生产环境中,如何将Kubernetes部署到AWS?

这份文档简述了我们在Zalando所学习到的关于如何在生产环境下将Kubernetes部署到AWS的经验。由于我们只是刚开始迁移到Kubernetes,因此我们并不认为我们是这个领域的专家。这个文档是共享的,希望社区中的其他人可以从我们的经验中获益。
![]()
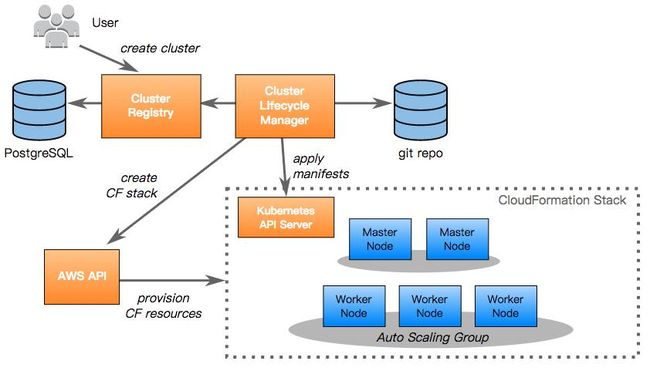
我们一个由基础设施工程师组成的团队,并且为Zalando技术交付团队提供Kubernetes集群服务。我们规划有超过30个生产环境的Kubernetes集群。以下目标可能有助于理解文档的其余部分、我们的Kubernetes设置以及我们的具体挑战:
-
无需手动操作:所有集群的更新和操作都必须是完全自动化的
-
不能有特例集群:所有的集群都应该是完全一致的,不需要任何特定的配置或调整
-
可靠性:基础设施应该是坚如磐石的,我们的交付团队委托我们的集群管理他们最关键的应用程序
-
弹性伸缩:集群应该能够自动适应已部署应用的工作负载,并且按照预期进行伸缩
-
无缝迁移:目前在AWS/STUPS[1]上已经部署的容器化的满足(云原生)12要素的应用,可以不做任何修改的情况迁移到Kubernetes
集群自动化
![]()
现在已经有很多工具可以提供Kubernetes集群。我们选择采用kube-aws[2]工具,因为它与我们当前在AWS的工作方式相相似:使用cloud-init和CloudFormation定义基础结构,并且配置这些不可变节点。CoreOS提供的容器Linux完全符合我们对于集群节点系统的理解:只提供运行容器所需要的内容,没有任何其他东西。
每一个AWS账号下面我们只创建一个Kubernetes集群。我们为生产和测试环境讽创建了独立的AWS账号和集群,同时我们会立即创建两个AWS弹性伸缩组:
-
一个主弹性绳索组,用于确保始终有两个节点用于运行API Server和Controller Manager
-
一个副弹性伸缩组,用于确保始终有2个或2个以上的节点用于运行应用Pod
这两个自动弹性伸缩组都是跨可用区(AZ)的。API Server通过一个“经典”TCP/SSL的弹性负载均衡器(ELB)与TLS一起对外公开。
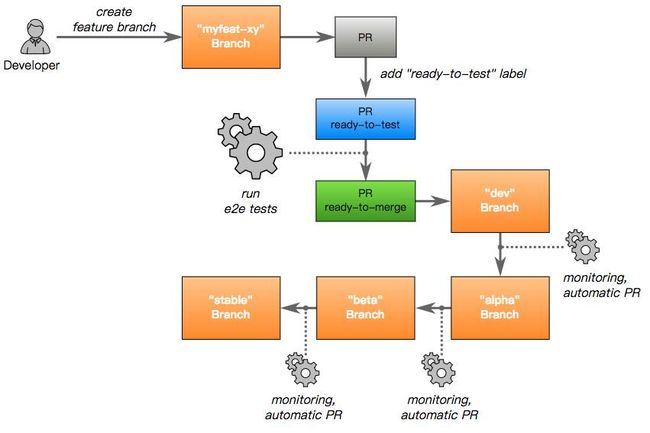
不同的集群使用了不同的通道配置(分支)。举例来说,一些非关键性的集群可能使用了具有最新特性的“alpha"通道(分支),而其它集群则使用了“Stable”通道(分支)。通道的概念类似于CoreOS管理容器linux发布的方式。
![]()
