操作系统ucore lab8实验报告
练习0
填写已有实验
本实验依赖实验1~实验7.请把已做的实验1~实验7的代码填入本实验中代码中有lab1、lab2、lab3、lab4、lab5、lab6、lab7的注释相应部分,并确保编译通过。
注意:为了能够正确执行lab8的测试应用程序,可能需对已完成的实验1~实验7的代码进一步改进
用meld软件,将已完成的lab7和lab8进行对比,大致截图如下:

需要修改的文件罗列如下:
kdebug.c、proc.c、default_pmm.c、pmm.c、swap_fifo.c、vmm.c、trap.c、sche.c、monitor.c、check_sync.c十个文件的相关代码,无需进行其他的修改。
练习1
完成读文件操作的实现(需要编码)
首先了解打开文件的处理流程,然后参考本实验后续的文件读写操作的过程分析,编写在sfs_inode.c中sfs_io_nolock读文件中数据的实现代码。
原理
ucore模仿了UNIX的文件系统设计,ucore的文件系统架构主要由四部分组成:
- 通用文件系统访问接口层
该层提供了一个从用户空间到文件系统的标准访问接口。这一层访问接口让应用程序能够通过一个简单的接口获得ucore内核的文件系统服务。
- 文件系统抽象层
向上提供一个一致的接口给内核其他部分(文件系统相关的系统调用实现模块和其他内核功能模块)访问。向下提供一个抽象函数指针列表和数据结构来屏蔽不同文件系统的实现细节。
- Simple FS文件系统层
一个基于索引方式的简单文件系统实例。向上通过各种具体函数实现以对应文件系统抽象层提出的抽象函数。向下访问外设接口
- 外设接口层
向上提供device访问接口屏蔽不同硬件细节。向下实现访问各种具体设备驱动的接口,比如disk设备接口/串口设备接口/键盘设备接口等。
四个部分的关系

打开文件原理:
先简单分析下一些重要的数据结构
首先是file数据结构:
struct file {
enum {
FD_NONE, FD_INIT, FD_OPENED, FD_CLOSED,
} status; //访问文件的执行状态
bool readable; //文件是否可读
bool writable; //文件是否可写
int fd; //文件在filemap中的索引值
off_t pos; //访问文件的当前位置
struct inode *node;//该文件对应的内存inode指针
atomic_t open_count;//打开此文件的次数
};接下来inode数据结构,它是位于内存的索引节点,把不同文件系统的特定索引节点信息(甚至不能算是一个索引节点)统一封装起来,避免了进程直接访问具体文件系统
struct inode {
union { //包含不同文件系统特定inode信息的union域
struct device __device_info; //设备文件系统内存inode信息
struct sfs_inode __sfs_inode_info; //SFS文件系统内存inode信息
} in_info;
enum {
inode_type_device_info = 0x1234,
inode_type_sfs_inode_info,
} in_type; //此inode所属文件系统类型
atomic_t ref_count; //此inode的引用计数
atomic_t open_count; //打开此inode对应文件的个数
struct fs *in_fs; //抽象的文件系统,包含访问文件系统的函数指针
const struct inode_ops *in_ops; //抽象的inode操作,包含访问inode的函数指针
}; 首先假定用户进程需要打开的文件已经存在在硬盘上。以user/sfs_filetest1.c为例,首先用户进程会调用在main函数中的如下语句:
int fd1 = safe_open("/test/testfile", O_RDWR | O_TRUNC); 从字面上可以看出,如果ucore能够正常查找到这个文件,就会返回一个代表文件的文件描述符fd1,这样在接下来的读写文件过程中,就直接用这样fd1来代表就可以了。
例如某一个应用程序需要操作文件(增删读写等),首先需要通过文件系统的通用文件系统访问接口层给用户空间提供的访问接口进入文件系统内部,接着由文件系统抽象层把访问请求转发给某一具体文件系统(比如Simple FS文件系统),然后再由具体文件系统把应用程序的访问请求转化为对磁盘上的block的处理请求,并通过外设接口层交给磁盘驱动例程来完成具体的磁盘操作。
- 通用文件访问接口层的处理流程
首先进入通用文件访问接口层的处理流程,即进一步调用如下用户态函数: open->sys_open->syscall,从而引起系统调用进入到内核态。到了内核态后,通过中断处理例程,会调用到sys_open内核函数,并进一步调用sysfile_open内核函数。到了这里,需要把位于用户空间的字符串”/test/testfile”拷贝到内核空间中的字符串path中,并进入到文件系统抽象层的处理流程完成进一步的打开文件操作中。 - 文件系统抽象层的处理流程
- 分配一个空闲的file数据结构变量file在文件系统抽象层的处理中,首先调用的是
file_open函数,它要给这个即将打开的文件分配一个file数据结构的变量,这个变量其实是当前进程的打开文件数组current->fs_struct->filemap[]中的一个空闲元素(即还没用于一个打开的文件),而这个元素的索引值就是最终要返回到用户进程并赋值给变量fd1。到了这一步还仅仅是给当前用户进程分配了一个file数据结构的变量,还没有找到对应的文件索引节点。
为此需要进一步调用vfs_open函数来找到path指出的文件所对应的基于inode数据结构的VFS索引节点node。vfs_open函数需要完成两件事情:通过vfs_lookup找到path对应文件的inode;调用vop_open函数打开文件。 - 找到文件设备的根目录
/的索引节点需要注意,这里的vfs_lookup函数是一个针对目录的操作函数,它会调用vop_lookup函数来找到SFS文件系统中的/test目录下的testfile文件。为此,vfs_lookup函数首先调用get_device函数,并进一步调用vfs_get_bootfs函数(其实调用了)来找到根目录/对应的inode。这个inode就是位于vfs.c中的inode变量bootfs_node。这个变量在init_main函数(位于kern/process/proc.c)执行时获得了赋值。 - 找到根目录
