GoogLeNet资源【1】
【转】学习笔记:GoogLeNet
原作者:lynnandwei 原文地址:http://blog.csdn.net/lynnandwei/article/details/44458033
GoogLeNet,2014年ILSVRC挑战赛冠军,将Top5的错误率降低到6.67%。一个22层的深度网络,论文在http://arxiv.org/pdf/1409.4842v1.pdf,题目为:with convolutions。(每次看这么简洁优雅的题目,就想吐槽国内写纸的八股文题目).GoogLeNet这个名字也是挺有意思的,为了像开山鼻祖的LeNet网络致敬,他们选择了这样的名字。
BVLC在caffe中给出了网络的实现:https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet
模型下载地址:http : //dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel
从论文里整理了一张这个22个层次的模型的图出来(如果考虑pooling layer是27层),先将模型跑了一遍结果,还是那只猫:
直观输出是如下,
[287 281 285 282 283]
['n02127052 lynx,catamount''n02123045 tabby,tabby
cat''n02124075 Egyptian cat''n02123159 tiger cat''n02123394 Persian cat']
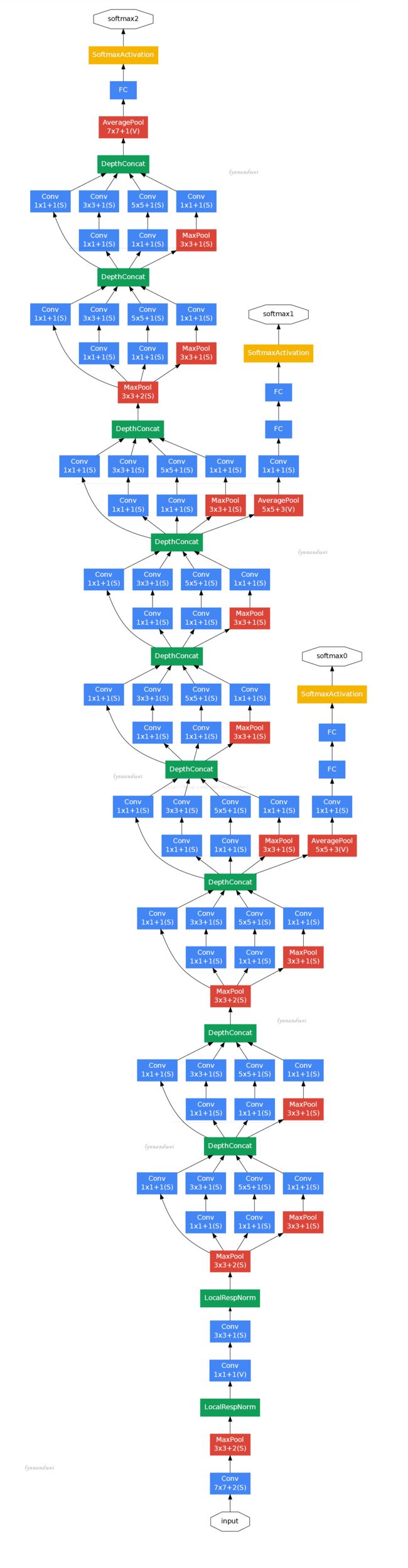
caffe的实现和原来论文的模型是有不同的:
不是用重新点亮数据增加训练;
不是用尺度或纵横比数据增加训练;
使用“xavier”初始化权重,而不是“gaussian”;
quick_solver.prototxt使用不同于原始solver.prototxt的学习速率衰减策略,允许更快的训练(60个纪元和250个纪元);
捆绑模型是使用quick_solver.prototxt的迭代2,400,000个快照(60个纪元)
但是准确度还是达到了顶1精度68.7%(31.3%误差)和前5精度88.9%(11.1%误差)
我们来分析一下这个模型的层次关系:
原始数据,输入为224 * 224 * 3
第一层卷积层conv1,pad是3,64个特征,7 * 7步长为2,输出特征为112 * 112 * 64,然后进行relu,经过pool1(红色的最大池)进行pooling 3 * 3的核,步长为2,[(112 - 3 + 1)/ 2] +1 = 56特征为56 * 56 * 64,然后进行norm
第二层卷积层conv2,pad是1,3 * 3,192个特征,输出为56 * 56 * 192,然后进行relu,进行norm,经过pool2进行pooling,3 * 3的核,步长为2输出为28 * 28 * 192然后进行split分成四个支线
- 设置pool2 / 3x3_s2
- I0319 23:50:37.405478 5765 net.cpp:103]顶部形状:10 192 28 28(1505280)
- I0319 23:50:37.405484 5765 net.cpp:113]数据需要内存:174612480
- I0319 23:50:37.405495 5765 net.cpp:67]创建图层pool2 / 3x3_s2_pool2 / 3x3_s2_0_split
- I0319 23:50:37.405503 5765 net.cpp:394] pool2 / 3x3_s2_pool2 / 3x3_s2_0_split < - pool2 / 3x3_s2
- I0319 23:50:37.405515 5765 net.cpp:356] pool2 / 3x3_s2_pool2 / 3x3_s2_0_split - > pool2 / 3x3_s2_pool2 / 3x3_s2_0_split_0
- I0319 23:50:37.405531 5765 net.cpp:356] pool2 / 3x3_s2_pool2 / 3x3_s2_0_split - > pool2 / 3x3_s2_pool2 / 3x3_s2_0_split_1
- I0319 23:50:37.405545 5765 net.cpp:356] pool2 / 3x3_s2_pool2 / 3x3_s2_0_split - > pool2 / 3x3_s2_pool2 / 3x3_s2_0_split_2
- 池03/23×20
- I0319 23:50:37.405567 5765 net.cpp:96]设置pool2 / 3x3_s2_pool2 / 3x3_s2_0_split
- I0319 23:50:37.405577 5765 net.cpp:103]顶部形状:10 192 28 28(1505280)
- I0319 23:50:37.405582 5765 net.cpp:103]顶部形状:10 192 28 28(1505280)
