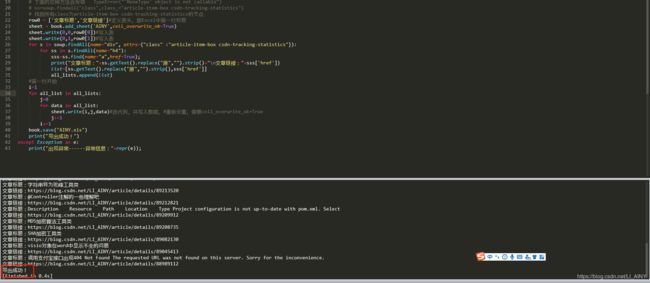
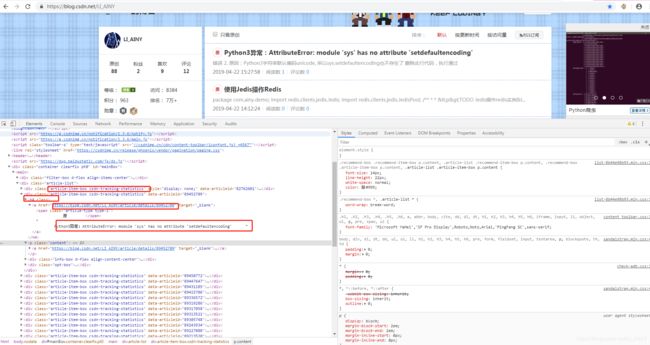
- 查看要爬的网页的源代码,准备爬取所有文章和链接
- 代码
import requests
from bs4 import BeautifulSoup
url="https://blog.csdn.net/LI_AINY"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
ss=None
try:
r=requests.get(url,headers=headers,timeout=30)
soup = BeautifulSoup(r.text, 'lxml')
for s in soup.findAll(name="div", attrs={"class" :"article-item-box csdn-tracking-statistics"}):
for ss in s.findAll(name="h4"):
sss=ss.find(name="a",href=True);
print("文章标题:"+ss.getText().replace("原","").strip()+"\n文章链接:"+sss['href'])
except Exception as e:
print("出现异常------异常信息:"+repr(e));
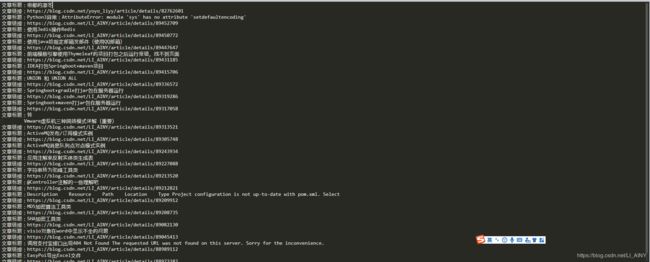
- 结果
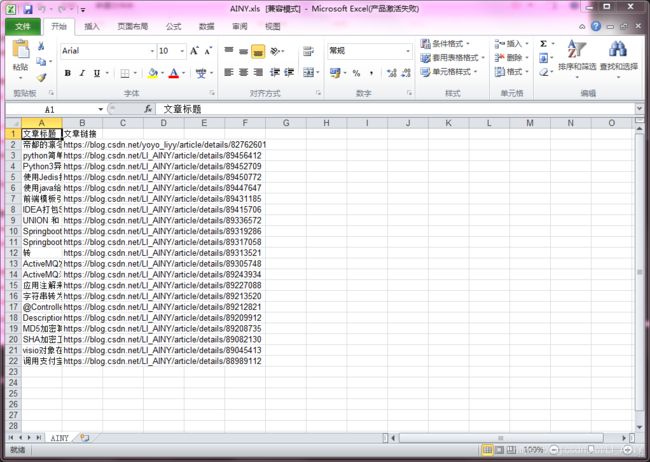
- 学会上面的例子后,可以加上导出到excel
import requests
import xlwt
from bs4 import BeautifulSoup
url="https://blog.csdn.net/LI_AINY"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
ss=None
try:
r=requests.get(url,headers=headers,timeout=30)
all_lists = []
book = xlwt.Workbook(encoding='utf-8')
soup = BeautifulSoup(r.text, 'lxml')
row0 = ['文章标题','文章链接']
sheet = book.add_sheet('AINY',cell_overwrite_ok=True)
sheet.write(0,0,row0[0])
sheet.write(0,1,row0[1])
for s in soup.findAll(name="div", attrs={"class" :"article-item-box csdn-tracking-statistics"}):
for ss in s.findAll(name="h4"):
sss=ss.find(name="a",href=True);
print("文章标题:"+ss.getText().replace("原","").strip()+"\n文章链接:"+sss['href'])
list=[ss.getText().replace("原","").strip(),sss['href']]
all_lists.append(list)
i=1
for all_list in all_lists:
j=0
for data in all_list:
sheet.write(i,j,data)
j+=1
i+=1
book.save("AINY.xls")
print("导出成功!")
except Exception as e:
print("出现异常------异常信息:"+repr(e));
- 结果