/下的test子目录对应的索引节点,在找到根目录对应的inode后,通过调用vop_lookup函数来查找/和test这两层目录下的文件testfile所对应的索引节点,如果找到就返回此索引节点。 - 把file和node建立联系。完成第3步后,将返回到
file_open函数中,通过执行语句file->node=node;,就把当前进程的current->fs_struct->filemap[fd](即file所指变量)的成员变量node指针指向了代表/test/testfile文件的索引节点node。这时返回fd。经过重重回退,通过系统调用返回,用户态的syscall->sys_open->open->safe_open等用户函数的层层函数返回,最终把把fd赋值给fd1。自此完成了打开文件操作。但这里我们还没有分析第2和第3步是如何进一步调用SFS文件系统提供的函数找位于SFS文件系统上的/test/testfile所对应的sfs磁盘inode的过程。下面需要进一步对此进行分析。
- 分配一个空闲的file数据结构变量file在文件系统抽象层的处理中,首先调用的是
- SFS文件系统层的处理流程
这里需要分析文件系统抽象层中没有彻底分析的vop_lookup函数到底做了啥。下面我们来看看。在sfs_inode.c中的sfs_node_dirops变量定义了.vop_lookup = sfs_lookup,所以我们重点分析sfs_lookup的实现。
static int sfs_lookup(struct inode *node, char *path, struct inode **node_store) {
struct sfs_fs *sfs = fsop_info(vop_fs(node), sfs);
assert(*path != '\0' && *path != '/'); //以“/”为分割符,从左至右逐一分解path获得各个子目录和最终文件对应的inode节点。
vop_ref_inc(node);
struct sfs_inode *sin = vop_info(node, sfs_inode);
if (sin->din->type != SFS_TYPE_DIR) {
vop_ref_dec(node);
return -E_NOTDIR;
}
struct inode *subnode;
int ret = sfs_lookup_once(sfs, sin, path, &subnode, NULL); //循环进一步调用sfs_lookup_once查找以“test”子目录下的文件“testfile1”所对应的inode节点。
vop_ref_dec(node);
if (ret != 0) {
return ret;
}
*node_store = subnode; //当无法分解path后,就意味着找到了需要对应的inode节点,就可顺利返回了。
return 0;
} sfs_lookup有三个参数:node,path,node_store。其中node是根目录/所对应的inode节点;path是文件testfile的绝对路径/test/testfile,而node_store是经过查找获得的testfile所对应的inode节点。
Sfs_lookup函数以/为分割符,从左至右逐一分解path获得各个子目录和最终文件对应的inode节点。在本例中是分解出test子目录,并调用sfs_lookup_once函数获得test子目录对应的inode节点subnode,然后循环进一步调用sfs_lookup_once查找以test子目录下的文件testfile1所对应的inode节点。当无法分解path后,就意味着找到了testfile1对应的inode节点,就可顺利返回了。
sfs_lookup_once将调用sfs_dirent_search_nolock函数来查找与路径名匹配的目录项,如果找到目录项,则根据目录项中记录的inode所处的数据块索引值找到路径名对应的SFS磁盘inode,并读入SFS磁盘inode对的内容,创建SFS内存inode。
static int sfs_lookup_once(struct sfs_fs *sfs, struct sfs_inode *sin, const char *name, struct inode **node_store, int *slot) {
int ret;
uint32_t ino;
lock_sin(sin);
{ // find the NO. of disk block and logical index of file entry
ret = sfs_dirent_search_nolock(sfs, sin, name, &ino, slot, NULL);
}
unlock_sin(sin);
if (ret == 0) {
// load the content of inode with the the NO. of disk block
ret = sfs_load_inode(sfs, node_store, ino);
}
return ret;
}sfs_io_nolock函数
/*
* sfs_io_nolock - Rd/Wr a file contentfrom offset position to offset+ length disk blocks<-->buffer (in memroy)
* @sfs: sfs file system
* @sin: sfs inode in memory
* @buf: the buffer Rd/Wr
* @offset: the offset of file
* @alenp: the length need to read (is a pointer). and will RETURN the really Rd/Wr lenght
* @write: BOOL, 0 read, 1 write
*/
static int
sfs_io_nolock(struct sfs_fs *sfs, struct sfs_inode *sin, void *buf, off_t offset, size_t *alenp, bool write) {
struct sfs_disk_inode *din = sin->din;
assert(din->type != SFS_TYPE_DIR);
off_t endpos = offset + *alenp, blkoff;
*alenp = 0;
// calculate the Rd/Wr end position
if (offset < 0 || offset >= SFS_MAX_FILE_SIZE || offset > endpos) {
return -E_INVAL;
}