- I0319 23:50:37.405587 5765 net.cpp:103]顶部形状:10 192 28 28(1505280)
- I0319 23:50:37.405592 5765 net.cpp:103]顶部形状:10 192 28 28(1505280)
- I0319 23:50:37.405597 5765 net.cpp:113]数据所需的内存:198696960
- I0319 23:50:37.405611 5765 net.cpp:67]创建层初始_3a / 1x1 ^ M
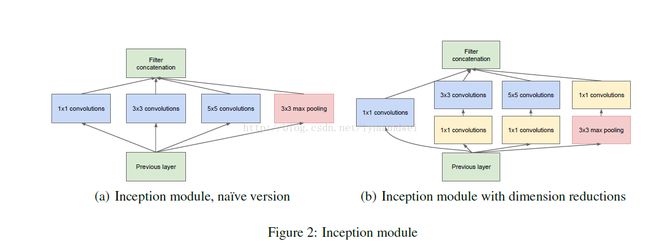
第三层开始时候模块,这个的思想受到使用不同尺度的Gabor过滤器来处理多尺度问题,inception module采用不同尺度的卷积核来处理问题.3a包含四个支线:
1:64个1 * 1的卷积核(之后进行RULE计算)变成28 * 28 * 64
2:96个1 * 1的卷积核作为3 * 3卷积核之前的减少,变成28 * 28 * 96,进行relu计算后,再进行128个3 * 3的卷积, 28 * 28 * 128
3:16个1 * 1的卷积核作为5 * 5卷积核之前的减少,变成28 * 28 * 16,进行relu计算后,再进行32个5 * 5的卷积,变成28 * 28 * 32
4:池层,3 * 3的核,垫为1,输出还是28 * 28 * 192,然后进行32个1 * 1的卷积,变成28 * 28 * 32。
将四个结果进行连接,输出为28 * 28 * 256
然后将3a的结果又分成四条支线,开始建立3b的开始模块
3b
1:128个1 * 1的卷积核(之后进行RULE计算)变成28 * 28 * 128
2:128个1 * 1的卷积核作为3 * 3卷积核之前的减少,变成28 * 28 * 128,再进行192个3 * 3的卷积,垫为1,28 * 28 * 192 ,进行relu计算
3:32个1 * 1的卷积核作为5 * 5卷积核之前的减少,变成28 * 28 * 32,进行relu计算后,再进行96个5 * 5的卷积,变成28 * 28 * 96
4:池层,3 * 3的核,垫为1,输出还是28 * 28 * 256,然后进行64个1 * 1的卷积,变成28 * 28 * 64。
将四个结果进行连接,输出为28 * 28 * 480
同理依次推算,数据变化如下表:
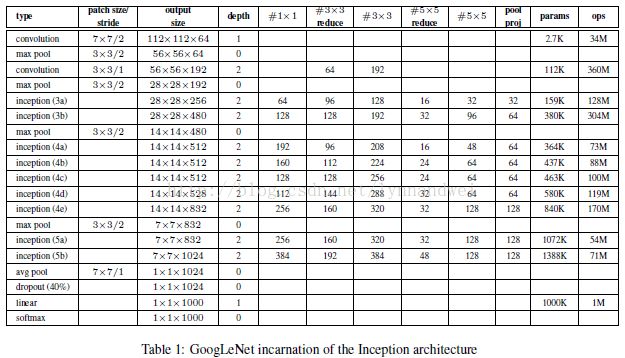
一部分输出结果如下:
I0319 22:27:51.257917 5080 net.cpp:208]这个网络产生输出故障
- I0319 22:27:51.258116 5080 net.cpp:467]收集学习率和体重衰减。
- I0319 22:27:51.258162 5080 net.cpp:219]网络初始化完成。
- I0319 22:27:51.258167 5080 net.cpp:220]数据所需的内存:545512320
- I0319 22:27:51.345417 5080 net.cpp:702]忽略源层数据
- I0319 22:27:51.345443 5080 net.cpp:702]忽略源层label_data_1_split
- I0319 22:27:51.345448 5080 net.cpp:705]复制源层conv1 / 7x7_s2
- I0319 22:27:51.345542 5080 net.cpp:705]复制源层conv1 / relu_7x7
- I0319 22:27:51.345548 5080 net.cpp:705]复制源层pool1 / 3x3_s2
- I0319 22:27:51.345553 5080 net.cpp:705]复制源层pool1 / norm1
- I0319 22:27:51.345558 5080 net.cpp:705]复制源层conv2 / 3x3_reduce
- I0319 22:27:51.345600 5080 net.cpp:705]复制源层conv2 / relu_3x3_reduce
- I0319 22:27:51.345607 5080 net.cpp:705]复制源层conv2 / 3x3
- I0319 22:27:51.346571 5080 net.cpp:705]复制源层conv2 / relu_3x3
- I0319 22:27:51.346580 5080 net.cpp:705]复制源层conv2 / norm2
- I0319 22:27:51.346585 5080 net.cpp:705]复制源层pool2 / 3x3_s2
- I0319 22:27:51.346590 5080 net.cpp:705]复制源层pool2 / 3x3_s2_pool2 / 3x3_s2_0_split
- I0319 22:27:51.346595 5080 net.cpp:705]复制源层inception_3a / 1x1
- I0319 22:27:51.346706 5080 net.cpp:705]复制源层inception_3a / relu_1x1
- I0319 22:27:51.346712 5080 net.cpp:705]复制源层inception_3a / 3x3_reduce
