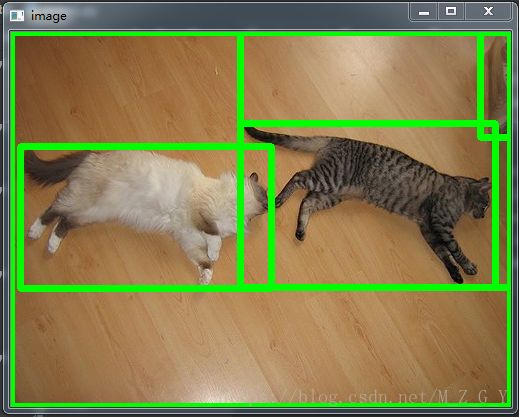
目标检测入门:候选区域选择
滑动窗口
滑动窗口检测器是一种暴力检测方法,从左到右,从上到下滑动窗口,然后利用分类识别目标。这里使用不同大小的窗口,因为一张图片可能展示从不同距离观测检测出不同的目标类型
滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
选择性搜索
思路
对于玩过Opencv人脸检测的人来说,基本都会形成一个思维定势,那就是检测就是不同大小的滑动窗进行穷举,然后使用分类器判断哪个滑动窗是人脸。对于深度学习这样超大计算量的分类器来说,这样的方法肯定是让人觉得太过于笨重的。于是乎,有人灵光一闪,说我干嘛要穷举嘛,我用简单的方法,根据颜色,纹理之类的信息去把图片划分成不同区域,哪怕是精度不高也可以相对于穷举搜索大量减少计算量。就是这么简单的搜索剪枝思路,几乎成为了当前深度学习物体识别领域的基本原则之一了。
实现细节
思路是关键,细节是必要条件。有了一个好的思路,作者在当时环境,提出来了一个相对比较好的selective search实现思路,虽然现在已经有了非常高端的技术,将selective search这个过程结合到神经网络之中,但是作者的这个实现思路也是非常值得学习,特别是如何利用已有的技术去实现自己提出的一个新的思路,不然就算哪天灵光一闪有了一个绝妙的思路,也实现不了。
待解决问题:
1)如何保证划分相对完全,有的object之间是纹理不一样,有的是颜色不一样,单一的判断标准肯定无法完全cover所有的候选区域,这样的话selective-search就没有了最基础的用处了。对应原始的穷举搜索,就是扫描这个过程,扫描就是保证能够划分完全。
2)hierarchical层次关系,划分不能简单只是划分小区域,简单思考下就能发现,object肯定存在层次关系。轮胎是object,车子也是obeject,车子包含了轮胎。桌子是,桌子上的东西也是,桌子在图像上包含了桌子上的东西。所以Selective Search也应该要能够将各个层次的object的区域都给出来。对应原始的穷举搜索,就是不同大小的搜索框,只有不同大小的搜索框才能保证不同层次的object都被选择出来。
3)速度,比起穷举搜索这样无脑的方法,selective search肯定在划分时有一定计算量的,如何保证计算量相对小,也是一个需要考虑的问题。
实现:
作者的实现思路是,首先通过简单的区域划分算法,将图片划分成很多小区域,再通过相似度和区域大小(小的区域先聚合,这样是防止大的区域不断的聚合小区域,导致层次关系不完全)不断的聚合相邻小区域,类似于聚类的思路。这样就能解决object层次问题,实际上也是非常成熟的技术。
其次,作者为了保证能够划分的完全,对于相似度,作者提出了可以多样化的思路,不但使用多样的颜色空间(RGB,Lab,HSV等等),还有很多不同的相似度计算方法。
颜色相似度:将色彩空间转为HSV,每个通道下以bins=25计算直方图,这样每个区域的颜色直方图有25*3=75个区间。
对直方图除以区域尺寸做归一化后使用下式计算相似度 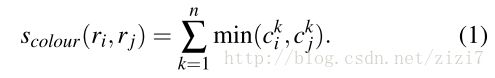
可以看到,就是简单的取每个区间最小的值累加。(可以这么理解:假设两个直方图波峰和波谷高度重合,那么计算下来的值比较大;反之如果波峰和波谷错开的,那么累加的值一定比较小。因此这里提前归一化很重要)
纹理相似度:论文采用方差为1的高斯分布在8个方向做梯度统计,然后将统计结果(尺寸与区域大小一致)以bins=10计算直方图。直方图区间数为8*3*10=240(使用RGB色彩空间)。
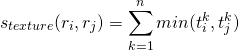
其中,![]() 是直方图中第
是直方图中第![]() 个bin的值。
个bin的值。
尺度相似度:
![]()
保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域。
例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh。
交叠相似度:
![]()

最后对于计算速度来说,只能说这个思路在相对穷举,大大减少了后期分类过程中的计算量,但是本身的计算量还是有很大的优化空间,后来很多人在这个思路上改进,得到了性能好的多的算法。
算法流程:

step0:使用Felzenszwalb生成初始化区域集R(该方法是基于图的图像分割实现的,具体参照https://blog.csdn.net/guoyunfei20/article/details/78727972)
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
输入: 一张图片
输出:候选的目标位置集合L
算法:
1: 利用切分方法得到候选的区域集合R = {r1,r2,…,rn}
2: 初始化相似集合S = ϕ
3: foreach 遍历邻居区域对(ri,rj) do
4: 计算相似度s(ri,rj)
5: S = S ∪ s(ri,rj)
6: while S not=ϕ do
7: 从S中得到最大的相似度s(ri,rj)=max(S)
8: 合并对应的区域rt = ri ∪ rj
9: 移除ri对应的所有相似度:S = S\s(ri,r*)
10: 移除rj对应的所有相似度:S = S\s(r*,rj)
11: 计算rt对应的相似度集合St
12: S = S ∪ St
13: R = R ∪ rt
14: L = R中所有区域对应的边框代码如下:
# -*- coding: utf-8 -*-
import skimage.io
import skimage.feature
import skimage.color
import skimage.transform
import skimage.util
import skimage.segmentation
import numpy
import cv2
def _generate_segments(im_orig, scale, sigma, min_size):
"""
通过Felzenswalb和Huttenlocher的算法划分最小区域
"""
# open the Image
im_mask = skimage.segmentation.felzenszwalb(
skimage.util.img_as_float(im_orig), scale=scale, sigma=sigma,