if (offset == endpos) {
return 0;
}
if (endpos > SFS_MAX_FILE_SIZE) {
endpos = SFS_MAX_FILE_SIZE;
}
if (!write) {
if (offset >= din->size) {
return 0;
}
if (endpos > din->size) {
endpos = din->size;
}
}
int (*sfs_buf_op)(struct sfs_fs *sfs, void *buf, size_t len, uint32_t blkno, off_t offset);
int (*sfs_block_op)(struct sfs_fs *sfs, void *buf, uint32_t blkno, uint32_t nblks);
if (write) {
sfs_buf_op = sfs_wbuf, sfs_block_op = sfs_wblock;
}
else {
sfs_buf_op = sfs_rbuf, sfs_block_op = sfs_rblock;
}
int ret = 0;
size_t size, alen = 0;
uint32_t ino;
uint32_t blkno = offset / SFS_BLKSIZE; // The NO. of Rd/Wr begin block
uint32_t nblks = endpos / SFS_BLKSIZE - blkno; // The size of Rd/Wr blocks
//LAB8:EXERCISE1 YOUR CODE HINT: call sfs_bmap_load_nolock, sfs_rbuf, sfs_rblock,etc. read different kind of blocks in file
/*
* (1) If offset isn't aligned with the first block, Rd/Wr some content from offset to the end of the first block
* NOTICE: useful function: sfs_bmap_load_nolock, sfs_buf_op
* Rd/Wr size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset)
* (2) Rd/Wr aligned blocks
* NOTICE: useful function: sfs_bmap_load_nolock, sfs_block_op
* (3) If end position isn't aligned with the last block, Rd/Wr some content from begin to the (endpos % SFS_BLKSIZE) of the last block
* NOTICE: useful function: sfs_bmap_load_nolock, sfs_buf_op
*/
if ((blkoff = offset % SFS_BLKSIZE) != 0)
{//读取第一部分的数据
//计算第一个数据块的大小
size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset);
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0)
{//先找到内存文件索引对应的block的编号ino
goto out;
}
if ((ret = sfs_buf_op(sfs, buf, size, ino, blkoff)) != 0)
{
goto out;
}
//完成实际的读写操作
alen += size;
if (nblks == 0)
{
goto out;
}
buf += size, blkno ++, nblks --;
}
//读取中间部分的数据,分解成size大小,一块一块的读直至读完
size = SFS_BLKSIZE;
while (nblks != 0)
{
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0)
{
goto out;
}
if ((ret = sfs_block_op(sfs, buf, ino, 1)) != 0)
{
goto out;
}
alen += size, buf += size, blkno ++, nblks --;
}
//读取第三部分的数据
if ((size = endpos % SFS_BLKSIZE) != 0)
{
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0)
{
goto out;
}
if ((ret = sfs_buf_op(sfs, buf, size, ino, 0)) != 0)
{
goto out;
}
alen += size;
}
out:
*alenp = alen;
if (offset + alen > sin->din->size) {
sin->din->size = offset + alen;
sin->dirty = 1;
}
return ret;
}练习2
完成基于文件系统的执行程序机制的实现(需要编码)
改写proc.c中的 load_icode 函数和其他相关函数,实现基于文件系统的执行程序机制。执行:make qemu。如果能看看到sh用户程序的执行界面,则基本成功了。如果在sh用户界面上可以执行”ls”,”hello”等其他放置在sfs文件系统中的其他执行程序,则可以认为本实验基本成功。
alloc_proc
初始化fs中的进程控制结构
static struct proc_struct * alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
proc->state = PROC_UNINIT;
proc->pid = -1;
proc->runs = 0;
proc->kstack = 0;
proc->need_resched = 0;
proc->parent = NULL;
proc->mm = NULL;
memset(&(proc->context), 0, sizeof(struct context));
proc->tf = NULL;
proc->cr3 = boot_cr3;
proc->flags = 0;
memset(proc->name, 0, PROC_NAME_LEN);