- I0319 22:27:51.346879 5080 net.cpp:705]复制源层inception_3a / relu_3x3_reduce
- I0319 22:27:51.346885 5080 net.cpp:705]复制源层inception_3a / 3x3
- I0319 22:27:51.347844 5080 net.cpp:705]复制源层inception_3a / relu_3x3
- I0319 22:27:51.347851 5080 net.cpp:705]复制源层inception_3a / 5x5_reduce
- I0319 22:27:51.347885 5080 net.cpp:705]复制源层inception_3a / relu_5x5_reduce
- I0319 22:27:51.347892 5080 net.cpp:705]复制源层inception_3a / 5x5
- I0319 22:27:51.348008 5080 net.cpp:705]复制源层inception_3a / relu_5x5
- I0319 22:27:51.348014 5080 net.cpp:705]复制源层inception_3a / pool
- I0319 22:27:51.348019 5080 net.cpp:705]复制源层inception_3a / pool_proj
- I0319 22:27:51.348080 5080 net.cpp:705]复制源层inception_3a / relu_pool_proj
- I0319 22:27:51.348085 5080 net.cpp:705]复制源层inception_3a / output
- I0319 22:27:51.348091 5080 net.cpp:705]复制源层inception_3a / output_inception_3a / output_0_split
- I0319 22:27:51.348096 5080 net.cpp:705]复制源层inception_3b / 1x1
- I0319 22:27:51.348398 5080 net.cpp:705]复制源层inception_3b / relu_1x1
- I0319 22:27:51.348405 5080 net.cpp:705]复制源层inception_3b / 3x3_reduce
- I0319 22:27:51.348700 5080 net.cpp:705]复制源层inception_3b / relu_3x3_reduce
- I0319 22:27:51.348707 5080 net.cpp:705]复制源层inception_3b / 3x3
- I0319 22:27:51.350611 5080 net.cpp:705]复制源层inception_3b / relu_3x3
- I0319 22:27:51.350620 5080 net.cpp:705]复制源层inception_3b / 5x5_reduce
- I0319 22:27:51.350699 5080 net.cpp:705]复制源层inception_3b / relu_5x5_reduce
- I0319 22:27:51.350705 5080 net.cpp:705]复制源层inception_3b / 5x5
- I0319 22:27:51.351372 5080 net.cpp:705]复制源层inception_3b / relu_5x5
- I0319 22:27:51.351378 5080 net.cpp:705]复制源层inception_3b / pool
- I0319 22:27:51.351384 5080 net.cpp:705]复制源层inception_3b / pool_proj
- I0319 22:27:51.351546 5080 net.cpp:705]复制源层inception_3b / relu_pool_proj
- I0319 22:27:51.351552 5080 net.cpp:705]复制源层inception_3b / output
- I0319 22:27:51.351558 5080 net.cpp:705]复制源层pool3 / 3x3_s2
- I0319 22:27:51.351563 5080 net.cpp:705]复制源层pool3 / 3x3_s2_pool3 / 3x3_s2_0_split
- I0319 22:27:51.351569 5080 net.cpp:705]复制源层inception_4a / 1x1
- I0319 22:27:51.352367 5080 net.cpp:705]复制源层inception_4a / relu_1x1
- I0319 22:27:51.352375 5080 net.cpp:705]复制源层inception_4a / 3x3_reduce
- I0319 22:27:51.352782 5080 net.cpp:705]复制源层inception_4a / relu_3x3_reduce
