SPSS(二)SPSS实现多因素方差分析模型(图文教程+数据集)
SPSS(二)SPSS实现多因素方差分析模型
单因素方差分析上一篇博客https://blog.csdn.net/LuYi_WeiLin/article/details/89917656已经介绍完毕
这篇博客我们主要来学习多因素方差分析
多因素方差分析,就是同时考虑若干个控制因素的情况下,分别分析它们的改变是否造成观察变量的显著变动
(多个自变量,一个因变量)自变量类型以分类变量为主也可以是连续变量,不过连续变量一般是通过找出它与因变量的回归关系来控制其影响,因变量为连续变量
实例:同时考虑职业(以下三个职业)和性别对收入的影响
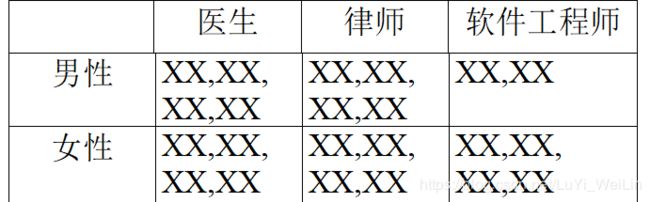
以上面这个实例,如何写模型表达式呢?
如果只研究职业的影响

如果只研究性别的影响
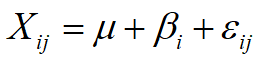
同时考虑职业和性别对收入的影响
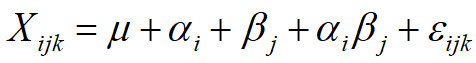
只考虑主效应,交互项在现实中没有统计学意义(当然在后面模型检验中也会给出其相应的检验P值),可以简写成
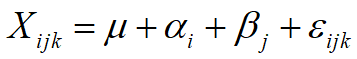
方差分析模型常用术语
- 因素(Factor)简单来说就是自变量
因素是可能对因变量有影响的变量,一般来说,因素会有不止一个水平,而分析的目的就是考察或比较各个水平对因变量的影响是否相同。
- 水平(Level)简单来说就是自变量的所有取值类型
因素的不同取值等级称作水平,例如性别有男、女两个水平。
- 单元(Cell)比如下面就是6个单元
单元亦称试验单位(Experimental Unit),指各因素的水平之间的每种组合。指各因素各个水平的组合,例如在研究性别(二水平)、血型(四水平)对成年人身高的影响时,该设计最多可以有2*4=8个单元。注意在一些特殊的试验设计中,可能有的单元在样本中并不会出现,如拉丁方设计。
- 元素(Element)
指用于测量因变量值的观察单位,比如研究职业与收入间的关系,月收入是从每一位受访者处得到,则每位受访者就是试验的元素
一个单元格内可以有多个元素,也可以只有一个,甚至于没有元素。
这主要在一些特殊的设计方案中出现,如正交设计
- 均衡(Balance)
如果在一个实验设计中任一因素各水平在所有单元格中出现的次数相同,且每个单元格内的元素数均相同,则该试验是均衡的,否则,就被称为不均衡。不均衡的实验设计在分析时较为复杂,需要对方差分析模型作特别设置才能得到正确的分析结果。
- 交互作用(Interaction)
如果一个因素的效应大小在另一个因素不同水平下明显不同,则称为两因素间存在交互作用。当存在交互作用时,单纯研究某个因素的作用是没有意义的,必须分另一个因素的不同水平研究该因素的作用大小。
因素的分类
简单来说因素根据类型不同分为固定因素(分类的自变量)、随机因素(分类的自变量)、协变量(连续的自变量)
- 固定因素(Fixed Factor)
指的是该因素在样本中所有可能的水平都出现了。从样本的分析结果中就可以得知所有水平的状况,无需进行外推。
绝大多数情况下,研究者所真正关心的因素都是固定因素。
性别:只有两种
疗法:只有三种
- 随机因素(Random Factor)
该因素所有可能的取值在样本中没有都出现,目前在样本中的这些水平是从总体中随机抽样而来,如果我们重复本研究,则可能得到的因素水平会和现在完全不同!
这时,研究者显然希望得到的是一个能够“泛化”,即对所有可能出现的水平均适用的结果。这不可避免的存在误差,需要估计误差的大小,因此被称为随机因素。
- 协变量(Covariates)
指对因变量可能有影响,需要在分析时对其作用加以控制的连续性变量
实际上,可以简单的把因素和协变量分别理解为分类自变量和连续性自变量
当模型中存在协变量时,一般是通过找出它与因变量的回归关系来控制其影响
方差分析模型的适用条件
从模型表达式出发得到的提示
各样本的独立性:只有各样本为相互独立的随机样本,才能保证变异的可加性(可分解性)
正态性:即个单元格内的所有观察值系从正态总体中抽样得出
方差齐:各个单元格中的数据离散程度均相同,即各单元格方差齐
在多因素方差分析中,由于个因素水平组合下来每个单元格内的样本量可能非常少,这样直接进行正态性、方差齐检验的话检验效能很低,实际上没什么用,因此真正常见的做法是进行建模后的残差分析
方差分析模型的检验层次
1.对总模型进行检验
2.对模型中各交互效应、主效应进行检验(要先分析交互项)
2.1交互项有统计学意义:分解为各种水平的组合情况进行检验
2.2交互项无统计学意义:进行主效应各水平的两两比较
案例一:固定因素--因变量
超市规模、货架位置与销量的关系
现希望现希望考察对超市中销售的某种商品而言,是否其销售额会受到货架上摆放位置的影响,除此以外,超市的规模是否也会有所作用?甚或两者间还会存在交互作用?
Berenson和Levine(1992)着手研究了此问题,他们按照超市的大小(三水平)、摆放位置(四水平)各随机选取了两个点,记录其同一周内该货物的销量。
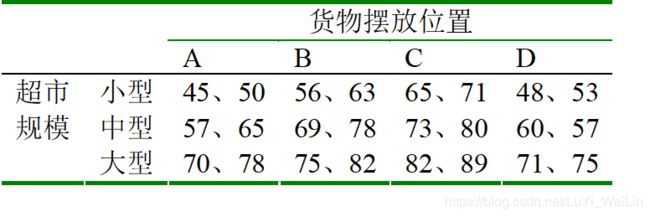
数据集如下

