Tensorflow_07A_写入 TFRecord 与数据序列化
Brief 概述
前面所有章节中我们主要重点放在算法的框架构建上,比较少关注数据集本身的特性,也因此使用了最简单的对象指向的方式,把数据集里面的内容导出到一个设定好的对象中,并以此对象作为整个算法的输入,开始一系列的计算训练。然而,随着训练的复杂度和数据集的总量提升,数据与硬件本身的问题也逐渐浮现,如下图所示:
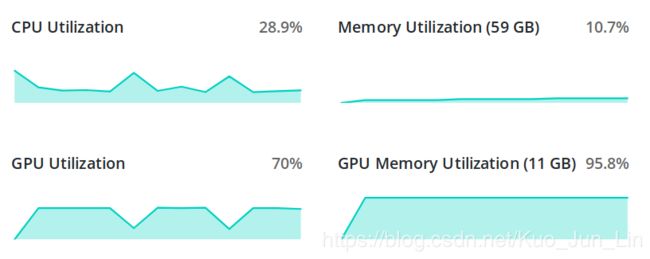
每当一个 epoch 训练完毕,接着下一个 epoch 的时候,硬件会因为数据集读取的不流畅,导致 CPU 在数据处理的时候增加了非常多的负担,同时负责运算框架本身的 GPU 却因此得到一定程度的休息,大大减缓了训练时计算强度的同时,也代表了资源的浪费,因此我们需要优化数据导入的方式。
前面章节我们理解了数据集基本上都是使用二进制的方式把数据保存在电脑中,如果我们需要加载的话,则需要使用二进制读取的方式转译成人们读得懂得 8/16/32/64 等位元,把这些转译的数据指向给一个物件,并最终放入数据流图中。然而只有小的数据集有办法被这个方式导入,如果碰上大的数据集,则需要使用到 Tensorflow 模块中的 tf.TFRecord 方法更好的预处理数据,使得运算过程中在缓存和计算资源的使用上能够最大化其效率。
近期 Tensorflow 更新过后,把 TFRecord 放入了 tensorflow.contrib.dataset 模块中,更好的把数据预处理的环节融入了整个框架里,更加值得我们学习。
Tensorflow TFRecord 数据格式
数据格式的使用,址在提升数据读取的效率,同时可以兼容所有的电子设备,在数据传输的过程中不失真,而其中最常见的数据格式有两种:
- .json (JSON - mostly for browsers)
- .proto (protocol buffer - mostly for servers)
他们之间各有优劣,不过细节不在此展开,而 TFRecord 即为后者 protocol buffer 数据格式的一种分支。
TFRecord 数据格式是 Tensorflow 独有的数据格式,原因只在于它把标签和数据本身使用了 .proto 的形式储存在同一个文件中,储存数据的方式为二进制,并非专为 tf 创造出来的特殊数据格式。
TFRecord 也是 Dataset API 的功能之一,是 Tensorflow 中层 API 的一员,这些 API 并不像高层 API 如 keras 强调如何简化网络结构的搭建,而是把每个跟数据集相关的函数功能做一个打包和嫁接,帮助运算过程中的环节上操作更有效率。
使用 TFRecords 亦是如此,其优势陈列如下:
- 二进制数据存取节省数据处理环节上的时间
- 高效的数据处理同时也节省缓存空间使用
- 函数本身即为 API 的一部分,因此没有与框架的匹配问题
对比于直接使用图像数据,其节省时间的流程图如下:
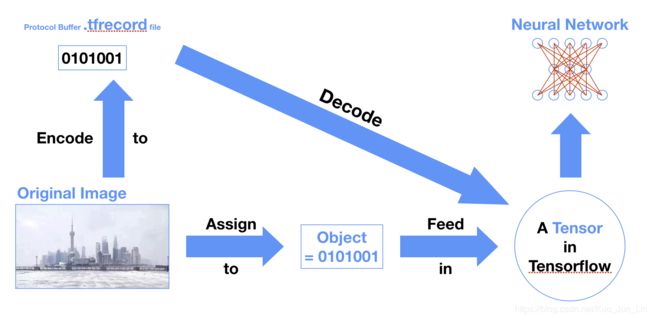
然而,目前要把一个数据集转换成 TFRecords 格式的时候,并没有一个简单的函数直接呼叫后完成所有过程,都需要从一步一步的细节着手,方可输出成目标格式的文档。下面描述转换需要的步骤。
Save to TFRecord 存档 (官网代码)
如同前面提到的,数据储存后得到的格式是二进制的,因此在写入文件时需要应对目标储存方式的数据结构特征给出一个步骤,如下陈列:
- Specify the structure. 提前声明其数据结构
- Serialize the data format. 序列化这些二进制数据
- Write them to a disk. 把序列化后的数据写入硬盘中保存
1. Data Structure 数据结构
数据之所以要有结构,主要是因为数据有特征属性,属性下面可能还有子属性,层叠关系才逐渐的发展成为了结构,而这类有结构的数据也正符合我们保存 TFRecords 的目的。如上面内容提及,保存好的文件本身是一个序列化的二进制文件,因此我们需要提前把数据用 Tensorflow 看得懂的方式包装起来后,才可以存档。一个含有特征属性的数据长得如下样貌:
| Name | number | Info | ||
|---|---|---|---|---|
| Tall | Age | Gender | ||
| James | 1.78 | 28 | [email protected] | Male |
| May | 1.65 | 24 | [email protected] | Female |
| Nicolas | 1.74 | 27 | [email protected] | Male |
如果用 python 代码表示上述表格,则如下演示:
import tensorflow as tf
import numpy as np
import sys
data = {
'Name': np.array(['James']),
'Tall': np.array([1.78]),