- I0319 22:27:51.352789 5080 net.cpp:705]复制源层inception_4a / 3x3
- I0319 22:27:51.354333 5080 net.cpp:705]复制源层inception_4a / relu_3x3
- I0319 22:27:51.354341 5080 net.cpp:705]复制源层inception_4a / 5x5_reduce
- I0319 22:27:51.354420 5080 net.cpp:705]复制源层inception_4a / relu_5x5_reduce
- I0319 22:27:51.354429 5080 net.cpp:705]复制源层inception_4a / 5x5
- I0319 22:27:51.354601 5080 net.cpp:705]复制源层inception_4a / relu_5x5
- I0319 22:27:51.354609 5080 net.cpp:705]复制源层inception_4a / pool
- I0319 22:27:51.354614 5080 net.cpp:705]复制源层inception_4a / pool_proj
- I0319 22:27:51.354887 5080 net.cpp:705]复制源图层inception_4a / relu_pool_proj
- I0319 22:27:51.354894 5080 net.cpp:705]复制源层inception_4a / output
- I0319 22:27:51.354900 5080 net.cpp:705]复制源层inception_4a / output_inception_4a / output_0_split
- I0319 22:27:51.354910 5080 net.cpp:702]忽略源层loss1 / ave_pool
- I0319 22:27:51.354918 5080 net.cpp:702]忽略源层丢失1 / conv
- I0319 22:27:51.354923 5080 net.cpp:702]忽略源层loss1 / relu_conv
- I0319 22:27:51.354930 5080 net.cpp:702]忽略源层loss1 / fc
- I0319 22:27:51.354936 5080 net.cpp:702]忽略源层loss1 / relu_fc
- I0319 22:27:51.354943 5080 net.cpp:702]忽略源层loss1 / drop_fc
- I0319 22:27:51.354950 5080 net.cpp:702]忽略源层损失1 /分类器
- I0319 22:27:51.354956 5080 net.cpp:702]忽略源层损失1 /损失
- I0319 22:27:51.354962 5080 net.cpp:705]复制源层inception_4b / 1x1
- I0319 22:27:51.355681 5080 net.cpp:705]复制源层inception_4b / relu_1x1
- I0319 22:27:51.355690 5080 net.cpp:705]复制源层inception_4b / 3x3_reduce
- I0319 22:27:51.356190 5080 net.cpp:705]复制源层inception_4b / relu_3x3_reduce
- I0319 22:27:51.356199 5080 net.cpp:705]复制源层inception_4b / 3x3
- I0319 22:27:51.358134 5080 net.cpp:705]复制源层inception_4b / relu_3x3
- I0319 22:27:51.358144 5080 net.cpp:705]复制源层inception_4b / 5x5_reduce
- I0319 22:27:51.358256 5080 net.cpp:705]复制源层inception_4b / relu_5x5_reduce
- I0319 22:27:51.358263 5080 net.cpp:705]复制源层inception_4b / 5x5
- I0319 22:27:51.358608 5080 net.cpp:705]复制源层inception_4b / relu_5x5
- I0319 22:27:51.358616 5080 net.cpp:705]复制源层inception_4b / pool
- I0319 22:27:51.358623 5080 net.cpp:705]复制源层inception_4b / pool_proj
- I0319 22:27:51.358917 5080 net.cpp:705]复制源层inception_4b / relu_pool_proj
- I0319 22:27:51.358925 5080 net.cpp:705]复制源层inception_4b / output
