爬虫学习笔记四、 python爬虫实战,爬取图书馆资料,存储到mysql数据库
1、设置url
进入图书馆书目检索系统,分析它的url,可以很容易找到规律就是它的后缀no=0000+五位的图书编码,例如:http://210.44.58.116:8080/opac/item.php?marc_no=0000560645
利用规律我们就可以这样来遍历url,代码如下:
def geturl(start):
#start为开始的图书编码
url='http://210.44.58.116:8080/opac/item.php?marc_no=0000'
for i in range(start,600000):
a="%06d"%i
url1=url+str(a) 2、分析页面源码,筛选需要获取的数据,编写正则表达式(以书名为例)
打开页面源码,找到题名所在的位置,如下:
通过页面分析到,unicode乱码的部分Python和HDF5大数据应用
为我们需要的书名
爬取书名的代码如下:
def getdb(url,i):
html=urllib.request.urlopen(url).read().decode('utf-8')
try:
#书名
name = re.compile('
因为有乱码存在所以我们需要乱码处理模块,代码如下:
def str_jiequ(s):
b=''
for i in range(0,int(len(s)/8)):
a=str((bytes(r'\u'+s[(3+i*8):(7+i*8)],'ascii')).decode('unicode_escape'))
b=b+a
return b
3、连接mysql,添加到mysql数据库
def db( name):
name=str(name)
try:
# 获取数据库连接
conn = pymysql.connect(host='localhost', user='root', password='root', db='pythonDB', port=3306, charset='utf8')
cur = conn.cursor() # 获取一个游标
sql = " INSERT INTO library ( t_name ) VALUES (%s );"
cur.execute(sql, (name))
conn.commit()
cur.close() # 释放游标
conn.close() # 释放资源
except Exception as e:
print("异常" + e) 4、完善代码,实现爬取书名、作者、学科主题、分类号的功能
完整代码如下
import pymysql
import urllib.request
import re
def db( name,author,keyword,coden,i):
name=str(name)
author=str(author)
keyword=str(keyword)
coden=str(coden)
try:
# 获取数据库连接
conn = pymysql.connect(host='localhost', user='root', password='root', db='pythonDB', port=3306, charset='utf8')
cur = conn.cursor() # 获取一个游标
sql = " INSERT INTO library ( t_name , t_automer , t_keyword , t_coden ,t_num ) VALUES (%s,%s,%s,%s,%s);"
cur.execute(sql, (name, author, keyword, coden,i))
conn.commit()
#成功添加打印输出结果
print("成功添加第" + str(i) + "条图书 ------ 书名:" + name + ' 作者:' + author + " 学科:" + keyword + " 编号:" + coden + " 图书序列:" + str(i))
cur.close() # 释放游标
conn.close() # 释放资源
except Exception as e:
print("异常" + e)
geturl(i + 1)
#格式化unicode字符串为中文
def str_jiequ(s):
b=''
for i in range(0,int(len(s)/8)):
a=str((bytes(r'\u'+s[(3+i*8):(7+i*8)],'ascii')).decode('unicode_escape'))
b=b+a
return b
def getData(url,i):
try:
html = urllib.request.urlopen(url).read().decode('utf-8')
#书名
name = re.compile('(.*?)').findall(html)
author = str_jiequ(author[0][1])
#学科主题
keyword = re.compile('(.*?)').findall(html)
coden = str_jiequ(coden[0][1])
#链接数据库,并将数据添加到数据库中
db(name, author, keyword, coden,i)
except IndexError:
print("部分信息获取失败!")
