借助Python爬虫批量下载数据——以NASA和NOAA科研数据为例
1. 无需登录的页面,下载文件:
下载: NOAA-CIRES 20th Century 2m气温再分析资料
但是资料实在的太多了,一个个点手会点残,这时候可以借助Python来批量化下载数据。
打开页面,按F12查看网页源码。
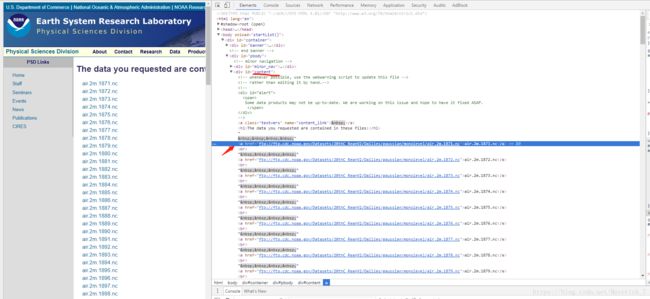
可以看出,对应下载文件的链接都在div标签下的a标签中,需要将这些链接一一获取然后就可以进行批量化下载了。
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib
from bs4 import BeautifulSoup
rawurl='https://www.esrl.noaa.gov/psd/cgi-bin/db_search/DBListFiles.pl?did=118&tid=40290&vid=2227'
content = urllib.request.urlopen(rawurl).read().decode('ascii') #获取页面的HTML
soup = BeautifulSoup(content, 'lxml')
url_cand_html=soup.find_all(id='content') #定位到存放url的标号为content的div标签
list_urls=url_cand_html[0].find_all("a") #定位到a标签,其中存放着文件的url
urls=[]
for i in list_urls[1:]:
urls.append(i.get('href')) #取出链接
for i,url in enumerate(urls):
print("This is file"+str(i+1)+" downloading! You still have "+str(142-i-1)+" files waiting for downloading!!")
file_name = "C:/Users/QIZHANG/Desktop/QKY/ncfile/"+url.split('/')[-1] #文件保存位置+文件名
urllib.request.urlretrieve(url, file_name)2. 需要登录的页面,下载文件:
对于下载需要登录页面的资料,比如:NASA海冰资料
需要在请求文件时加入登录信息,最简单的就是借助Cookie。百度百科对于Cookie的定义是:指某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密)。
1. 输入账号密码登录,按F12审查元素:
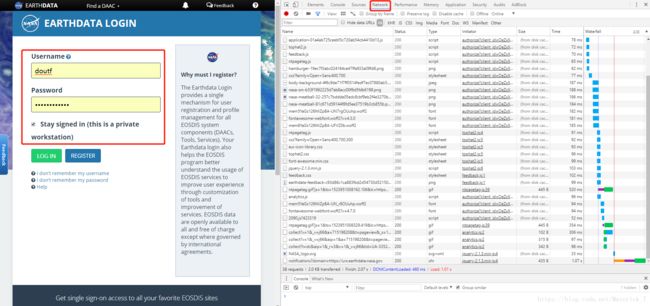
2. 登录后,在network里找到’Cookie’和’User-Agent’标签:

#!/usr/bin/env python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
#加入Cookie和User-Agent信息
Cookieinfo = "_ga=GA1.2.323787597.1522234147; _ceg.s=p6ci10; _ceg.u=p6ci10; nsidc=a3f9ef85-39ca-425d-bf96-ea1c3f3d0461"
User = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
headers = {'Cookie': Cookieinfo,
'User-Agent': User
}
rawurl = "https://daacdata.apps.nsidc.org/pub/DATASETS/nsidc0081_nrt_nasateam_seaice/south/"
resp = requests.get(rawurl, headers=headers).text
soup = BeautifulSoup(resp, 'lxml')
link = soup.find_all('a')[6:-216] # 类似于前面介绍的方法,获取文件的url
link_dup = []
for i in link:
a = i.get('href')
link_dup.append(a)
link_all = list(set(link_dup)) #列表重复了一遍,可以用set进行去重,再重新排序
link_all.sort(key=link_dup.index)
crawler_url = []
for i in link_all:
a = rawurl + i
crawler_url.append(a)
for i, url in enumerate(crawler_url):
r = requests.get(url, headers=headers)
with open(file_name, "wb") as code:
code.write(r.content)