MT-DNN解读(论文 + PyTorch源码)
前一段时间,看到微软发布了用于学习通用语言嵌入的多任务深度神经网络模型MT-DNN,可谓是紧随BERT之后,结合他们之前的MTL工作以及BERT的优势,在10项NLU任务上的表现都超过了BERT。
PS:预感到BERT的起飞又将给NLP领域带来新一波论文热潮(把之前的东西加上BERT再train一遍?效果飞起?发论文!当然这里没有任何diss这个MT-DNN模型的意思哈哈,毕竟也得底子好是吧,不然真废柴加上BERT也没用~)
文章目录
- 一. 前言
- 二. MT-DNN原理
- 1. 多任务介绍
- 2. 模型结构
- 3. 训练流程
- 三. 实验
- 1. 数据集
- 2. 实验结果
- 3. 对比实验
- 四. PyTorch实现
- 1. pretrain
- 2. finetune
- 五. 总结
- 优势
- 不足
- 传送门
一. 前言
预训练(加源头)和多任务学习(加目标)都是能用来提升效果的手段。
预训练近期的进展,如BERT、GPT等,大家都有目共睹,就不多说了~
对于MTL(Multi-task Learning,多任务学习)来说,其优点有两个:1)弥补了有些任务的数据不足问题;2)有正则的作用,防止模型过拟合。
论文中作者认为,MTL和pretrain有很好的互补作用,那么是不是可以结合一下,发挥两者的作用。更具体的就是,先用BERT进行pretrain,然后用MTL进行finetune,这就形成了MT-DNN。可见,与BERT的不同在于finetune的过程,这里用MTL作为目标。
换个角度来想,其实是在BERT没有出来的时候,是直接训练MTL的模型,现在BERT出来了,那就拿这个初始化试试?
二. MT-DNN原理
1. 多任务介绍
在讲MT-DNN之前,先来唠一唠有哪些任务?因为毕竟是Multi-Task的学习,总要知道Task是哪些吧!
MT-DNN是结合了4种类型的NLU任务:单句分类、句子对分类、文本相似度打分和相关度排序。下面举一些GLUE中的例子:
- 单句分类:比如CoLA是判断这句话是否语法合适、SST-2是判断这句话的情感
- 文本相似度:比如STS-B是为两句话进行相似度打分
- 句子对分类:比如RTE和MNLI是文本蕴含任务,QQP和MRPC是判断两句话是否语义上一致
- 相关性排序:比如QNLI,它其实在原始的GLUE任务中定义为二分类问题,但这里论文给它定义成排序问题,自己采样了一堆负样本,然后用softmax学习排序
2. 模型结构
看下面这个图:

其实很直观,下面的shared layers是BERT,上面的task specific layers是MTL。BERT的部分就不多说了,还不了解的读者戳笔者之前的博客。这里主要讲一下用于适配各个任务的MTL部分。
- 单句的分类任务
用[CLS]的表征作为特征,设为 x x x,则对于单句的分类任务,直接在后面接入一个分类层即可,以SST-2任务为例:
P r ( c ∣ X ) = s o f t m a x ( W S S T T ⋅ x ) P_r(c|X) = softmax(W_{SST}^T · x) Pr(c∣X)=softmax(WSSTT⋅x)
loss就是分类的交叉熵,即:
− ∑ c I ( X , c ) l o g ( P r ( c ∣ X ) ) -\sum_c I(X, c) log (P_r(c|X)) −c∑I(X,c)log(Pr(c∣X))
- 句子相似度
以STS-B任务为例,将两句话pack后送进去,得到的[CLS]的表征,可拿出来计算分数:
S i m ( X 1 , X 2 ) = s i g m o i d ( w S T S T ⋅ x ) Sim(X_1, X_2) = sigmoid(w_{STS}^T · x) Sim(X1,X2)=sigmoid(wSTST⋅x)
loss采用MSE损失,即:
( y − S i m ( X 1 , X 2 ) ) 2 (y - Sim(X_1, X_2))^2 (y−Sim(X1,X2))2
- 句子对分类
以NLI任务为例,这里接的是SAN网络,一个在这个任务上表现得比较好的网络。
SAN的计算流程为:
- 输入premise P = ( p 1 , . . . , p m ) P = (p_1,...,p_m) P=(p1,...,pm) 和 hypothesis H = ( h 1 , . . . , h n ) H = (h_1,...,h_n) H=(h1,...,hn)
- 通过BERT得到premise和hypothesis的表示, M p = R d ∗ m M^p = \R ^ {d * m} Mp=Rd∗m和 M h = R d ∗ n M^h = \R ^ {d * n} Mh=Rd∗n
- 开始K步的推理,初始状态 s 0 s^0 s0是 M h M^h Mh的self-attention, s 0 = ∑ j α j M j h s^0 = \sum_j \alpha_j M_j^h s0=∑jαjMjh,这里的 α j = e x p ( w 1 T ⋅ M j h ) ∑ i e x p ( w 1 T ⋅ M i h ) \alpha_j = \frac{exp(w_1^T · M_j^h)}{\sum_i exp(w_1^T · M_i^h)} αj=∑iexp(w1T⋅Mih)exp(w1T⋅Mjh),然后对于第k步,状态变化为 s k = G R U ( s k − 1 , x k ) s^k = GRU(s^{k-1}, x^k) sk=GRU(sk−1,xk),这里的 x k x^k xk计算方式为 x k = ∑ j β j M j p , β j = s o f t m a x ( s k − 1 W 2 T M p ) x^k = \sum_j \beta_j M_j^p, \beta_j = softmax(s^{k-1}W_2^TM^p) xk=∑jβjMjp,βj=softmax(sk−1W2TMp)
- 最后接一层分类层,用于捕捉每一步的推理结果: P r k = s o f t m a x ( W 3 T [ s k ; x k ; ∣ s k − x k ∣ ; s k ⋅ x k ] ) P_r^k = softmax(W_3^T[s^k; x^k; |s^k - x^k|; s^k · x^k]) Prk=softmax(W3T[sk;xk;∣sk−xk∣;sk⋅xk])
- 最后分数是所有推理结果的平均: P r = a v g ( [ P r 0 , P r 1 , . . . , P r K − 1 ] ) P_r = avg([P_r^0, P_r^1, ..., P_r^{K-1}]) Pr=avg([Pr0,Pr1,...,PrK−1])
loss仍采用分类的交叉熵,即:
− ∑ c I ( X , c ) l o g ( P r ( c ∣ X ) ) -\sum_c I(X, c) log (P_r(c|X)) −c∑I(X,c)log(Pr(c∣X))
- 相关性排序
以QNLI为例,这里主要是先计算两个句子之间的相似度,输入两个句子pack,采用[CLS]的输出作为表征。
R e l ( Q , A ) = g ( w Q N L I T ⋅ x ) Rel(Q, A) = g(w_{QNLI}^T · x) Rel(Q,A)=g(wQNLIT⋅x)
loss采用排序损失:
− ∑ Q , A + P r ( A + ∣ Q ) - \sum_{Q, A^+} P_r(A^+ | Q) −Q,A+∑Pr(A+∣Q)
P r ( A + ∣ Q ) = e x p ( γ R e l ( Q , A + ) ) ∑ A ′ ∈ A e x p ( γ R e l ( Q , A ′ ) ) P_r(A^+|Q) = \frac{exp(\gamma Rel(Q, A^+))}{\sum_{A' \in A} exp(\gamma Rel(Q, A'))} Pr(A+∣Q)=∑A′∈Aexp(γRel(Q,A′))exp(γRel(Q,A+))
3. 训练流程
见下图:

这里的Eq.6~Eq.8,读者就对应到前面相应任务的loss公式即可。
三. 实验
1. 数据集
评估的数据集还是很多的,与BERT论文重合的也比较多,详细信息见下表:

这里除了WNLI、SNLI和SciTail,都是BERT里面评估的GLUE数据集。
2. 实验结果
在GLUE上面的表现如下:(这里应该是用了9个GLUE任务进行的MTL?)

这里的MT-DNN使用的是BERT_LARGE作为base model。
在SNLI和SciTail上的表现如下:(这里应该是用了这11个任务进行的MTL?)

PS:感觉论文里面并没有说清楚,在做各个实验的时候,是用了哪些任务进行MTL,上面是笔者根据蛛丝马迹猜测的,若有大神看到了,还烦请解答~
3. 对比实验
首先是对比了使用MTL的作用:

这里的ST-DNN是用BERT_BASE作为预训练,然后单独finetune各个任务的结果,但在某些任务(如MNLI、QQP和MRPC)上使用了SAN,与BERT那么简单的finetune模型不一样。
然后是对比了一些domain adaption的结果,主要还是SNLI和SciTail这两个数据集,首先在8个GLUE任务上进行finetune(没有用WNLI,为了防止与这两个数据集有重合任务),然后再用各自的数据进行finetune,最后评估的效果如下:
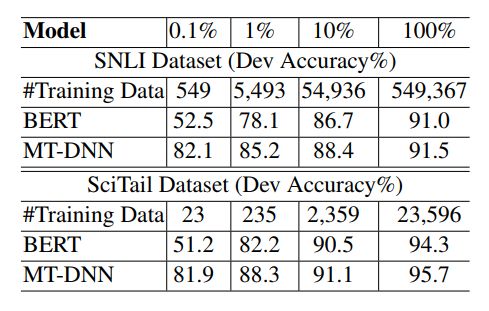
这里不是ZSL的设定,只是域适应,所以是在预训练的时候没有用到目标域的数据,但finetune的时候,是允许用目标域数据进行finetune的。
作者还列举出了在进行域适应的时候,不同的模型需要的数据量的比较:

四. PyTorch实现
看了MT-DNN的源码,也是较为详细的。包括MT-DNN的pretrain,以及一些任务的finetune,同时也提供了pretrain好的模型。下面将分为pretrain和finetune两部分来剖析:
1. pretrain
首先来看MT-DNN模型的构建:(这里只列举了核心的代码)
class SANBertNetwork(nn.Module):
def __init__(self, opt, bert_config=None):
super(SANBertNetwork, self).__init__()
self.bert_config = BertConfig.from_dict(opt)
self.bert = BertModel(self.bert_config)
mem_size = self.bert_config.hidden_size
self.decoder_opt = opt['answer_opt']
self.scoring_list = nn.ModuleList()
labels = [int(ls) for ls in opt['label_size'].split(',')]
for task, lab in enumerate(labels):
decoder_opt = self.decoder_opt[task]
if decoder_opt == 1:
out_proj = SANClassifier(mem_size, mem_size, lab, opt, prefix='answer', dropout=dropout)
self.scoring_list.append(out_proj)
else:
out_proj = nn.Linear(self.bert_config.hidden_size, lab)
self.scoring_list.append(out_proj)
def forward(self, input_ids, token_type_ids, attention_mask, premise_mask=None, hyp_mask=None, task_id=0):
all_encoder_layers, pooled_output = self.bert(input_ids, token_type_ids, attention_mask)
sequence_output = all_encoder_layers[-1]
decoder_opt = self.decoder_opt[task_id]
if decoder_opt == 1:
max_query = hyp_mask.size(1)
assert max_query > 0
assert premise_mask is not None
assert hyp_mask is not None
hyp_mem = sequence_output[:,:max_query,:]
logits = self.scoring_list[task_id](sequence_output, hyp_mem, premise_mask, hyp_mask)
else:
pooled_output = self.dropout_list[task_id](pooled_output)
logits = self.scoring_list[task_id](pooled_output)
return logits
可见,是首先用了BERT的结构作为底层的encoder,然后在上面接task-specific的结构,这里的labels表示类别数,decoder_opt表示是否使用SAN网络。
PS:这里发现一个在PyTorch中调用BERT的方法,huggingface的pytorch-pretrained-bert居然是可以直接pip安装使用的,也太方便了吧,而且还有gpt,gpt2和transformer-xl!感谢神人~
下面是SAN网络的实现:
class SANClassifier(nn.Module):
"""Implementation of Stochastic Answer Networks for Natural Language Inference, Xiaodong Liu, Kevin Duh and Jianfeng Gao
https://arxiv.org/abs/1804.07888
"""
def __init__(self, x_size, h_size, label_size, opt={}, prefix='decoder', dropout=None):
super(SANClassifier, self).__init__()
if dropout is None:
self.dropout = DropoutWrapper(opt.get('{}_dropout_p'.format(self.prefix), 0))
else:
self.dropout = dropout
self.prefix = prefix
self.query_wsum = SelfAttnWrapper(x_size, prefix='mem_cum', opt=opt, dropout=self.dropout)
self.attn = FlatSimilarityWrapper(x_size, h_size, prefix, opt, self.dropout)
self.rnn_type = '{}{}'.format(opt.get('{}_rnn_type'.format(prefix), 'gru').upper(), 'Cell')
self.rnn =getattr(nn, self.rnn_type)(x_size, h_size)
self.num_turn = opt.get('{}_num_turn'.format(prefix), 5)
self.opt = opt
self.mem_random_drop = opt.get('{}_mem_drop_p'.format(prefix), 0)
self.mem_type = opt.get('{}_mem_type'.format(prefix), 0)
self.weight_norm_on = opt.get('{}_weight_norm_on'.format(prefix), False)
self.label_size = label_size