我们在AWS上提供集群,因此希望在可能的情况下与AWS的服务进行集成。kube2iam[4]守护进程可以允许我们通过添加注解(annotation)的方式将AWS IAM角色分配给Pod。我们的基础设施组件(如Autoscaler)使用了相同的机制使用IAM角色来访问AWS API(受限制API)。
![]()
由于没有在AWS上实现Ingress服务的官方方式。我们决定通过创建新的组件Kube AWS ingress Controller来实现我们的目标:
-
用ALB中止的SSL:便于使用ACM(亚马逊提供的免费CA服务),以及通过AWS IAM上传证书
-
使用新ELBv2应用负载均衡器
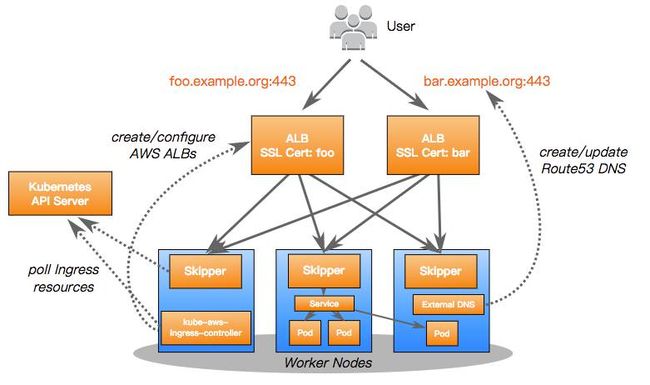
我们使用Skipper作为我们的HTTP代理,并且基于Http Header以及Path进行路由转发。 Skipper以DaemonSet的方式运行在所有的工作节点,以便于与AWS的ASG(AutoScalling Group)进行集成(新的节点会自动注册到ALB(Auto Load Balance)目标组当中)。Skipper直接与Kubernetes客户端通讯,从而定期自动更新其路由规则。
External DNS自动将Ingress主机配置到我们Route53中的DNS记录中。
![]()
理解Kubernetes的资源请求和限制是非常重要的一个事情。
默认的资源请求和限制可以通过LimitRange进行配置。这可以防止一些“愚蠢”的事情发生,比如,部署JVM应用时没有任何设置(没有内存限制,也没有JVM堆集设置),从而️消耗掉节点所有的内存。我们当前使用以下默认限制:
$ kubectl describe limits
Name: limits
Namespace: default
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- ---- --------------- ------------- -----------------------
Container cpu - 16 100m 3 -
Container memory - 64Gi 100Mi 1Gi -
CPU的默认限制为3个内核,因为我们发现这个有利于JVM应用程序快速启动。相关的详细信息,请参见我们的LimitRange YAML 清单。
我们使用了一些小的脚本并且通过使用了Downwards API在Kubernetes上运行JVM应用程序,而不需要手动设置Heap的最大值。对于某些JVM应用程序的Deployment的Container spec部分类似于以下内容:
# ...
env:
# set the maximum available memory as JVM would assume host/node capacity otherwise
# this is evaluated by java-dynamic-memory-opts in the Zalando OpenJDK base image
# see https://github.com/zalando/docker-openjdk
- name: MEM_TOTAL_KB
valueFrom:
resourceFieldRef:
resource: limits.memory
divisor: 1Ki
resources:
limits:
memory: 1Gi
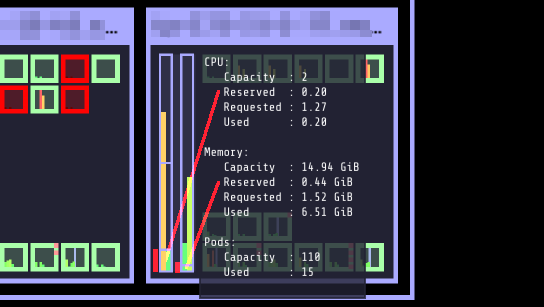
Kubelet可以被指定为系统和Kubernetes组件(Kubelet和Docker等)预留一定的资源。保留资源会从节点的资源中去除。这使得调度机制得到优化,使资源分配/使用更加透明。节点分配资源或保留的资源可以在Kubernetes操作视图查看:
![]()
Kubernetes希望容器能够处理TERM信号,或者至少在等待几秒,让kube-proxy有足够的时间改变iptables的规则。请注意readinessProbe的行为在接受到TERM信号后就变得无关紧要了。
这里有两种情况会导致请求失败:
-
Pod中的容器在接收TERM信号时立即终止,因此没有给kube-proxy足够的时间来删除转发规则
-
Keep-alive的连接无法被Kubernetes处理。例如,如果客户端使用了keep-alive连接,那这个请求依然会被路由到Pod上
Keep-alive连接默认情况下都使用了连接池。这就意味着几乎所有的在微服务之间的客户端请求都会受到Pod停止的影响。
Kubernetes的默认行为阻碍了我们从AWS/STUPS基础设施无缝迁移到Kubernetes。在STUPS中,每一个单独的容器直接运行在EC2实例上。这种情况下AWS会自动注销EC2实例,并且从ELB中将请求发送到已经停止的实例中,因此容器的优雅终止并不是必须得。因此我们正在考虑通过在基础设施层面上解决Kubernetes Pod优雅终止的问题。而这种方式可以让我们的用户(以及应用开发者)不用对应用程序做任何的修改。
有关这个主题更多信息, 您可以找到一篇关于《如何在Kubernetes中优雅通知node.js[5]》的博客以及《一个小的测试应用来观察pod的中止行为[6]》。
![]()
Pod自动扩展
Node自动扩展
我们试验的AWS自动伸缩器尝试基于AWS自动伸缩组实现一个简单的和弹性的自动伸缩能力。
优雅关闭节点在任何时候都是必须的,以降低相关的风险。我们添加了一个简单的系统单元,以便在关机时运行kubectl清理资源。
进行节点的扩展或者替换会造成应级Pod以及系统级Pod(DaemonSet)的竞争风险。我们还没有想到一个好的方法来避免在节点还没有完全就绪之前应用就被调度到该节点,仅仅依靠kubelet的就绪条件是不够的。因为它无法确保所有的系统Pod,如kube-proxy和kube2iam已经正常运行。有一个想法是在节点初始化期间使用taints来防止应用Pod在节点完全就绪之前就被调度。
![]()
我们使用了开源的ZMON监控平台来监控所有的Kubernetes集群。ZMON的Agent和Worker被部署到每一个Kubernetes集群中作为该集群的一部分。ZMON的Agent自动将AWS和Kubernetes相关的数据推送到全局的ZMON服务中。Prometheus的Node Exporter以DaemonSet的方式部署在Kubernetes的每一个节点当中。用于ZMON的Worker采集系统相关的监控指标比如磁盘空间,内存和CPU。在每一个集群中还部署了kube-state-metrics用于采集集群级别的监控数据如等待中的Pods数量等。ZMON worker还会通过访问Kubernetes的内部api地址来做一些更复杂的检测。使用ZMON的CloudWatch封装可以监控AWS相关的资源。我们还在中心ZMON定义了对集群的健康检查机制,例如:
-
已就绪的和还没有调度的节点数(通过API Server收集)
-
每个节点的磁盘,内存,CPU使用率(通过Promenteus Node Exporter和CloudWatch手机)
-
Kubernetes中每一个服务的Endpoints数量(通过API Server收集)
-
API Server请求以及延迟(通过API Server的metrics收集)