1 A 45.0
1 A 50.0
1 B 56.0
1 B 63.0
1 C 65.0
1 C 71.0
1 D 48.0
1 D 53.0
2 A 57.0
2 A 65.0
2 B 69.0
2 B 78.0
2 C 73.0
2 C 80.0
2 D 60.0
2 D 57.0
3 A 70.0
3 A 78.0
3 B 75.0
3 B 82.0
3 C 82.0
3 C 89.0
3 D 71.0
3 D 75.0
第一步:检验一下实验是否为均衡实验
分析--统计描述--交叉表
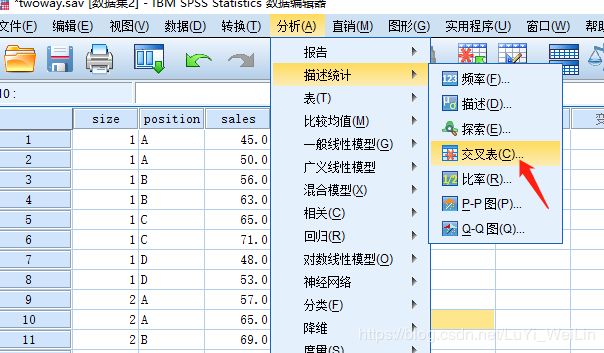
各单元元素数量一致,所以为均衡实验

第二步:模型检验
分析--一般线性模型--单变量(单个因变量)
结果解读
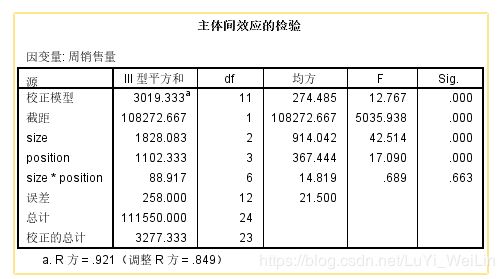
首先校正模型的SIg.显著性检验小于显著性水平0.05,所以拒绝原假设,所以使用线性来拟合这个模型是有效的
下面的截距、size、position、size*position和下面表达式相对应
先观察主效应显著性为0.663大于显著性水平0.05,所以没有意义,可以剔除重新再做模型,假如不剔除会对后面有意义的产生影响,结果也会不准确
如何剔除(分析--一般线性模型--单变量--设定)
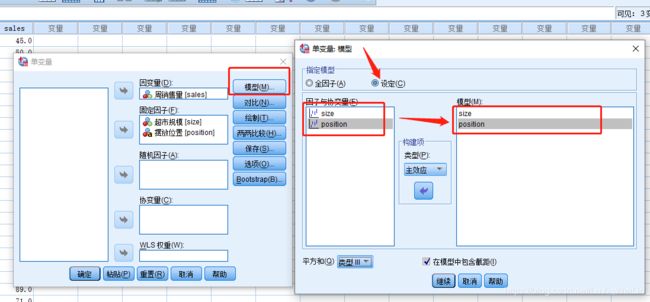
之后重建模型检验得到这样