proc->wait_state = 0;
proc->cptr = proc->optr = proc->yptr = NULL;
proc->rq = NULL;
proc->run_link.prev = proc->run_link.next = NULL;
proc->time_slice = 0;
proc->lab6_run_pool.left = proc->lab6_run_pool.right = proc->lab6_run_pool.parent = NULL;
proc->lab6_stride = 0;
proc->lab6_priority = 0;
proc->filesp = NULL; //初始化fs中的进程控制结构
}
return proc;
} load_icode
static int
load_icode(int fd, int argc, char **kargv) {
/* LAB8:EXERCISE2 YOUR CODE HINT:how to load the file with handler fd in to process's memory? how to setup argc/argv?
* MACROs or Functions:
* mm_create - create a mm
* setup_pgdir - setup pgdir in mm
* load_icode_read - read raw data content of program file
* mm_map - build new vma
* pgdir_alloc_page - allocate new memory for TEXT/DATA/BSS/stack parts
* lcr3 - update Page Directory Addr Register -- CR3
*/
/* (1) create a new mm for current process
* (2) create a new PDT, and mm->pgdir= kernel virtual addr of PDT
* (3) copy TEXT/DATA/BSS parts in binary to memory space of process
* (3.1) read raw data content in file and resolve elfhdr
* (3.2) read raw data content in file and resolve proghdr based on info in elfhdr
* (3.3) call mm_map to build vma related to TEXT/DATA
* (3.4) callpgdir_alloc_page to allocate page for TEXT/DATA, read contents in file
* and copy them into the new allocated pages
* (3.5) callpgdir_alloc_page to allocate pages for BSS, memset zero in these pages
* (4) call mm_map to setup user stack, and put parameters into user stack
* (5) setup current process's mm, cr3, reset pgidr (using lcr3 MARCO)
* (6) setup uargc and uargv in user stacks
* (7) setup trapframe for user environment
* (8) if up steps failed, you should cleanup the env.
*/
assert(argc >= 0 && argc <= EXEC_MAX_ARG_NUM);
//1.建立内存管理器
if (current->mm != NULL)
{//要求当前内存管理器为空
panic("load_icode: current->mm must be empty.\n");
}
int ret = -E_NO_MEM;//表示因为存储设备产生的请求错误
struct mm_struct *mm;//建立内存管理器
if ((mm = mm_create()) == NULL)
{
goto bad_mm;
}
//2.建立页目录表
if (setup_pgdir(mm) != 0)
{
goto bad_pgdir_cleanup_mm;
}
struct Page *page;
//3.从文件加载程序到内存
struct elfhdr __elf, *elf = &__elf;
if ((ret = load_icode_read(fd, elf, sizeof(struct elfhdr), 0)) != 0)
{//读取elf文件头
goto bad_elf_cleanup_pgdir;
}
if (elf->e_magic != ELF_MAGIC) {
ret = -E_INVAL_ELF;
goto bad_elf_cleanup_pgdir;
}
struct proghdr __ph, *ph = &__ph;
uint32_t vm_flags, perm, phnum;
for (phnum = 0; phnum < elf->e_phnum; phnum ++)
{//e_phnum代表程序段入口地址数目,即段数
off_t phoff = elf->e_phoff + sizeof(struct proghdr) * phnum;
//循环读取程序的每个段的头部
if ((ret = load_icode_read(fd, ph, sizeof(struct proghdr), phoff)) != 0)
{
goto bad_cleanup_mmap;
}
if (ph->p_type != ELF_PT_LOAD)
{
continue ;
}
if (ph->p_filesz > ph->p_memsz)
{
ret = -E_INVAL_ELF;
goto bad_cleanup_mmap;
}
if (ph->p_filesz == 0)
{
continue ;
}
//建立虚拟地址与物理地址之间的映射
vm_flags = 0, perm = PTE_U;
if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC;
if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE;