min_size=min_size)
# 将掩码通道合并为图像作为第4通道
im_orig = numpy.append(
im_orig, numpy.zeros(im_orig.shape[:2])[:, :, numpy.newaxis], axis=2)
im_orig[:, :, 3] = im_mask
return im_orig
def _sim_colour(r1, r2):
"""
计算直方图颜色交点的总和
"""
return sum([min(a, b) for a, b in zip(r1["hist_c"], r2["hist_c"])])
def _sim_texture(r1, r2):
"""
计算纹理的直方图交集的总和
"""
return sum([min(a, b) for a, b in zip(r1["hist_t"], r2["hist_t"])])
def _sim_size(r1, r2, imsize):
"""
计算图像的尺度相似度
"""
return 1.0 - (r1["size"] + r2["size"]) / imsize
def _sim_fill(r1, r2, imsize):
"""
计算图像上的填充相似度
"""
bbsize = (
(max(r1["max_x"], r2["max_x"]) - min(r1["min_x"], r2["min_x"]))
* (max(r1["max_y"], r2["max_y"]) - min(r1["min_y"], r2["min_y"]))
)
return 1.0 - (bbsize - r1["size"] - r2["size"]) / imsize
def _calc_sim(r1, r2, imsize):
return (_sim_colour(r1, r2) + _sim_texture(r1, r2)
+ _sim_size(r1, r2, imsize) + _sim_fill(r1, r2, imsize))
def _calc_colour_hist(img):
"""
计算每个区域的颜色直方图
输出直方图的大小为BINS * COLOUR_CHANNELS(3)
bins为25,与[uijlings_ijcv2013_draft.pdf]相同
提取HSV
"""
BINS = 25
hist = numpy.array([])
for colour_channel in (0, 1, 2):
# 提取一个颜色通道
c = img[:, colour_channel]
# 计算每种颜色的直方图并加入到结果中
hist = numpy.concatenate(
[hist] + [numpy.histogram(c, BINS, (0.0, 255.0))[0]])
# L1正则化
hist = hist / len(img)
return hist
def _calc_texture_gradient(img):
"""
计算整个图像的纹理渐变
最初的SelectiveSearch算法为8个方向提出了高斯导数,但我们使用LBP代替。
输出将是[height(*)] [width(*)]
"""
ret = numpy.zeros((img.shape[0], img.shape[1], img.shape[2]))
for colour_channel in (0, 1, 2):
ret[:, :, colour_channel] = skimage.feature.local_binary_pattern(
img[:, :, colour_channel], 8, 1.0)
return ret
def _calc_texture_hist(img):
"""
计算每个区域的纹理直方图
计算每种颜色的梯度直方图
输出直方图的大小为BINS * ORIENTATIONS * COLOUR_CHANNELS(3)
"""
BINS = 10
hist = numpy.array([])
for colour_channel in (0, 1, 2):
# 由颜色通道掩盖
fd = img[:, colour_channel]
# 计算每个方向的直方图并将它们连接起来并加入到结果中
hist = numpy.concatenate(
[hist] + [numpy.histogram(fd, BINS, (0.0, 1.0))[0]])
# L1正则化
hist = hist / len(img)
return hist
def _extract_regions(img):
R = {}
# rgb==>hsv
hsv = skimage.color.rgb2hsv(img[:, :, :3])
# pass 1: 计算像素位置
for y, i in enumerate(img):
for x, (r, g, b, l) in enumerate(i):
# 初始化一个新的区域
if l not in R:
R[l] = {
"min_x": 0xffff, "min_y": 0xffff,
"max_x": 0, "max_y": 0, "labels": [l]}
# 边框
if R[l]["min_x"] > x:
R[l]["min_x"] = x
if R[l]["min_y"] > y:
R[l]["min_y"] = y
if R[l]["max_x"] < x:
R[l]["max_x"] = x
if R[l]["max_y"] < y:
R[l]["max_y"] = y
# pass 2: 计算纹理梯度
tex_grad = _calc_texture_gradient(img)
# pass 3: 计算每个区域的颜色直方图
for k, v in R.items():
# 颜色直方图
masked_pixels = hsv[:, :, :][img[:, :, 3] == k]
R[k]["size"] = len(masked_pixels / 4)
R[k]["hist_c"] = _calc_colour_hist(masked_pixels)
# 纹理直方图
R[k]["hist_t"] = _calc_texture_hist(tex_grad[:, :][img[:, :, 3] == k])
return R
def _extract_neighbours(regions):
def intersect(a, b):