之后我么就可以看主效应size、position两个固定因素各自的单因素方差分析,进行主效应各水平的两两比较
具体详细就不讲了,大家可以参考我的博客https://blog.csdn.net/LuYi_WeiLin/article/details/89917656
第三步:模型检验
变量的独立性通过,正态检验和方差齐性我们通过残差图来查看
分析--一般线性模型--单变量
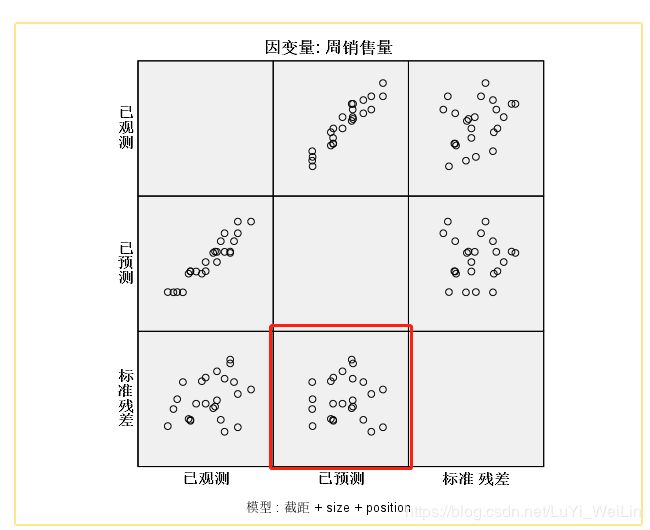
一般我们只关心这幅图
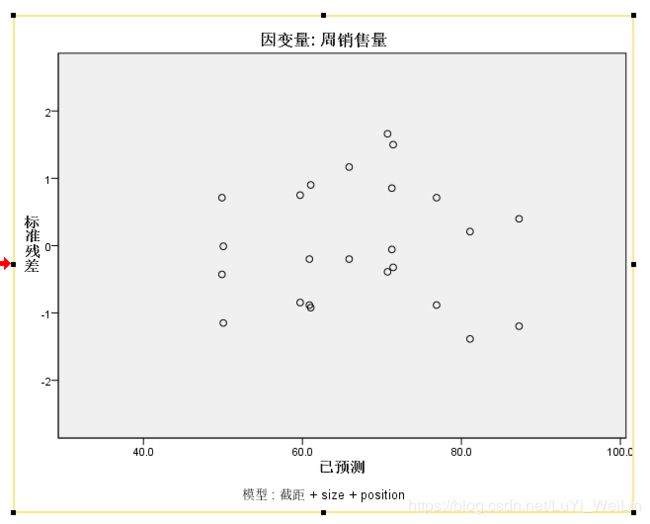
如何放大,只显示这张图(双击这张图)
按照下面的选项操作