- I0319 22:27:51.358932 5080 net.cpp:705]复制源层inception_4b / output_inception_4b / output_0_split
- I0319 22:27:51.358937 5080 net.cpp:705]复制源层inception_4c / 1x1
- I0319 22:27:51.359519 5080 net.cpp:705]复制源层inception_4c / relu_1x1
- I0319 22:27:51.359526 5080 net.cpp:705]复制源层inception_4c / 3x3_reduce
- I0319 22:27:51.360097 5080 net.cpp:705]复制源层inception_4c / relu_3x3_reduce
- I0319 22:27:51.360105 5080 net.cpp:705]复制源层inception_4c / 3x3
- I0319 22:27:51.362634 5080 net.cpp:705]复制源层inception_4c / relu_3x3
- I0319 22:27:51.362643 5080 net.cpp:705]复制源层inception_4c / 5x5_reduce
- I0319 22:27:51.362757 5080 net.cpp:705]复制源层inception_4c / relu_5x5_reduce
- I0319 22:27:51.362764 5080 net.cpp:705]复制源层inception_4c / 5x5
- I0319 22:27:51.363106 5080 net.cpp:705]复制源层inception_4c / relu_5x5
- I0319 22:27:51.363114 5080 net.cpp:705]复制源层inception_4c / pool
- I0319 22:27:51.363121 5080 net.cpp:705]复制源层inception_4c / pool_proj
- I0319 22:27:51.363415 5080 net.cpp:705]复制源层inception_4c / relu_pool_proj
- I0319 22:27:51.363423 5080 net.cpp:705]复制源层inception_4c / output
- I0319 22:27:51.363430 5080 net.cpp:705]复制源层inception_4c / output_inception_4c / output_0_split
- I0319 22:27:51.363436 5080 net.cpp:705]复制源层inception_4d / 1x1
- I0319 22:27:51.363937 5080 net.cpp:705]复制源层inception_4d / relu_1x1
- I0319 22:27:51.363945 5080 net.cpp:705]复制源层inception_4d / 3x3_reduce
- I0319 22:27:51.364591 5080 net.cpp:705]复制源层inception_4d / relu_3x3_reduce
- I0319 22:27:51.364600 5080 net.cpp:705]复制源层inception_4d / 3x3
- I0319 22:27:51.367797 5080 net.cpp:705]复制源层inception_4d / relu_3x3
- I0319 22:27:51.367806 5080 net.cpp:705]复制源层inception_4d / 5x5_reduce
- I0319 22:27:51.367959 5080 net.cpp:705]复制源层inception_4d / relu_5x5_reduce
- I0319 22:27:51.367966 5080 net.cpp:705]复制源层inception_4d / 5x5
- I0319 22:27:51.368420 5080 net.cpp:705]复制源层inception_4d / relu_5x5
- I0319 22:27:51.368428 5080 net.cpp:705]复制源层inception_4d / pool
- I0319 22:27:51.368435 5080 net.cpp:705]复制源层inception_4d / pool_proj
- I0319 22:27:51.368726 5080 net.cpp:705]复制源层inception_4d / relu_pool_proj
- I0319 22:27:51.368733 5080 net.cpp:705]复制源层inception_4d / output
- I0319 22:27:51.368739 5080 net.cpp:705]复制源层inception_4d / output_inception_4d / output_0_split
- I0319 22:27:51.368748 5080 net.cpp:702]忽略源层loss2 / ave_pool