'Age': np.array([28]),
'Email': ['[email protected]'],
'Gender': np.array(['Male'])
}以上面表格为举例,将之保存成 TFRecord 的步骤如下:
Step 1-1
从数据的特征属性最小组成单元开始封装,面对不同数据类型的封装方式主要如下三个,其中要注意的是如果式字符串,必须先转换成二进制形式,Python 原生的数据类型使用 .encode 方法,而 numpy 的数据类型使用 .tobytes()。
Name_BL = tf.train.BytesList(value=[data['Name'].tobytes()])
Tall_FL = tf.train.FloatList(value=data['Tall'])
Age_IL = tf.train.Int64List(value=data['Age'])
Email_BL = tf.train.BytesList(value=[i.encode('utf-8') for i in data['Email']])
Gender_BL = tf.train.BytesList(value=[data['Gender'].tobytes()])Step 1-2
接着一行一行把数据用 tf.train.Feature 函数打包成 Tensorflow 看得懂的属性。
feature_n = tf.train.Feature(bytes_list=Name_BL)
feature_t = tf.train.Feature(float_list=Tall_FL)
feature_a = tf.train.Feature(int64_list=Age_IL)
feature_e = tf.train.Feature(bytes_list=Email_BL)
feature_g = tf.train.Feature(bytes_list=Gender_BL)Step 1-3
把这些属性排布成一个完整的字典,指向给一个物件名,再使用 tf.train.Features 方法,把创建好的字典对象一次传入该方法的参数中。
Info_dict = {
'name': feature_n,
'tall': feature_t,
'age': feature_a,
'email': feature_e,
'gender': feature_g
}
Info = tf.train.Features(feature=Info_dict)
Step 1-4
最后使用 tf.train.Example 方法,建构出属于 TFRecord 特有的数据结构,至此所有数据结构已经建构完毕,接着进入创建文件流程。
example = tf.train.Example(features=Info)
# This is a protocol buffer developed by Google in 2008, widely
# used to enhance data deposition and loading between servers.
print(example)
features {
feature {
key: "age"
value {
int64_list {
value: 28
}
}
}
feature {
key: "email"
value {
bytes_list {
value: "[email protected]"
}
}
}
feature {
key: "gender"
value {
bytes_list {
value: "M\000\000\000a\000\000\000l\000\000\000e\000\000\000"
}
}
}
feature {
key: "name"
value {
bytes_list {
value: "J\000\000\000a\000\000\000m\000\000\000e\000\000\000s\000\000\000"
}
}
}
feature {
key: "tall"
value {
float_list {
value: 1.7799999713897705
}
}
}
}
2. Serialization 序列化
经过一系列的数据建构后,序列化的过程很简单,只需要使用 tf.train.Features() 类里面的一个方法: SerializeToString() ,就可以完成。
3. Write to a disk 存入硬盘
接着使用 Tensorflow 内置的写入方法: tf.python_io.TFRecordWriter() ,使用这个方法的前提是要被写入的数据已经经过序列化处理,实际上使用方法的代码如下(特别需要注意所有被包含到此序列的数据,其数据类型必须相同):
with tf.python_io.TFRecordWriter('example.tfrecord') as writer:
writer.write(example.SerializeToString())
sys.stdout.flush()