我们使用Kubernetes操作视图进行特殊的监控和问题定位。
![]()
使用Kubernetes的CronJob可以方便的来执行各种任务,例如每周更新我们SSH堡垒机。
默认情况下,Kubernetes的Job不会被清除,并且也不会删除已经完成的Pods。因此如果你频繁的运行Job(如每隔几分钟)会迅速导致API Server中大量的不必要的Pod资源而不稳定。这种情况下我们观察到API Server明显变慢。为了减轻这个问题。我们构建了一个小的kube-job-cleaner脚本每小时清理一次已经运行完成的job和pod。
![]()
我们通过专有的webhook授权访问API Server,它可以验证OAuth访问令牌,并且通过另外一个REST服务来查找用户的角色(过去由LDAP支持)。
对于etcd的访问应该受到限制,因为它拥有所有Kubernetes集群的数据,从而直接访问并对数据进行篡改。
我们使用Flannel作为我们的overlay网络,它默认需要使用etcd设置它的网络范围。这里有一个试验特性用于让Flannel的后端支持切换到Kubernetes API server。这可以限制etcd对于主节点的访问。
Kubernetes还允许定义PodSecurityPolicy用于限制使用privileged容器以及其他类似的允许权限升级的功能。
![]()
Docker通常是美好的,但有时也会带来痛苦,特别是尝试在生产环境运行可靠的容器时。我们遇到了Docker的各种问题,并且都与Kubernetes无关,例如:
-
Docker 1.11到1.12.5的版本中包含了一个致命的Bug,会导致Docker daemon不响应(docker ps挂起)。我们几乎每周都会至少有一个Kubernetes节点碰上这个问题。我们的解决办法是升级到Docke 1.13 RC2(我们现在又换回了1.12.6因为这个问题已经修复了)。
-
在使用Docker默认的json logger输出日志时,我们看到一些进程在“pipe wait”状态被卡出(根本原因现在还不秦楚)。
-
这里似乎还有很多的条件会导致Docker被挂起,你可以在Docker网站上找到很多类似的问题报告,我们已经预计这会再打击他们一次。
-
升级Docker客户端到1.13会导致无法从我们的Registry中拉去镜像(gcr.io同样出错)。我们在Pire One Registry做了一个快速解决方案,直到Docker在上游解决这个问题。
-
在Twitter上有一系列建议为Docker添加--iptables=false的参数,我们浪费了一些时间,直到我们发现这是一个坏主意。这个参数会导致Flannel的NAT网络中断。
我们了解到,由于这些微小的错误(竞争条件),会导致在生产环境中使用Docker变得非常痛苦。当你有足够多的24x7的主机运行时,或许可以降低这些问题给你带来的风险。当然在你部署完成许以后,最好不要轻易修改你的Docker版本。
![]()
Kubernetes依赖于etcd存储整个集群的状态。etcd出问题会使得Kubernetes API Server基本处于只读状态,即无法在集群中做任何的变更。丢失etcd的数据后需要重建整个集群的状态,可能导致严重的宕机问题,幸运的是只要有一个etcd节点还存在,所有的数据都是可以恢复的。
相关链接:
-
https://stups.io/
-
https://github.com/coreos/kube-aws
-
https://github.com/zalando-incubator/kubernetes-on-aws
-
https://github.com/jtblin/kube2iam
-
https://blog.risingstack.com/graceful-shutdown-node-js-kubernetes/
-
https://github.com/mikkeloscar/kube-sigterm-test
-
https://kubernetes.io/docs/user-guide/horizontal-pod-autoscaling/
原文链接:http://kubernetes-on-aws.readthedocs.io/en/latest/admin-guide/kubernetes-in-production.html
基于Kubernetes的DevOps实践培训
![]()
本次培训内容包含:Kubernetes架构、安装、深入了解Kubernetes、Kubernetes高阶——设计与实现、Kubernetes落地实践、微服务、Cloud Native等,点击识别下方二维码加微信好友了解具体培训内容。
