XLM解读(论文 + PyTorch源码)
这篇论文是Facebook在BERT的基础上发展出来的Cross-Lingual版本,即多语的。BERT的github上实际上也有一个多语版本的,但却没有提到是怎么训练的,也没有任何的信息。这里的XLM提出了一些策略用于多语言学习,并与multi-lingual的BERT进行了对比,效果确实会好。
文章目录
- 一. 前言
- 二. XLM原理
- 1. 多语词表构建
- 2. 预训练任务
- 3. 预训练流程
- 三. 实验
- 四. PyTorch实现
- 五. 总结
- 优势
- 不足
- 传送门
一. 前言
一开始BERT出来的时候,只有英语的,这对于各个国家的广大AI爱好者,是十分不便的,大家都希望能有自己国家语言的版本。这不,后面BERT又出了多语言版本,FB也紧跟着出了一个更好的多语言版本(不过貌似语言比较少?主要还是针对翻译和XNLI任务而定制的,不像BERT的那个那么多语言,而且很通用)
这里复述一下作者在第一章总结的他们的贡献:
- 引入了一个新的无监督方法,用于训练多语的表征,并且提出两个单语的预训练LM目标
- 提出了一种新的有监督方法,使用平行语料,来增强多语预训练的表现
- 在跨语言分类、有/无监督机器翻译任务上,达到了新的SoTA
- 对于resource比较少的语言,用这种预训练方式很有帮助
- 重点来了!有源码和预训练模型
下面来看看XLM具体是怎么操作的~
PS:不知道有没有读者和笔者一样,一看到这种多语的啊,pair的啊,parallel的啊这类的词眼,就觉得整个逻辑非常的晕,这篇论文,尤其是实验部分,真的是结合源码看了好久,大概率是笔者太菜了吧。。。
二. XLM原理
1. 多语词表构建
既然是多语的模型嘛,总不可能是一个语言一个model,然后封装在一起,假装是多语模型吧,肯定是只有一个模型的,那么就要求这个模型能接收各个语言的句子作为输入,因此这里就需要构建包含各个语言词的多语词表。
与BERT一样,这里也是使用BPE,但不是简单地把各个语言的bpe词表进行拼接,那样也太大了,,这里是先对多语语料按照如下的概率进行采样,然后将多语语料进行拼接,最后进行正常的BPE统计。采样的目的是对大语种的语料和小语种的语料进行一下平滑,省的全采到大语种上面了,小语种连词表都没有了(或者小语种都被按照char拆分了)。。这里取 α = 0.5 \alpha=0.5 α=0.5。
q i = p i α ∑ j = 1 N p j α w i t h p i = n i ∑ k = 1 N n k q_i = \frac{p_i^ \alpha}{\sum_{j=1}^N p_j^ \alpha}\ with\ p_i = \frac{n_i}{\sum_{k=1}^N n_k} qi=∑j=1Npjαpiα with pi=∑k=1Nnkni
2. 预训练任务
这里作者提出了三种预训练任务:CLM、MLM和TLM,下面分别介绍:
- CLM:Causal Language Model,无监督单语单向LM训练任务,就是用Transformer进行LM的单向训练。
- MLM:Masked Language Model,无监督单语双向LM训练任务,与BERT一样。
- TLM:Translation Language Model,有监督翻译LM训练,拼接平行双语语料,然后执行MLM,以期这样能学到翻译的对齐信息?