残差图所有点都在正负3以内,没什么大问题,所以也满足正态检验和方差齐性,所以该题用多因素方差分析模型是适用的
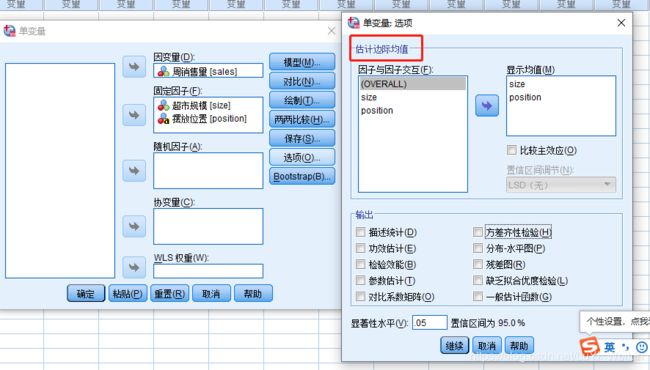
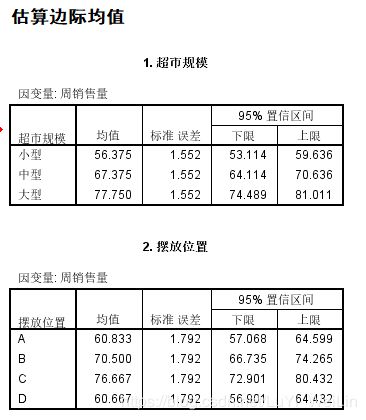
估计边界均值
所谓边际均值,就是在控制了其他因素之后,只是单纯在一个因素的作用下,因变量的变化,在普通的分析中,因变量的变化都是几个因素共同作用的结果.
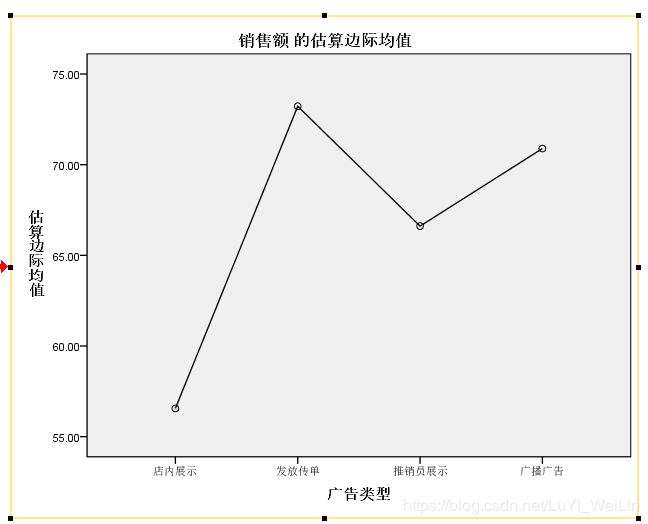
画出轮廓图
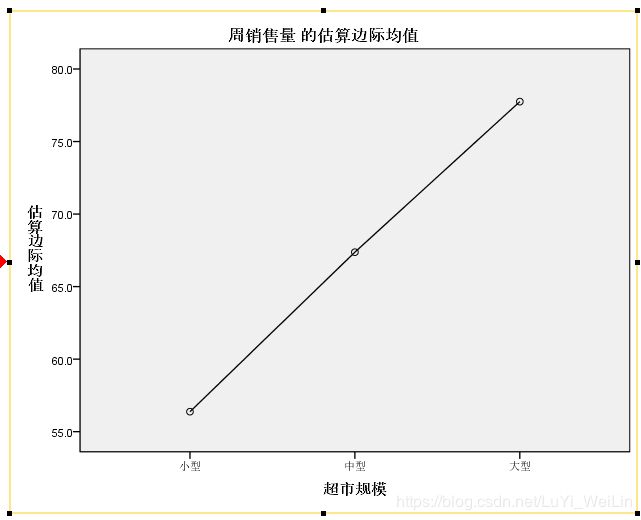
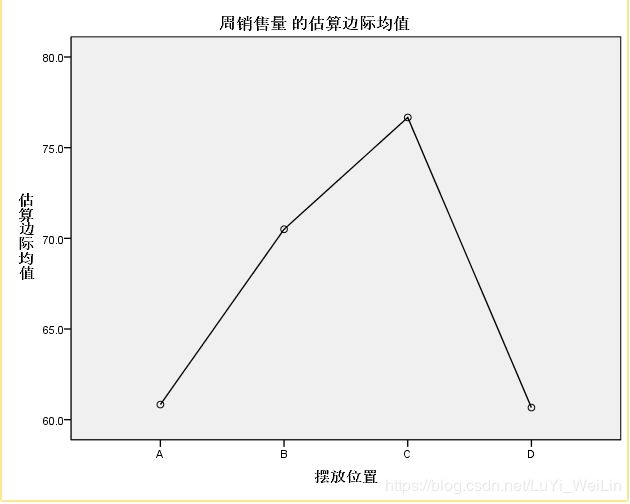
交互项不影响,轮廓图几条应平行
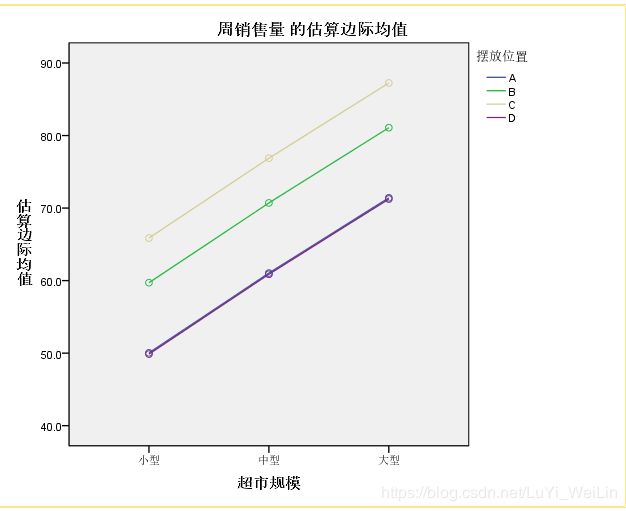
案例二:随机因素--因变量
现希望研究四种广告的宣传效果有无差异,具体的广告类型为:店内展示、发放传单、推销员展示、广播广告。在本地区共有几百个销售网点可供选择,出于经费方面的考虑,在其中随机选择了18个网点进入研究,各网点均在规定长度的时间段内使用某种广告宣传方式,并记录该时间段内的具体销售额。为减小误差,每种广告方式在每个网点均重复测量两次。
数据集如下