# This is the characters stored in...
# ---------------------------------------
# a400 0000 0000 0000 4113 b828 0aa1 010a
# 0c0a 0361 6765 1205 1a03 0a01 1c0a 1e0a
# 0667 656e 6465 7212 140a 120a 104d 0000
# 0061 0000 006c 0000 0065 0000 000a 100a
# 0474 616c 6c12 0812 060a 040a d7e3 3f0a
# 200a 046e 616d 6512 180a 160a 144a 0000
# 0061 0000 006d 0000 0065 0000 0073 0000
# 000a 3d0a 0565 6d61 696c 1234 0a32 0a30
# 4a00 0000 6100 0000 6d00 0000 6500 0000
# 7300 0000 4000 0000 6700 0000 6f00 0000
# 7600 0000 2e00 0000 7500 0000 6b00 0000
# 54d8 431c
# ---------------------------------------
# ... the example.tfrecord file.4. Example v.s. SequenceExample()
现在我们都了解了把数据用序列化的二进制模式存成 TFRecord 的过程,但是如果目标的数据其结构是列表里面还有一个列表的形式,也就是说数据在结构中的结构里,那么 tf.train.Example() 方法将不适用,将以 tf.train.SequenceExample() 取代之,而其储存的数据类型是 list of lists 特殊的 tf 二进制数据。
总体而言,此孪生兄弟在步骤上呼叫的函数原理大同小异,顺序如下:
- tf.train.BytesList(value=[ ])...FloatList()...Int64List() 打包最原始的数据
- tf.train.Feature() 打包步骤一建立结构的数据
- tf.train.FeatureList(feature=[ ]) 打包一个列表,其每个列表元素都对应道一个步骤二产生的结果,例如 [tf.train.Feature(value=1), tf.train.Feature(value=2), ...]
- tf.train.FeatureLists(feature_list={ }) 注意这边打包的是一个字典,字典键名字同样可以自己取
- tf.train.SequenceExample(context, feature_lists) 他有两个参数接收口,第一个口打包和 .Example 一模一样的物件,而第二个参数则是打包步骤四回传的数据结构
必须注意的是,如果要打包数据结构成为一个列表,必须先确定其数据类型的一致性。延续上面举例,打包数据的代码如下:
Age_FL = tf.train.FloatList(value=data['Age'])
feature_a = tf.train.Feature(float_list=Age_FL)
num_list = [feature_t, feature_a]
num = tf.train.FeatureList(feature=num_list)
info_list = [feature_e, feature_g]
info = tf.train.FeatureList(feature=info_list)
all_dict = {
'Info': info,
'Number': num
}
info_FLs = tf.train.FeatureLists(feature_list=all_dict)
people_dict = {'name': feature_n}
people_Fs = tf.train.Features(feature=people_dict)
sequence_example = tf.train.SequenceExample(context=people_Fs,
feature_lists=info_FLs)
print(sequence_example)
with tf.python_io.TFRecordWriter('sequence_example.tfrecord') as s_writer:
s_writer.write(sequence_example.SerializeToString())
sys.stdout.flush()
context {
feature {
key: "name"
value {
bytes_list {
value: "J\000\000\000a\000\000\000m\000\000\000e\000\000\000s\000\000\000"
}
}
}
}
feature_lists {
feature_list {
key: "Info"
value {
feature {
bytes_list {
value: "[email protected]"
}
}
feature {
bytes_list {
value: "M\000\000\000a\000\000\000l\000\000\000e\000\000\000"
}
}
}
}
feature_list {
key: "Number"
value {
feature {
float_list {
value: 1.7799999713897705
}
}
feature {
float_list {
value: 28.0
}
}
}
}
}
# This is the characters stored in...
# ---------------------------------------
# 9c00 0000 0000 0000 cba9 5dfa 0a22 0a20
# 0a04 6e61 6d65 1218 0a16 0a14 4a00 0000
# 6100 0000 6d00 0000 6500 0000 7300 0000
# 1276 0a54 0a04 496e 666f 124c 0a34 0a32
# 0a30 4a00 0000 6100 0000 6d00 0000 6500
# 0000 7300 0000 4000 0000 6700 0000 6f00
# 0000 7600 0000 2e00 0000 7500 0000 6b00
# 0000 0a14 0a12 0a10 4d00 0000 6100 0000
# 6c00 0000 6500 0000 0a1e 0a06 4e75 6d62
# 6572 1214 0a08 1206 0a04 0ad7 e33f 0a08
# 1206 0a04 0000 e041 293b a9b3
# ---------------------------------------
# ... the sequence_example.tfrecord file.至此,所有的数据都已经被序列化到了 .protobuf 文档中,下一章将接着描述如何读取数据回到原来储存的状态。