self.dump_state = opt.get('dump_state_on', False)
self.alpha = Parameter(torch.zeros(1, 1), requires_grad=False)
if self.weight_norm_on:
self.rnn = WN(self.rnn)
self.classifier = Classifier(x_size, self.label_size, opt, prefix=prefix, dropout=self.dropout)
def forward(self, x, h0, x_mask=None, h_mask=None):
h0 = self.query_wsum(h0, h_mask)
if type(self.rnn) is nn.LSTMCell:
c0 = Variable(h0.new(h0.size()).zero_())
scores_list = []
for turn in range(self.num_turn):
att_scores = self.attn(x, h0, x_mask)
x_sum = torch.bmm(F.softmax(att_scores, 1).unsqueeze(1), x).squeeze(1)
scores = self.classifier(x_sum, h0)
scores_list.append(scores)
# next turn
if self.rnn is not None:
h0 = self.dropout(h0)
if type(self.rnn) is nn.LSTMCell:
h0, c0 = self.rnn(x_sum, (h0, c0))
else:
h0 = self.rnn(x_sum, h0)
if self.mem_type == 1:
mask = generate_mask(self.alpha.data.new(x.size(0), self.num_turn), self.mem_random_drop, self.training)
mask = [m.contiguous() for m in torch.unbind(mask, 1)]
tmp_scores_list = [mask[idx].view(x.size(0), 1).expand_as(inp) * F.softmax(inp, 1) for idx, inp in enumerate(scores_list)]
scores = torch.stack(tmp_scores_list, 2)
scores = torch.mean(scores, 2)
scores = torch.log(scores)
else:
scores = scores_list[-1]
if self.dump_state:
return scores, scores_list
else:
return scores
与论文中列举的公式一致。
接下来看loss的构建:
logits = self.mnetwork(*inputs)
if batch_meta['pairwise']:
logits = logits.view(-1, batch_meta['pairwise_size'])
if task_type > 0:
loss = F.mse_loss(logits.squeeze(), y)
else:
loss = F.cross_entropy(logits, y)
这里是用到了两种loss,实际上论文中是有三种loss,这里是将分类的交叉熵loss和rank-loss都实现为多分类的交叉熵。
总结起来看,源码中一共是用mnli,rte,qqp,qnli,mrpc,sst,cola和stsb这8个任务进行MTL,其中mnli,rte,qqp,mrpc都是输入为pair的分类任务,它们用的是SAN网络+交叉熵损失的形式;qnli是输入为pair的rank任务,它用的也是SAN网络+交叉熵损失的形式,但需要对输出做一个变换,才能将rank_loss转为交叉熵的形式;stsb是输入为pair的分数预测(回归)任务,它用的是普通的Linear映射+mse损失的形式;sst,cola是输入为single的分类任务,它用的也是普通的Linear映射+交叉熵损失的形式。
同时,在MT-DNN的预训练过程中,是每次先根据各个任务中的数据量分布对任务进行采样,而后取那个任务的一个batch数据出来进行训练。
2. finetune
finetune的部分就是用各自任务的数据,对应各自任务上已经训好的MT-DNN模型进行微调即可,模型和损失等和前面的pretrain一样,这里就不再赘述。
整体来看,流程就是:
- 先用BERT预训练好的模型做一个大的打底
- 然后在上面接各种任务自己的task-model,并进行多任务的训练,得到MT-DNN
- 最后再分别利用各个任务的数据,在前面得到的MT-DNN上进行finetune,得到最终的结果(如果不是用的类似之前多任务的数据进行finetune的话,就可以看做是域适应了)
五. 总结
优势
- 同时结合了BERT和MTL的思想,两者互补,效果确实好!
- 整个流程都十分的清晰,没有特别难以理解的地方
- 方便扩展,可以用更多的task,进行MTL
- 源码、预训练模型都比较充足
不足
- 有堆砌的感觉,,虽然确实非常有用
- 在做实验的时候,其实对标BERT有些不公平,因为BERT就是在单纯的凸显它的预训练模型效果,在接入下游任务的时候,基本没有加太多额外的参数,而MT-DNN在接入下游任务的时候,不管是从模型结构还是目标函数上,都有做相应的优化,虽然也有对比实验,但还是感觉整体思路不那么clean。而且后面大家随便接入一个更好的下游模型,提升了效果,是不是就可以又发一篇论文?(一些浅见而已,不要太当真。。)
传送门
论文:https://arxiv.org/pdf/1901.11504.pdf
源码:https://github.com/namisan/mt-dnn
博客:https://mp.weixin.qq.com/s?__biz=MzAwMTA3MzM4Nw==&mid=2649447160&idx=2&sn=db35c6a7b2c5e7c45fb09a137adf6b17&chksm=82c0b37cb5b73a6a1f57fee2c281c299799508b803b49e5350828c2a203a14157dc6815445c6&mpshare=1&scene=1&srcid=#rd