节点为例进行展示,其他两个节点自行jps查看)
⑪在03节点上启动副ResourceManager
在03节点上执行:yarn-deamon.sh start resourcemanager
| [root@hadoop03 sbin]# yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-resourcemanager-hadoop03.out |
jps查看进程,会多出ResourceManager进程
备注:步骤③到⑪在第一次启动Hadoop时使用,以后直接在01节点执行:start-all.sh,一步启动Hadoop所有进程
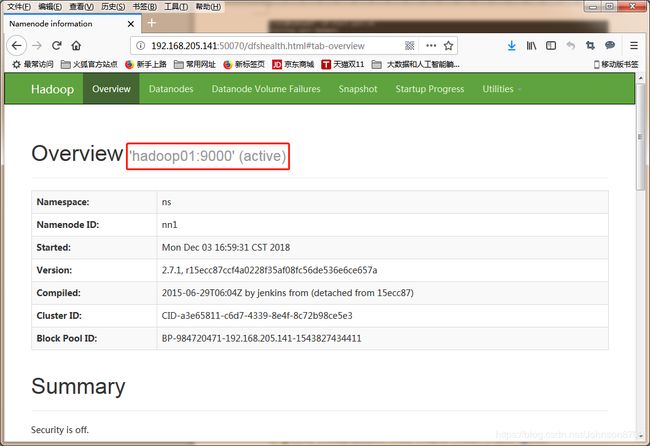
4、测试
在浏览器中输入http://192.168.205.141:50070,查看01节点的namenode状态为active
在浏览器中输入http://192.168.205.142:50070,查看02节点的namenode状态为standby
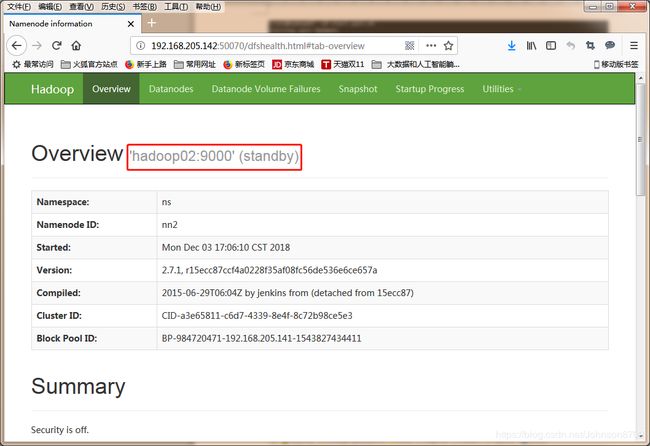
然后停掉01节点的namenode,此时发现02节点standby的namenode变成active
| [root@hadoop01 sbin]# kill -9 21930 |
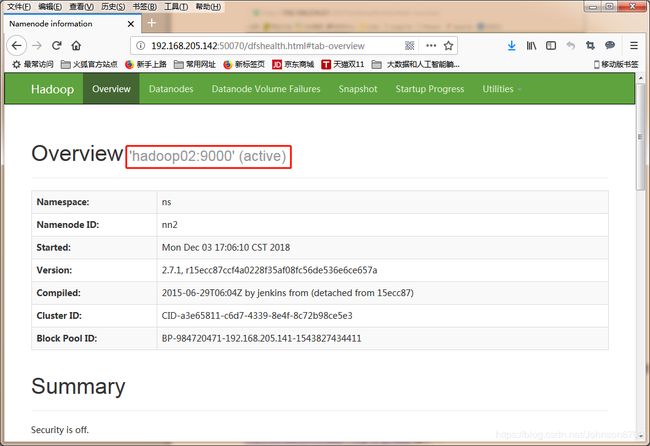
在01节点上,重新把namenode进程启动起来
| [root@hadoop01 sbin]# hadoop-daemon.sh start namenode |
5、查看yarn管理器
浏览器输入http://192.168.205.141:8088,查看yarn
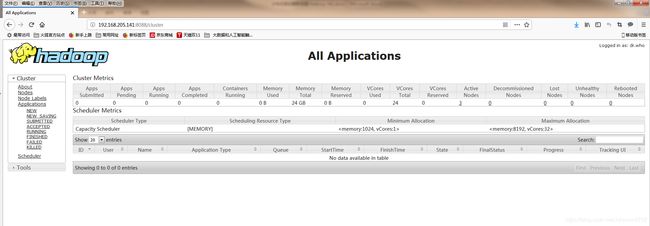
6、关闭过程
①在03节点上关闭副ResourceManager
在03节点上执行:yarn-daemon.sh stop resourcemanager
| [root@hadoop03 sbin]# yarn-daemon.sh stop resourcemanager stopping resourcemanager [root@hadoop03 sbin]# jps 21730 JournalNode 21827 DataNode 22231 Jps 21515 QuorumPeerMain 21948 NodeManager [root@hadoop03 sbin]# |
jps查看进程,减少一个ResourceManager进程
②在01节点上关闭主ResourceManager
在01节点上执行:stop-yarn.sh
| [root@hadoop01 sbin]# stop-yarn.sh 21930 NameNode |
jps查看进程,01节点会减少NodeManager,ResourceManager进程,02和03节点会减少NodeManager进程
③关闭zkfc(FailoverControllerActive)
在01,02节点执行:hadoop-daemon.sh stop zkfc
| [root@hadoop01 sbin]# hadoop-daemon.sh stop zkfc [root@hadoop01 sbin]# jps 21930 NameNode |
| [root@hadoop02 sbin]# hadoop-daemon.sh stop zkfc stopping zkfc [root@hadoop02 sbin]# jps 21537 QuorumPeerMain 23077 Jps 22151 DataNode 22039 NameNode 21887 JournalNode [root@hadoop02 sbin]# |
jps查看,01,02节点都减少了DFSZKFailoverController进程
④在三个节点上关闭datanode节点
在三个节点上执行:hadoop-daemon.sh stop datanode
| [root@hadoop01 sbin]# hadoop-daemon.sh stop datanode 21930 NameNode |
| [root@hadoop02 sbin]# hadoop-daemon.sh stop datanode stopping datanode [root@hadoop02 sbin]# jps 21537 QuorumPeerMain 22039 NameNode 23115 Jps 21887 JournalNode [root@hadoop02 sbin]# |