- I0319 22:27:51.368755 5080 net.cpp:702]忽略源层丢失2 / conv
- I0319 22:27:51.368762 5080 net.cpp:702]忽略源层loss2 / relu_conv
- I0319 22:27:51.368768 5080 net.cpp:702]忽略源层损耗2 / fc
- I0319 22:27:51.368774 5080 net.cpp:702]忽略源层loss2 / relu_fc
- I0319 22:27:51.368780 5080 net.cpp:702]忽略源层loss2 / drop_fc
- I0319 22:27:51.368788 5080 net.cpp:702]忽略源层丢失2 /分类器
- I0319 22:27:51.368794 5080 net.cpp:702]忽略源层损失2 /损失
- I0319 22:27:51.368800 5080 net.cpp:705]复制源层inception_4e / 1x1
- I0319 22:27:51.369971 5080 net.cpp:705]复制源层inception_4e / relu_1x1
- I0319 22:27:51.369981 5080 net.cpp:705]复制源层inception_4e / 3x3_reduce
- I0319 22:27:51.370717 5080 net.cpp:705]复制源层inception_4e / relu_3x3_reduce
- I0319 22:27:51.370725 5080 net.cpp:705]复制源层inception_4e / 3x3
- I0319 22:27:51.374668 5080 net.cpp:705]复制源层inception_4e / relu_3x3
- I0319 22:27:51.374678 5080 net.cpp:705]复制源层inception_4e / 5x5_reduce
- I0319 22:27:51.374831 5080 net.cpp:705]复制源层inception_4e / relu_5x5_reduce
- I0319 22:27:51.374840 5080 net.cpp:705]复制源层inception_4e / 5x5
- I0319 22:27:51.375728 5080 net.cpp:705]复制源层inception_4e / relu_5x5
- I0319 22:27:51.375737 5080 net.cpp:705]复制源层inception_4e / pool
- I0319 22:27:51.375744 5080 net.cpp:705]复制源层inception_4e / pool_proj
- I0319 22:27:51.376332 5080 net.cpp:705]复制源层inception_4e / relu_pool_proj
- I0319 22:27:51.376340 5080 net.cpp:705]复制源层inception_4e / output
- I0319 22:27:51.376346 5080 net.cpp:705]复制源层pool4 / 3x3_s2
- I0319 22:27:51.376353 5080 net.cpp:705]复制源层pool4 / 3x3_s2_pool4 / 3x3_s2_0_split
- I0319 22:27:51.376359 5080 net.cpp:705]复制源层inception_5a / 1x1
- I0319 22:27:51.378186 5080 net.cpp:705]复制源层inception_5a / relu_1x1
- I0319 22:27:51.378196 5080 net.cpp:705]复制源层inception_5a / 3x3_reduce
- I0319 22:27:51.379343 5080 net.cpp:705]复制源层inception_5a / relu_3x3_reduce
- I0319 22:27:51.379353 5080 net.cpp:705]复制源层inception_5a / 3x3
- I0319 22:27:51.383293 5080 net.cpp:705]复制源层inception_5a / relu_3x3
- I0319 22:27:51.383303 5080 net.cpp:705]复制源层inception_5a / 5x5_reduce
- I0319 22:27:51.383548 5080 net.cpp:705]复制源层inception_5a / relu_5x5_reduce
- I0319 22:27:51.383558 5080 net.cpp:705]复制源层inception_5a / 5x5
- I0319 22:27:51.384449 5080 net.cpp:705]复制源层inception_5a / relu_5x5