if (a["min_x"] < b["min_x"] < a["max_x"]
and a["min_y"] < b["min_y"] < a["max_y"]) or (
a["min_x"] < b["max_x"] < a["max_x"]
and a["min_y"] < b["max_y"] < a["max_y"]) or (
a["min_x"] < b["min_x"] < a["max_x"]
and a["min_y"] < b["max_y"] < a["max_y"]) or (
a["min_x"] < b["max_x"] < a["max_x"]
and a["min_y"] < b["min_y"] < a["max_y"]):
return True
return False
R = regions.items()
r = [elm for elm in R]
R = r
neighbours = []
for cur, a in enumerate(R[:-1]):
for b in R[cur + 1:]:
if intersect(a[1], b[1]):
neighbours.append((a, b))
return neighbours
def _merge_regions(r1, r2):
new_size = r1["size"] + r2["size"]
rt = {
"min_x": min(r1["min_x"], r2["min_x"]),
"min_y": min(r1["min_y"], r2["min_y"]),
"max_x": max(r1["max_x"], r2["max_x"]),
"max_y": max(r1["max_y"], r2["max_y"]),
"size": new_size,
"hist_c": (
r1["hist_c"] * r1["size"] + r2["hist_c"] * r2["size"]) / new_size,
"hist_t": (
r1["hist_t"] * r1["size"] + r2["hist_t"] * r2["size"]) / new_size,
"labels": r1["labels"] + r2["labels"]
}
return rt
def selective_search(im_orig, scale=1.0, sigma=0.8, min_size=50):
'''选择性搜索
参数
----------
im_orig:ndarray
输入图像
scale:int
自由参数。 更高的scale意味着felzenszwalb分段中更大的聚类。
sigma:float
felzenszwalb分割的高斯核宽度。
min_size:int
felzenszwalb分段的最小组件大小。
返回
-------
img:ndarray
带有区域标签的图像
区域标签存储在每个像素的第4个值[r,g,b,(区域)]
区域:字典数组
[
{
'rect':(左,上,右,下),
'标签': [...]
},
...
]
'''
assert im_orig.shape[2] == 3, "3ch image is expected"
# 加载图像并获得最小的区域,区域标签存储在每个像素的第4个值[r,g,b,(区域)]
img = _generate_segments(im_orig, scale, sigma, min_size)
if img is None:
return None, {}
imsize = img.shape[0] * img.shape[1]
R = _extract_regions(img)
# 提取邻居信息
neighbours = _extract_neighbours(R)
# 计算初始相似性
S = {}
for (ai, ar), (bi, br) in neighbours:
S[(ai, bi)] = _calc_sim(ar, br, imsize)
# 分层搜索
while S != {}:
# 获得最高的相似度
# i, j = sorted(S.items(), cmp=lambda a, b: cmp(a[1], b[1]))[-1][0]
i, j = sorted(list(S.items()), key=lambda a: a[1])[-1][0]
# 合并相应的地区
t = max(R.keys()) + 1.0
R[t] = _merge_regions(R[i], R[j])
# 标记要删除的区域的相似性
key_to_delete = []
for k, v in S.items():
if (i in k) or (j in k):
key_to_delete.append(k)
# 删除相关区域的旧相似性
for k in key_to_delete:
del S[k]
# 计算与新区域的相似性集
for k in filter(lambda a: a != (i, j), key_to_delete):
n = k[1] if k[0] in (i, j) else k[0]
S[(t, n)] = _calc_sim(R[t], R[n], imsize)
regions = []
for k, r in R.items():
regions.append({
'rect': (
r['min_x'], r['min_y'],
r['max_x'] - r['min_x'], r['max_y'] - r['min_y']),
'size': r['size'],
'labels': r['labels']
})
return img, regions
if __name__ == '__main__':
image = cv2.imread('F:/_photo/photo/temp/000019.jpg')
img, regions = selective_search(image, scale=1000, sigma=0.9, min_size=1000)
print(len(regions))
for r in regions:
x, y, w, h = r['rect']
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0),5)
cv2.imshow('image', image)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()