对于MLM和TLM的形象化表示可以看下图:

这里MLM/TLM的输入构造时与BERT的不同主要在于:
- BERT在预训练构造输入的时候,用的都是pair的输入方式,其实就是先构建NSP的数据,然后再mask并构造MLM的数据。输入会规定一个最大长度,然后选择两个句子组(句子组的概念就是把物理上相邻的多个句子当成一整个句子,中间不加入任何句子的分隔符),满足在这个长度内即可。
- XLM在预训练的时候,对于CLM和MLM都是用的stream的方式,将多个物理上的句子(不一定相邻?)通过分隔符连接起来作为输入,对于TLM的构造与前者一样,只不过又拼接了一个平行语料。同时,去掉了BERT里面的句子id标识,改成了语言的id标识。
3. 预训练流程
简而言之就是:CLM/MLM (+TLM),也即从CLM或MLM中选一个进行单语LM的预训练,然后再根据需求和数据情况,决定要不要加入TLM进行训练,加入的话就是和前面的CLM/MLM进行交替训练。
三. 实验
论文里面主要验证了XNLI、无监督机器翻译和有监督机器翻译任务的效果,下面分别说:
- XNLI
这个任务其实笔者也是去扒拉了FB之前的论文,才知道是个什么任务。。其实还是文本蕴含任务,但只不过训练集里面都是英文的,验证集里面是多语的(15种语言,获取方法就是把英文的验证集翻译过来,同一个pair里面是同一种语言的)。
先用MLM在各个语言的单语语料上进行训练(也有加上额外的平行语料进行TLM训练的部分),然后再用英文训练集进行finetune,最后在多个语种上评估。结果如下:
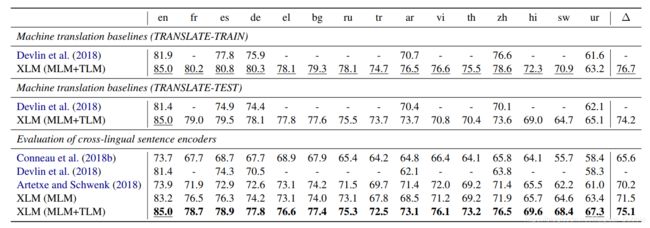
- 无监督MT
无监督MT的任务,笔者也是特意去查阅了相关的资料,知道大概是怎么回事。用大白话说就是,给出两个语言各自的语料(不一定要平行),机器应该就能学会翻译,就像人类一样,在学会了中文和英语之后,应该能进行翻译,因为中间的连接是语义,而不是词表的对应。
无监督MT就是基于这么一个设定,一般在不考虑pretrain的时候,用的比较多的方法是用去噪自编码器+循环翻译,具体来说,对于英译德这个任务,搭建起encoder-decoder这个模型之后,可以用英文语料加上噪声,输入encoder,然后decoder出来原始的英文语料,同理也可以用德文语料加上噪声,输入encoder,然后decoder出来原始的德文语料,这个就叫去噪自编码器,目的其实是在于让encoder学到语义信息;循环翻译是个啥?比如en->de->en,就是先让英文经过encoder和decoder,得到翻译的德文伪数据,然后将这个德文伪数据,再输入encoer和decoder,得到原来的英文数据,这样进行训练。
那么在这里,其实就是用CLM或MLM去初始化encoder和decoder,decoder就初始化那些encoder有的部分,然后后面用上面的套路进行正常流程的训练即可,这里对比不同的初始化方法的结果:

- 有监督MT
这里对比了几种方法用不同的预训练方式,结果如下:
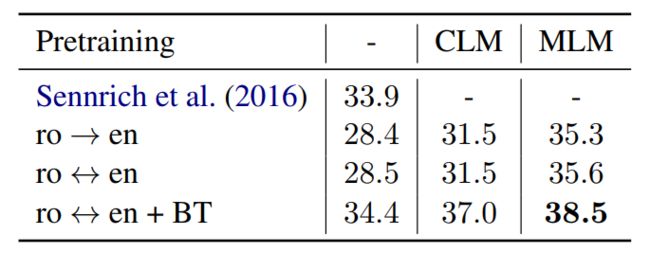
- Sennich:这个是之前的SoTA,好像还是用了back-translation+ensemble的方法,也是一个强baseline
- ro->en:这个是用单向的数据进行finetune
- ro<->en:这个使用双向的数据进行finetune
- ro<->en + BT:用双向的数据进行finetune,同时进行back-translation(这个好像又是那种先从A->B生成B的伪数据,然后再翻译回到A)
- 小语种LM
这里主要是验证多语训练对小语种语言模型建模的影响,结果如下:

- 无监督多语embedding
这里主要是验证无监督情况下生成的多语embedding的优秀程度,通过验证各种源单词和其翻译对应的词之间的距离,结果如下:

四. PyTorch实现
这里主要是分析XLM源码中关于模型和训练的部分,因笔者对于论文中的这些任务(如翻译等)不是特别熟悉,所以全凭README的内容和代码一步一步摸索,如果有理解错误的地方,还请指正~
下面我将按照源码中README给出的思路顺序进行剖析:
- 有/无监督机器翻译
在机器翻译这个场景下,论文首先用CLM/MLM对MT的encoder和decoder进行预训练。其实这里就是用的多种语言的单语语料,输入词表是多语的,然后用CLM/MLM训练语言模型,并将其参数作为后续MT的encoder和decoder的初始参数,对decoder的初始化是只初始化其中与encoder相同的部分,即不初始化encoder-decoder-attention的部分。感觉这样也是一种思路啊,一般都认为decoder是没法初始化的,这里却可以这样初始化??