1.0 1.0 41.0
2.0 1.0 61.0
2.0 1.0 44.0
3.0 1.0 61.0
3.0 1.0 86.0
4.0 1.0 76.0
4.0 1.0 75.0
5.0 1.0 57.0
5.0 1.0 75.0
6.0 1.0 52.0
6.0 1.0 63.0
7.0 1.0 33.0
7.0 1.0 52.0
8.0 1.0 69.0
8.0 1.0 61.0
9.0 1.0 60.0
9.0 1.0 43.0
10.0 1.0 61.0
10.0 1.0 69.0
11.0 1.0 41.0
11.0 1.0 43.0
12.0 1.0 66.0
12.0 1.0 51.0
13.0 1.0 65.0
13.0 1.0 60.0
14.0 1.0 58.0
14.0 1.0 52.0
15.0 1.0 50.0
15.0 1.0 55.0
16.0 1.0 44.0
16.0 1.0 52.0
17.0 1.0 45.0
17.0 1.0 45.0
18.0 1.0 58.0
18.0 1.0 60.0
1.0 2.0 75.0
1.0 2.0 68.0
2.0 2.0 57.0
2.0 2.0 75.0
3.0 2.0 76.0
3.0 2.0 83.0
4.0 2.0 77.0
4.0 2.0 66.0
5.0 2.0 75.0
5.0 2.0 66.0
6.0 2.0 72.0
6.0 2.0 76.0
7.0 2.0 76.0
7.0 2.0 70.0
8.0 2.0 81.0
8.0 2.0 86.0
9.0 2.0 63.0
9.0 2.0 62.0
10.0 2.0 94.0
10.0 2.0 88.0
11.0 2.0 54.0
11.0 2.0 56.0
12.0 2.0 70.0
12.0 2.0 86.0
13.0 2.0 87.0
13.0 2.0 84.0
14.0 2.0 65.0
14.0 2.0 77.0
15.0 2.0 65.0
15.0 2.0 78.0
16.0 2.0 79.0
16.0 2.0 80.0
17.0 2.0 62.0
17.0 2.0 62.0
18.0 2.0 75.0
18.0 2.0 70.0
1.0 3.0 63.0
1.0 3.0 58.0
2.0 3.0 67.0
2.0 3.0 82.0
3.0 3.0 85.0
3.0 3.0 78.0
4.0 3.0 80.0
4.0 3.0 87.0
5.0 3.0 87.0
5.0 3.0 70.0
6.0 3.0 62.0
6.0 3.0 77.0
7.0 3.0 70.0
7.0 3.0 68.0
8.0 3.0 75.0
8.0 3.0 61.0
9.0 3.0 40.0
9.0 3.0 55.0
10.0 3.0 64.0
10.0 3.0 76.0
11.0 3.0 40.0
11.0 3.0 70.0
12.0 3.0 67.0
12.0 3.0 77.0
13.0 3.0 51.0
13.0 3.0 42.0
14.0 3.0 61.0
14.0 3.0 71.0
15.0 3.0 75.0
15.0 3.0 65.0
16.0 3.0 64.0
16.0 3.0 78.0
17.0 3.0 50.0
17.0 3.0 37.0
18.0 3.0 62.0
18.0 3.0 83.0
1.0 4.0 69.0
1.0 4.0 54.0
2.0 4.0 51.0
2.0 4.0 78.0
3.0 4.0 100.0
3.0 4.0 79.0
4.0 4.0 90.0
4.0 4.0 83.0
5.0 4.0 77.0
5.0 4.0 74.0
6.0 4.0 60.0
6.0 4.0 69.0
7.0 4.0 33.0
7.0 4.0 68.0
8.0 4.0 79.0
8.0 4.0 75.0
9.0 4.0 73.0
9.0 4.0 65.0
10.0 4.0 100.0
10.0 4.0 70.0
11.0 4.0 61.0
11.0 4.0 53.0
12.0 4.0 68.0
12.0 4.0 73.0
13.0 4.0 68.0
13.0 4.0 79.0
14.0 4.0 63.0
14.0 4.0 66.0
15.0 4.0 83.0
15.0 4.0 65.0
16.0 4.0 76.0
16.0 4.0 81.0
17.0 4.0 73.0
17.0 4.0 57.0
18.0 4.0 74.0
18.0 4.0 65.0首先还是看实验是否均衡
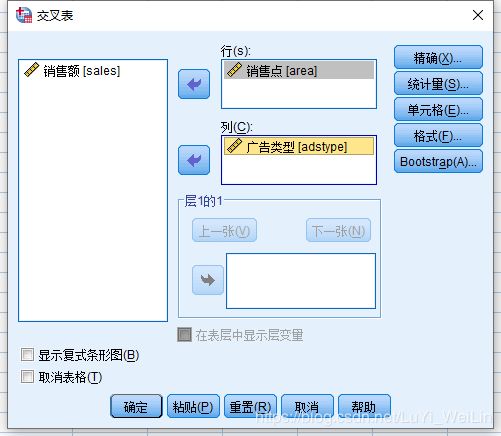

