week5:模块之json、pickle、dump和load方法、shelve、xml
一、什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化。在python中叫picking。
序列化之后,就可以把序列化的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化。即unpicking
二、json模块
如果要在不同的语言之间传递对象,需要把对象序列化为标准格式。json表示出来就是一个字符串,可以被所有的语言读取,也可以方便的存储到磁盘或者通过网络传输。XML
json表示的对象就是就是标准的javascript语言的对象。json和python内置的数据类型对应如下:
import json
dic = {'name': 'alex', 'age': '18'}
data = json.dumps(dic)
f = open('JSON_text', 'w')
f.write(data)
f.close()输出结果:{"age": "18", "name": "alex"}import json
f = open('JSON_text', 'r')
data = f.read()
data = json.loads(data)
print(data['name'])输出结果:name
三、pickle模块
json支持字典,列表,但不支持函数和类。而pickle支持更多的类型(如函数和类),可以序列化一个函数
import pickle
def foo():
print('ok')
data = pickle.dumps(foo)
f = open('PICKLE_text', 'wb')#写成BYTES类型
f.write(data)
f.close()输出结果:

import pickle
f = open('PICKLE_text', 'rb')
data = f.read()
data = pickle.loads(data)
data()
###########################
Traceback (most recent call last):
File "C:/Users/asus/PycharmProjects/fullstack/week4/day2/bin.py", line 82, in
data = pickle.loads(data)
AttributeError: Can't get attribute 'foo' on
没有输出结果,改进如下:
import pickle
def foo():
print('ok')
f = open('PICKLE_text', 'rb')
data = f.read()
data = pickle.loads(data)
data() ###ok四、dump load方法
dump:
import json
dic = {'name': 'alex', 'age': '18'}
f = open('JSON_text', 'w')
json.dump(dic,f) ## data = json.dumps(dic) f.write(data)
f.close()load:
import json
f = open('JSON_text', 'r')
#data = f.read()
#data = json.loads(data)
data = json.load(f)
print(data['name'])五、shelve模块(***)
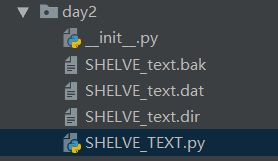
shelve模块比pickle模块简单,只有一个open函数,可读可写。key必须为字符串,而值可以是python所支持的数据类型。
import shelve
f = shelve.open('SHELVE_text')
f['info'] = {'name': 'alex', 'age': '18'}以以下3种方式进行存储,然后进行取出
import shelve
f = shelve.open('SHELVE_text')
#
# f['info'] = {'name': 'alex', 'age': '18'}
data = f.get('info')
print(data)输出结果:{'age': '18', 'name': 'alex'}
r在正则表达式里 是为了保持原生字符串
字典补充:
d = {'name': 'alex', 'age': '18'}
print(d.get('name')) #alex
print(d.get('sex')) ##None
print(d.get('sex', 'male')) ##male
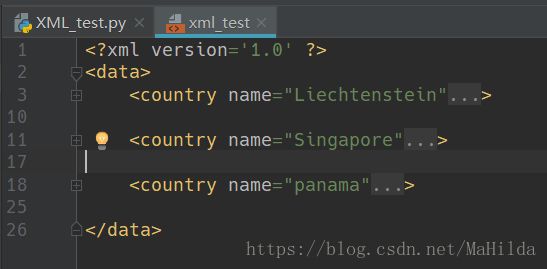
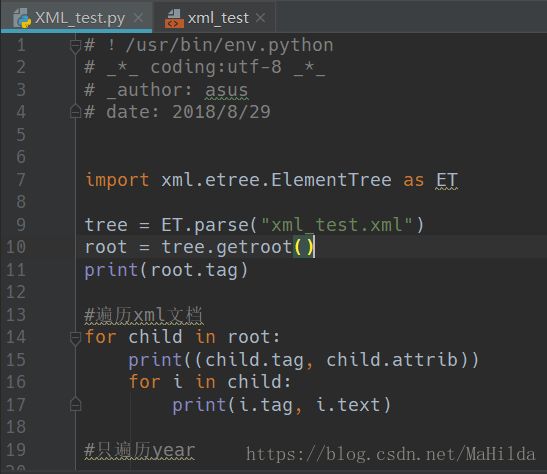
六、XML模块(**)