其预训练的代码如下:
model = build_model(params, data['dico'])
# CLM steps
for lang1, lang2 in shuf_order(params.clm_steps, params):
trainer.clm_step(lang1, lang2, params.lambda_clm)
# MLM steps (also includes TLM if lang2 is not None)
for lang1, lang2 in shuf_order(params.mlm_steps, params):
trainer.mlm_step(lang1, lang2, params.lambda_mlm)
这里首先就是定义模型,其实就是Transformer的encoder,这里就不再赘述。紧接着是有两种训练方式,一种是CLM,一种是MLM,分别与论文里面是对应的。
下面来看clm_step和mlm_step各自的实现:
def clm_step(self, lang1, lang2, lambda_coeff):
"""
Next word prediction step (causal prediction).
CLM objective.
"""
# generate batch / select words to predict
x, lengths, positions, langs, _ = self.generate_batch(lang1, lang2, 'causal')
x, lengths, positions, langs, _ = self.round_batch(x, lengths, positions, langs)
alen = torch.arange(lengths.max(), dtype=torch.long, device=lengths.device)
pred_mask = alen[:, None] < lengths[None] - 1
y = x[1:].masked_select(pred_mask[:-1])
# forward / loss
tensor = model('fwd', x=x, lengths=lengths, langs=langs, causal=True)
_, loss = model('predict', tensor=tensor, pred_mask=pred_mask, y=y, get_scores=False)
def mlm_step(self, lang1, lang2, lambda_coeff):
"""
Masked word prediction step.
MLM objective is lang2 is None, TLM objective otherwise.
"""
# generate batch / select words to predict
x, lengths, positions, langs, _ = self.generate_batch(lang1, lang2, 'pred')
x, lengths, positions, langs, _ = self.round_batch(x, lengths, positions, langs)
x, y, pred_mask = self.mask_out(x, lengths)
# forward / loss
tensor = model('fwd', x=x, lengths=lengths, positions=positions, langs=langs, causal=False)
_, loss = model('predict', tensor=tensor, pred_mask=pred_mask, y=y, get_scores=False)
仔细看这两者的实现,其实只在generate batch上不同,CLM只需要生成正常的序列即可,而MLM则需要进行mask_out的操作,这里与BERT一致,也不再赘述。
在预训练完Encoder和Decoder之后,就开始用task-specific的方法进行finetune,比如对于无监督机器翻译来说,就是用去噪自编码器+循环翻译的方式,比如对于en-fr这种翻译,去噪自编码器就是noise_en->en和noise_fr->fr,循环翻译就是en->fr->en和fr->en->fr;对于有监督机器翻译来说,目前较好的方式就是比如对于en->fr,就是同时学习en->fr和fr->en(是用同一个MT模型学习en->fr和fr->en?),而后用en->fr的数据为fr->en进行数据增广(back-translation,不知道理解是否有误?)以及fr->en的数据为en->fr进行数据增广,这样来进行finetune。
这里源码里面分别给出了这些方法的训练方式:
# denoising auto-encoder steps
for lang in shuf_order(params.ae_steps):
trainer.mt_step(lang, lang, params.lambda_ae)
# machine translation steps
for lang1, lang2 in shuf_order(params.mt_steps, params):
trainer.mt_step(lang1, lang2, params.lambda_mt)
# back-translation steps
for lang1, lang2, lang3 in shuf_order(params.bt_steps):
trainer.bt_step(lang1, lang2, lang3, params.lambda_bt)
其中的mt_step是翻译训练,可以是A->B的翻译,也可以是noise_A->A的翻译;bt_step是back-translation训练,主要是A->B->A的这种训练。其实现方式如下:
def mt_step(self, lang1, lang2, lambda_coeff):
"""
Machine translation step.
Can also be used for denoising auto-encoding.