- I0319 22:27:51.384459 5080 net.cpp:705]复制源层inception_5a / pool
- I0319 22:27:51.384465 5080 net.cpp:705]复制源层inception_5a / pool_proj
- I0319 22:27:51.385397 5080 net.cpp:705]复制源层inception_5a / relu_pool_proj
- I0319 22:27:51.385406 5080 net.cpp:705]复制源层inception_5a / output
- I0319 22:27:51.385414 5080 net.cpp:705]复制源层inception_5a / output_inception_5a / output_0_split
- I0319 22:27:51.385421 5080 net.cpp:705]复制源层inception_5b / 1x1
- I0319 22:27:51.388157 5080 net.cpp:705]复制源层inception_5b / relu_1x1
- I0319 22:27:51.388166 5080 net.cpp:705]复制源层inception_5b / 3x3_reduce
- I0319 22:27:51.389539 5080 net.cpp:705]复制源层inception_5b / relu_3x3_reduce
- I0319 22:27:51.389549 5080 net.cpp:705]复制源层inception_5b / 3x3
- I0319 22:27:51.395212 5080 net.cpp:705]复制源层inception_5b / relu_3x3
- I0319 22:27:51.395225 5080 net.cpp:705]复制源层inception_5b / 5x5_reduce
- I0319 22:27:51.395584 5080 net.cpp:705]复制源层inception_5b / relu_5x5_reduce
- I0319 22:27:51.395594 5080 net.cpp:705]复制源层inception_5b / 5x5
- I0319 22:27:51.396921 5080 net.cpp:705]复制源层inception_5b / relu_5x5
- I0319 22:27:51.396931 5080 net.cpp:705]复制源层inception_5b / pool
- I0319 22:27:51.396939 5080 net.cpp:705]复制源层inception_5b / pool_proj
- I0319 22:27:51.397862 5080 net.cpp:705]复制源层inception_5b / relu_pool_proj
- I0319 22:27:51.397871 5080 net.cpp:705]复制源层inception_5b / output
- I0319 22:27:51.397879 5080 net.cpp:705]复制源层pool5 / 7x7_s1
- I0319 22:27:51.397886 5080 net.cpp:705]复制源层pool5 / drop_7x7_s1
- I0319 22:27:51.397893 5080 net.cpp:705]复制源层loss3 /分类器
- I0319 22:27:51.406652 5080 net.cpp:702]忽略源层loss3 / loss3
材料集合:
http://deeplearning.net/2014/09/19/googles-entry-to-imagenet-2014-challenge/
[1] Imagenet 2014 LSVRC结果, http : //karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/,最后检索:19 -09-2014。
[2] Christian Szegedy,Wei Liu,Yangqing Jia,Pierre Sermanet,Scott Reed,Dragomir Anguelov,Dumitru Erhan,Vincent Vanhoucke,Andrew Rabinovich,Going Deeper with Convolutions,Arxiv链接:http : //arxiv.org/abs/1409.4842。
[3] GoogLeNet演示, http ://image-net.org/challenges/LSVRC/2014/slides/GoogLeNet.pptx,最后检索的:19-09.2014。
[4]我从竞争对手的网络上学到的东西, http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet /最后检索日期:19-09-2014。
[5] Girshick,Ross,et al。“丰富的特征层次结构,用于精确的对象检测和语义分割。” arXiv preprint arXiv:1311.2524 (2013)。