报告 | 腾讯知文,从0到1打造下一代智能问答引擎【CCF-GAIR】

图片来源于雷锋网
雷锋网:
关于自然语言处理NLP和自然语言理解NLU研究到底到了哪一阶段?还有哪些亟待突破的技术难点?接下来又将产生哪些服务于大众的应用? CCF-GAIR 2018 大会NLP 专场给出了指点。我们希望未来将会这样:搜索引擎更加精准,机器翻译更为实用,聊天机器人更能懂你,机器客服更加高效,自然语言处理在金融、法律、教育、医疗等行业,将迎来更加广泛的应用。
2018年7月1日上午自然语言处理专场中腾讯知文算法负责人钟黎就NLP、NLU、dialogue等面临的问题,做了其“从0到1打造下一代智能问答引擎”的报告。
钟黎:腾讯知文算法负责人,高级研究员,目前负责知文智能问答、智能搜索、知识图谱、内容理解等技术研发和产品落地。他拥有丰富的大规模机器学习应用经验,曾参与研发类人机器人NAO、Watson智能会议助理等产品,并主导了腾讯SNG海量社交网络话题发现和大规模语义分析平台的研发工作。(引自雷锋网的描述)
因包含的信息量较大,在此与大家分享一下当时印象比较深的点,以及小编现场拍摄的资料。
腾讯知文智能对话引擎的架构图如下。分为三层,由下而上依次为:general conversation是基础会话,主要包括用户闲聊、情感联系和用户个人信息等;information & answers是本次会议主要讨论分享的模块,包括智能搜索、单轮会话(single-turn mostly)和所需的会话模型;第三层是任务导向型的对话,包括词槽填充、多轮会话和对话管理(Dialog Management,DM)。

腾讯知文智能对话引擎架构
由于支持的问答来源不同,故而问答引擎中包含了涉及的问答来源的问答引擎。首先是communityQA,用来解决FAQ(常见问题问答集)的query;KBQA是基于知识库的问答,需要提前构建好知识库(比如,三元组的);TableQA是基于结构化数据的问答,从表中查询问题和答案;passageQA是基于非结构化文本的问答,里面涉及到文本分析、知识抽取、自然语言处理、自然语言理解的功能,试图从文本/文档中获取query的答案;VQA是基于视频/图像的问答,答案来源于视频或图像。

支持的不同数据源的QA
一-基于结构化的FAQ的问答引擎流程
由两条技术路线来解决,一种是无监督学习,基于快速检索;另一种是有监督的学习,基于深度匹配。

结构化FAQ问答引擎流程
1.1 无监督的快速检索方法
采用了三个层次的方法来实现快速检索的方法。
首先用了基础的TFIDF提取query的关键词,用BM25来计算query和FAQ库中问题的相似度。这是典型的词汇统计的方法,该方法可以对rare word比较鲁棒,但同时也存在词汇匹配缺失的问题。
其次,采用了language model(简写LM)的方法,主要使用的是Jelinek-Mercer平滑法和Dirichlet平滑法,对于上面的词汇匹配问题表现良好,但是也存在平滑敏感的问题。
最后一层使用Embedding,采用了LSA/word2vec和腾讯知文自己提出的Weighted Sum/WMD方法,以此来表示语义层面的近似,但是也同样引发了歧义问题。

无监督的快速检索方法

基于TF-IDF的词统计

LM计算Query与Document匹配流程
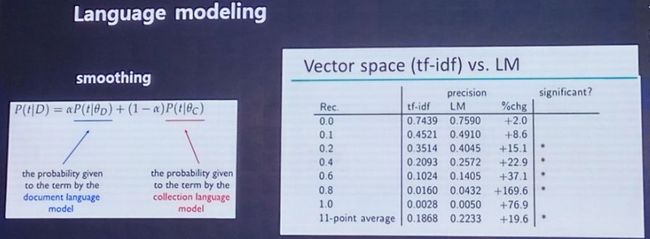
LM与tf-idf对于平滑效果的准确率对比
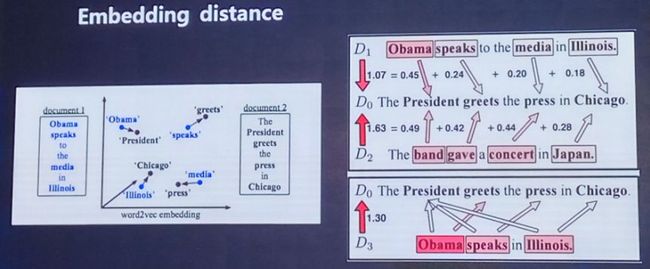
word2vec embedding计算相似举例