geturl(i + 1)
except Exception as e:
print("错误" + e)
geturl(i + 1)
def geturl(start):#start为开始的添加的第一个地址
url='http://210.44.58.116:8080/opac/item.php?marc_no=0000'
for i in range(start,600000):
#设置为六位数字前面用零补全
a="%06d"%i
a=str(a)
#将后缀添加到url后
url1=url+a
print(url)#打印url
getData(url1,i)
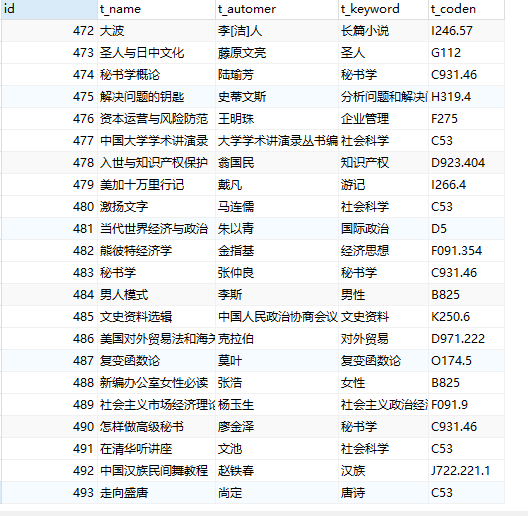
geturl(0) 运行结果:

查看数据库:
存在问题:
1、数据量比较大,六十万条信息,爬取速度太慢,使用多线程+异步+分布式应该会解决
2、正则表达式写的不够好,没有找到其他更好的办法,
3、有些数据爬取失败,具体原因还没去找
4、在爬取数据量很大的时候,可能会出现堆栈溢出,分析原因可能是正则表达式采用的大量递归算法所致,暂时没有找到合理的解决方案
5、有些时候会出现远程服务器断开连接的情况
11/22更新:
上面写的程序会出现堆栈溢出问题,之前以为是因为正则的原因,后来好好看了一下是递归调用geturl(I+1)造成的,经过修改后经一万条信息爬取测试后没有出现问题,修改后的代码如下:\
import pymysql
import urllib.request
import re
def db( name,author,keyword,coden,i):
name=str(name)
author=str(author)
keyword=str(keyword)
coden=str(coden)
try:
# 获取数据库连接
conn = pymysql.connect(host='localhost', user='root', password='root', db='pythonDB', port=3306, charset='utf8')
cur = conn.cursor() # 获取一个游标
sql = " INSERT INTO library ( t_name , t_automer , t_keyword , t_coden ,t_num ) VALUES (%s,%s,%s,%s,%s);"
cur.execute(sql, (name, author, keyword, coden,i))
conn.commit()
print("成功添加第" + str(i) +"条图书 ------ 书名:" + name +' 作者:' + author + " 学科:" + keyword + " 编号:" + coden+" 图书序列:"+str(i))
except Exception as e:
print("异常:" + e)
finally:
cur.close() # 释放游标
conn.close() # 释放资源
def str_jiequ(s):
b=''
for i in range(0,int(len(s)/8)):
a=str((bytes(r'\u'+s[(3+i*8):(7+i*8)],'ascii')).decode('unicode_escape'))
b=b+a
return b
def getdb(url,i):
html = urllib.request.urlopen(url).read().decode('utf-8')
#书名
name = re.compile('(.*?)').findall(html)
author = str_jiequ(author[0][1])
#学科主题
keyword = re.compile('(.*?)').findall(html)
coden = str_jiequ(coden[0][1])
db(name, author, keyword, coden,i)
def geturl(start):
url='http://210.44.88.116:8080/opac/item.php?marc_no=0000'
i=start
while i<100000:
try:
a="%06d"%i
a=str(a)
url1=url+a
print(url1)
getdb(url1,i)
except Exception as e:
print("部分信息获取失败!")
finally:
i+=1
geturl(0) 昨晚跑了几个小时,测试结果:
1、爬了323K条数据后服务器无法访问了,测试更换ip也不能访问,应该是服务器那边这么多的访问量出现了问题,可能是数据库溢出了。
2、没有再次出现堆栈溢出的错误,更新的版本应该是没问题了,其他错误也没出现。
准备开始学习进程线程方面的知识,试试多线程多进程并发执行的效果,不过对于这个网站还行,对于别的做的安全性比较好的网站,在短时间内大量访问的时候会被检测到而禁封Ip,可以使用ip代理来解决。