"""
# generate batch
if lang1 == lang2:
(x1, len1) = self.get_batch('ae', lang1)
(x2, len2) = (x1, len1)
(x1, len1) = self.add_noise(x1, len1)
else:
(x1, len1), (x2, len2) = self.get_batch('mt', lang1, lang2)
langs1 = x1.clone().fill_(lang1_id)
langs2 = x2.clone().fill_(lang2_id)
# target words to predict
alen = torch.arange(len2.max(), dtype=torch.long, device=len2.device)
pred_mask = alen[:, None] < len2[None] - 1 # do not predict anything given the last target word
y = x2[1:].masked_select(pred_mask[:-1])
# encode source sentence
enc1 = self.encoder('fwd', x=x1, lengths=len1, langs=langs1, causal=False)
enc1 = enc1.transpose(0, 1)
# decode target sentence
dec2 = self.decoder('fwd', x=x2, lengths=len2, langs=langs2, causal=True, src_enc=enc1, src_len=len1)
# loss
_, loss = self.decoder('predict', tensor=dec2, pred_mask=pred_mask, y=y, get_scores=False)
def bt_step(self, lang1, lang2, lang3, lambda_coeff):
"""
Back-translation step for machine translation.
"""
# generate source batch
x1, len1 = self.get_batch('bt', lang1)
langs1 = x1.clone().fill_(lang1_id)
# generate a translation
with torch.no_grad():
# evaluation mode
self.encoder.eval()
self.decoder.eval()
# encode source sentence and translate it
enc1 = _encoder('fwd', x=x1, lengths=len1, langs=langs1, causal=False)
enc1 = enc1.transpose(0, 1)
x2, len2 = _decoder.generate(enc1, len1, lang2_id, max_len=int(1.3 * len1.max().item() + 5))
langs2 = x2.clone().fill_(lang2_id)
# free CUDA memory
del enc1
# training mode
self.encoder.train()
self.decoder.train()
# encode generate sentence
enc2 = self.encoder('fwd', x=x2, lengths=len2, langs=langs2, causal=False)
enc2 = enc2.transpose(0, 1)
# words to predict
alen = torch.arange(len1.max(), dtype=torch.long, device=len1.device)
pred_mask = alen[:, None] < len1[None] - 1 # do not predict anything given the last target word
y1 = x1[1:].masked_select(pred_mask[:-1])
# decode original sentence
dec3 = self.decoder('fwd', x=x1, lengths=len1, langs=langs1, causal=True, src_enc=enc2, src_len=len2)
# loss
_, loss = self.decoder('predict', tensor=dec3, pred_mask=pred_mask, y=y1, get_scores=False)
代码还是比较清晰的,对于mt_step,就是直接调用encoder和decoder进行正常的MT训练;而对于bt_step,则首先在eval模式下离线生成A->B’,而后再进行B’->A的正常MT训练。
- XNLI分类任务
这部分是多语言的分类任务,这里主要看不用翻译系统的方法,即先用MLM+TLM和多语言的单语语料及平行语料进行encoder的预训练,而后用纯英文的语料进行finetune。
预训练的部分和前面那个MT任务中的预训练一样,都是使用mlm_step这个函数,只不过在构建语料的时候,加上了使用平行语料进行mask的部分。
在finetune部分,是在顶层加入了一层Linear,用于三分类;而后将输入的两个句子进行拼接,进入分类层,代码如下:
self.proj = nn.Sequential(*[
nn.Dropout(params.dropout),
nn.Linear(self.embedder.out_dim, 3)
]).cuda()
(sent1, len1), (sent2, len2), idx = batch
sent1, len1 = truncate(sent1, len1, params.max_len, params.eos_index)
sent2, len2 = truncate(sent2, len2, params.max_len, params.eos_index)
x, lengths, positions, langs = concat_batches(
sent1, len1, lang_id,
sent2, len2, lang_id,
params.pad_index,
params.eos_index,
reset_positions=False
)
y = self.data['en']['train']['y'][idx]
# loss
output = self.proj(self.embedder.get_embeddings(x, lengths, positions, langs))
loss = F.cross_entropy(output, y)
五. 总结
优势
- 提供了多语预训练的思路,并且确实效果很好
- 几个预训练任务的设计和训练,都非常巧妙
- 对小语种的训练很有帮助,并且可以提供无监督的多语embedding
- 提供了源码和所有预训练模型
不足
- 语言比较少,而且基本都是针对下游任务的,是否不太通用?
- 论文整体思路比较不够clean,而且对于特定任务的介绍不够充分,导致理解起来比较困难(至少对于笔者这样的小白来说很困难~),有些需要看代码甚至要查阅资料才能知道如何处理的
传送门
论文:https://arxiv.org/pdf/1901.07291.pdf
源码:https://github.com/facebookresearch/XLM
博客:https://www.lyrn.ai/2019/02/11/xlm-cross-lingual-language-model/