Embedding distance错误率
1.2 监督的深度匹配方法
智能问答引擎的第二种方法是深度匹配的监督学习方法或者称其为监督的深度匹配方法。采用了两条思路,一条是基于Siamese networks神经网络架构,这是一种相似性度量方法,内部采用深度语义匹配模型(DSMM,Deep Structured Semantic Model),该方法在检索场景下使用点击数据来训练语义层次的匹配。另一条思路是Interaction-based networks,同时对问题和答案进行特征加权的Attention方案。

深度匹配的监督学习方法
Siamese networks:通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
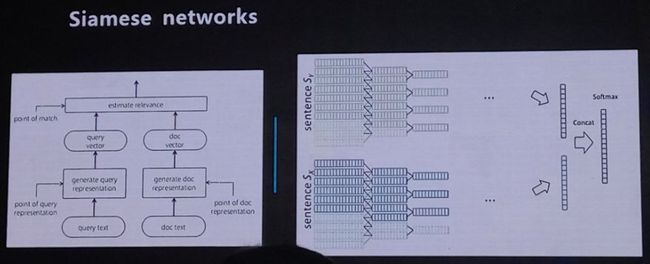 基于DSSM的Siamese networks
基于DSSM的Siamese networks

基于Attention机制的Interaction-based networks

attentive Pooling Networks
二-基于非结构化文档的智能问答引擎
非结构化文档的智能问答离不开机器阅读理解,而机器阅读理解目前常见的无外乎:
(1)cloze-style类似完形填空的;
(2)multiple-choice类似多项选择的;
(3)answer-matching类似文档中答案匹配的。
像PPT中给出的示例,询问某类“实体”,答案来源是一段文本,分析问句,从文本段落中找到答案。

机器阅读理解的类型
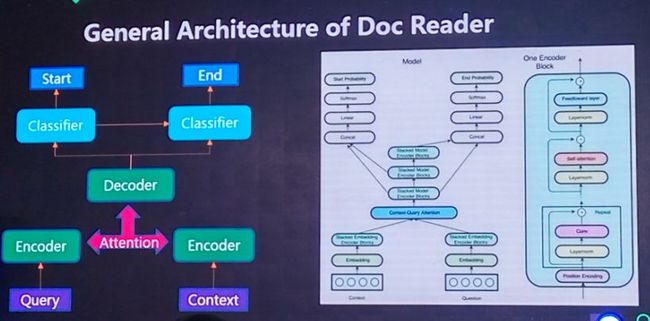
以下两张PPT给出了如何结合query从文档中获取答案的流程,及采用end-end的方式解码文档理解文档。这个在会议上未理解清楚,后续还需要查找腾讯知文开放的相关论文或文档来理解。
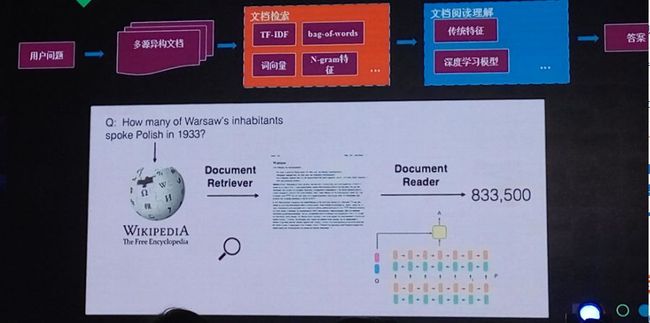
从文档中获取query答案的流程
三-总结
下面是钟黎研究员在智能问答引擎过程中总结的几点注意事项:
1、Baseline needs more love
哈,个人通俗理解,是说在做智能问答/对话的过程中不要总想着用高大上的算法,也要考虑关键词、词袋等一些基础方法,也许这些方法很简单但是可以解决很多看似困难的问题。请多给这些基础功能一些爱~~
2、Starting from pipelines
因为智能问答/对话涉及的模块或策略比较多,根据产品规划或者应用落地,会不断的丰富其功能及提升其准确率,为了方便扩展,在问答系统开发的初期就一定要考虑好怎样合理设计pipeline。其实这个问题在小编工作过程中也碰到了~~
3、No free lunch theorem
字面意思“没有免费的午餐”,个人理解的是指对话语料整理收集方面,还是需要做一些基础工作滴~
4、Domain-specific data is the key
领域的专有数据是关键,因为对话的场景还是要解决实际业务问题的,所以不管是在问答数据准备上还是在模型训练上,最好都要丰富一部分业务专有数据。

以上,便是小编在此次会议中的收获,当然因为时间和小编脑容量有限,可能有些点没有提到或者提到的点未必准确,还请各位童鞋批评指正,共同探讨进步!在此,也非常感谢CCF-GAIR大会提供的学习交流机会!