| [root@hadoop03 sbin]# hadoop-daemon.sh stop datanode stopping datanode [root@hadoop03 sbin]# jps 21730 JournalNode 22314 Jps 21515 QuorumPeerMain [root@hadoop03 sbin]# |
jps查看,01,02,03节点都减少了DataNode进程
⑤关闭02节点的namenode进程
在02节点上执行:hadoop-daemon.sh stop namenode
| [root@hadoop02 sbin]# hadoop-daemon.sh stop namenode stopping namenode [root@hadoop02 sbin]# jps 21537 QuorumPeerMain 23144 Jps 21887 JournalNode [root@hadoop02 sbin]# |
jps查看,02节点减少NameNode进程
⑥关闭01节点的namenode
在01节点上执行:
| [root@hadoop01 sbin]# hadoop-daemon.sh stop namenode stopping namenode [root@hadoop01 sbin]# jps 21760 JournalNode 23185 Jps 21586 QuorumPeerMain [root@hadoop01 sbin]# |
jps查看,01节点减少NameNode进程
⑦关闭journalnode集群
在01,02,03节点上执行:hadoop-daemon.sh stop journalnode
| [root@hadoop01 sbin]# hadoop-daemon.sh stop journalnode stopping journalnode [root@hadoop01 sbin]# jps 21586 QuorumPeerMain 23214 Jps [root@hadoop01 sbin]# |
| [root@hadoop02 sbin]# hadoop-daemon.sh stop journalnode stopping journalnode [root@hadoop02 sbin]# jps 21537 QuorumPeerMain 23192 Jps [root@hadoop02 sbin]# |
| [root@hadoop03 sbin]# hadoop-daemon.sh stop journalnode stopping journalnode [root@hadoop03 sbin]# jps 22352 Jps 21515 QuorumPeerMain [root@hadoop03 sbin]# |
jps查看,01,02,03节点都减少JournalNode进程
⑧关闭zookeeper集群
在01,02,03节点zookeeper安装目录的bin目录下执行:
| [root@hadoop01 bin]# pwd ZooKeeper JMX enabled by default |
| [root@hadoop02 bin]# pwd /home/software/zookeeper/bin [root@hadoop02 bin]# ./zkServer.sh stop ZooKeeper JMX enabled by default Using config: /home/software/zookeeper/bin/../conf/zoo.cfg Stopping zookeeper ... STOPPED [root@hadoop02 bin]# jps 23213 Jps [root@hadoop02 bin]# |
| [root@hadoop03 bin]# pwd /home/software/zookeeper/bin [root@hadoop03 bin]# ./zkServer.sh stop ZooKeeper JMX enabled by default Using config: /home/software/zookeeper/bin/../conf/zoo.cfg Stopping zookeeper ... STOPPED [root@hadoop03 bin]# jps 22373 Jps [root@hadoop03 bin]# |
jps查看,01,02,03节点都减少QuorumPeerMain进程
备注:步骤①到⑦在第一次关闭Hadoop时使用,以后直接在01节点执行:stop-all.sh,一步关闭Hadoop所有进程
至此,Hadoop高可用(HA)配置完成!