if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ;
if (vm_flags & VM_WRITE) perm |= PTE_W;
if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0)
{
goto bad_cleanup_mmap;
}
off_t offset = ph->p_offset;
size_t off, size;
uintptr_t start = ph->p_va, end, la = ROUNDDOWN(start, PGSIZE);
ret = -E_NO_MEM;
//复制数据段和代码段
end = ph->p_va + ph->p_filesz;//计算数据段和代码段的终止地址
while (start < end)
{
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL)
{
ret = -E_NO_MEM;
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la)
{
size -= la - end;
}
//每次读取size大小的块,直至读完
if ((ret = load_icode_read(fd, page2kva(page) + off, size, offset)) != 0)
{
goto bad_cleanup_mmap;
}
start += size, offset += size;
}
//建立BSS段
end = ph->p_va + ph->p_memsz;
if (start < la)
{
/* ph->p_memsz == ph->p_filesz */
if (start == end)
{
continue ;
}
off = start + PGSIZE - la, size = PGSIZE - off;
if (end < la)
{
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
assert((end < la && start == end) || (end >= la && start == la));
}
while (start < end)
{
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL)
{
ret = -E_NO_MEM;
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la)
{
size -= la - end;
}
//每次操作size大小的块
memset(page2kva(page) + off, 0, size);
start += size;
}
}
//关闭文件,加载程序结束
sysfile_close(fd);
//4.建立相应的虚拟内存映射表
vm_flags = VM_READ | VM_WRITE | VM_STACK;
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0)
{
goto bad_cleanup_mmap;
}
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-4*PGSIZE , PTE_USER) != NULL);
//5.设置好用户栈
mm_count_inc(mm);
current->mm = mm;
current->cr3 = PADDR(mm->pgdir);
lcr3(PADDR(mm->pgdir));
//处理用户栈中传入的参数
//setup argc, argv
uint32_t argv_size=0, i;
for (i = 0; i < argc; i ++)
{
argv_size += strnlen(kargv[i],EXEC_MAX_ARG_LEN + 1)+1;
}
uintptr_t stacktop = USTACKTOP - (argv_size/sizeof(long)+1)*sizeof(long);
char** uargv=(char **)(stacktop - argc * sizeof(char *));
argv_size = 0;
for (i = 0; i < argc; i ++)
{//将所有的参数取出防止uargv
uargv[i] = strcpy((char *)(stacktop + argv_size ), kargv[i]);
argv_size += strnlen(kargv[i],EXEC_MAX_ARG_LEN + 1)+1;
}
stacktop = (uintptr_t)uargv - sizeof(int);
*(int *)stacktop = argc;
//7.设置进程的中断帧
struct trapframe *tf = current->tf;
memset(tf, 0, sizeof(struct trapframe));
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = stacktop;
tf->tf_eip = elf->e_entry;
tf->tf_eflags = FL_IF;
ret = 0;
//8.错误处理
out:
return ret;
bad_cleanup_mmap:
exit_mmap(mm);
bad_elf_cleanup_pgdir:
put_pgdir(mm);
bad_pgdir_cleanup_mm:
mm_destroy(mm);
bad_mm:
goto out;
} load_icode主要是将文件加载到内存中执行,根据注释的提示分为了一共七个步骤:
- 建立内存管理器
- 建立页目录表
- 从硬盘上读取程序内容到内存,这里要注意设置虚拟地址与物理地址之间的映射
- 建立相应的虚拟内存映射表
- 建立并初始化用户堆栈
- 处理用户栈中传入的参数
- 设置用户进程的中断帧
- 错误处理
实验结果
运行make qemu,之后我们执行一下ls、hello命令如下图:
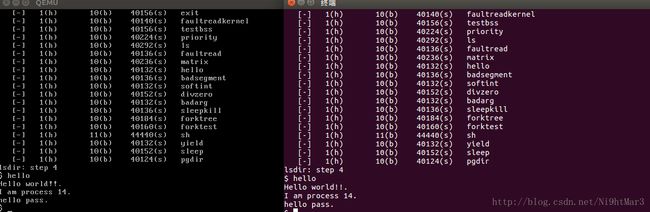
说明实验成功
实验收获
通过本次实验,基本了解了文件系统的系统调用的实现方法,对ucore文件系统的总体架构设计也有了一个大体上的认识,学习了打开文件的处理流程即一个读文件的操作。不足在于针对文件系统的权限设置以及相应的操作还比较模糊,理解不够深刻。