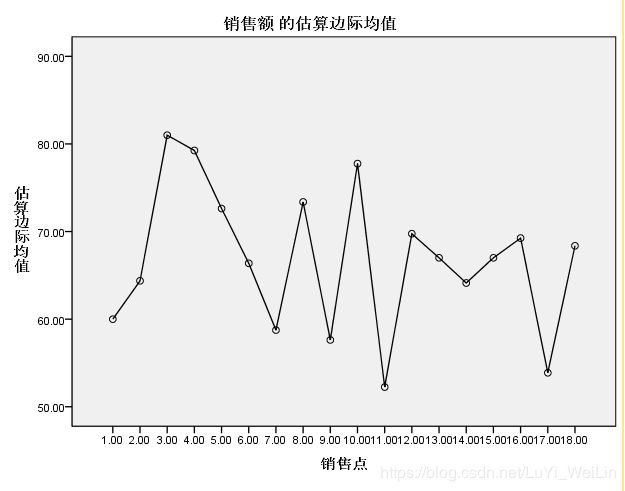
所以为均衡实验,因为网点是随机抽取的,所以不能用固定因素,要用随机因素
有随机因素就没有总的模型检验了,该因素所有可能的取值在样本中没有都出现,总的表达式无法表达出来,所以就没有总的模型检验

看交互项adstype * area 显著性大于0.05,剔除
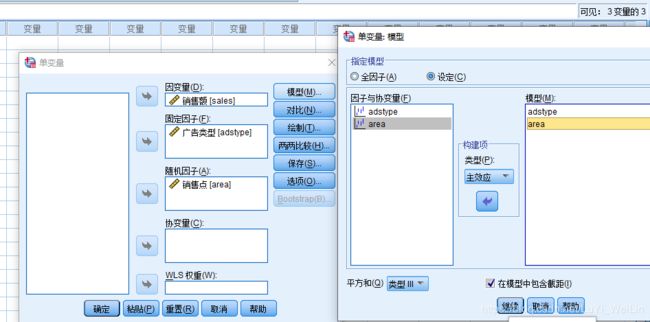
之后我们对adstype、area 进行单因素方差分析(随机因素就没有两两比较的方法了)
adstype可以进行两两比对,划分同类子集

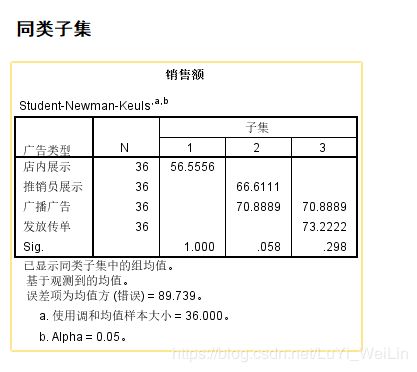
模型检验
残差分析

总体在正负3以内,没超过正负4,还行

看其轮廓图