Task05---循环和递归神经网络
为什么需要RNN(循环神经网络)
参考:https://zhuanlan.zhihu.com/p/30844905
神经网络只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
以nlp的一个最简单词性标注任务来说,将我 吃 苹果 三个单词标注词性为 我/nn 吃/v 苹果/nn。
那么这个任务的输入就是:我 吃 苹果 (已经分词好的句子)
这个任务的输出是:
我/nn 吃/v 苹果/nn(词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,但是普通的神经网络的数据输入格式:
我-> 我/nn (单独的单词->词性标注好的单词)
吃->吃/v
苹果->苹果/nn
但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
RNN的结构
转自:https://zhuanlan.zhihu.com/p/30844905

x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈);
s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同)
U是输入层到隐藏层的权重矩阵,
o也是一个向量,它表示输出层的值;
V是隐藏层到输出层的权重矩阵。
那么W是什么呢?
循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
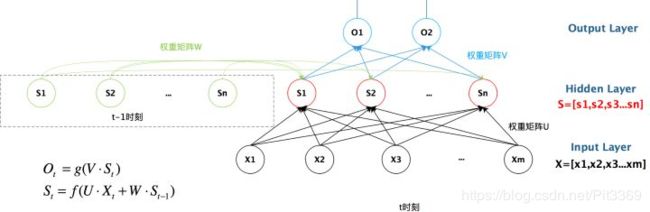
从上图就能够很清楚的看到,上一时刻的隐藏层是如何影响当前时刻的隐藏层的。
把上面的图展开,循环神经网络也可以画成下面这个样子:

在时刻t接收到输入Xt之后,隐藏层的值是St,输出值是Ot。关键一点是,St的值不仅仅取决于Xt,还取决于St-1.

反向传播算法(Back Propagation)
转自:https://www.zybuluo.com/hanbingtao/note/476663
在神经网络的训练中经常使用反向传播算法来高效地计算梯度。
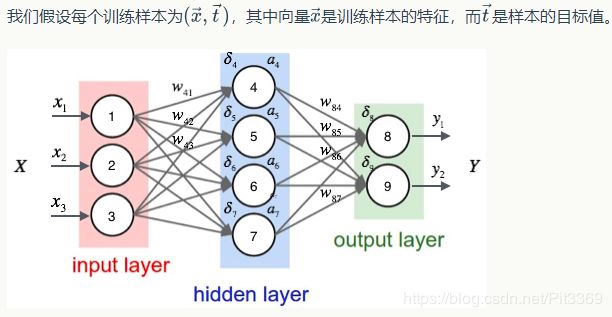
用样本的特征 x ⃗ \vec{x} x,计算出神经网络中每个隐藏层节点的输出 a i a_i ai,以及输出层每个节点的输出 y i y_i yi。
然后,我们按照下面的方法计算出每个节点的误差项 δ i \delta_i δi:




梯度消失和梯度爆炸
转自:https://zhuanlan.zhihu.com/p/44163528
上面链接对什么是梯度消失、梯度爆炸进行详细说明,这俩其实是两个极端的问题。
对于神经网络的训练,梯度在训练中起到很关键的作用。
- 如果在训练过程中发生了梯度消失,这也就意味着我们的权重无法被更新,最终导致训练失败。
- 梯度爆炸所带来的梯度过大,从而大幅度更新网络参数,造成网络不稳定(可以理解为梯度步伐太大)。
- 在极端情况下,权重的值变得特别大,以至于结果会溢出(NaN值)
注意,梯度消失和梯度爆炸只会造成神经网络中较浅的网络的权重无法更新(毕竟神经网络中是反向传播)
无论是梯度消失还是梯度爆炸,都是源于网络结构太深,造成网络权重不稳定,从本质上来讲是因为梯度反向传播中的连乘效应。
梯度爆炸的解决方法:【梯度修剪】—当梯度向量大于某个阈值时,缩放梯度向量,保证不会太大。
梯度消失的解决方法:【GRU门控循环单元网络】—引入c(记忆细胞,提供对于前文信息的保存),通过计算门τ(τ的值固定在0-1之间)的值来确定何时使用记忆细胞(常用τ=0,使用旧的c值;τ=1,使用新的c值)
其实LSTM(长短时记忆网络)也可用来解决梯度消失问题。
RNN的长期依赖问题
长期依赖是指当前系统的状态,可能受很长时间之前系统状态的影响,是RNN中无法解决的一个问题。
如果从“这块冰糖味道真?”来预测下一个词,是很容易得出“甜”结果的。但是如果有这么一句话,“他吃了一口菜,被辣的流出了眼泪,满脸通红。旁边的人赶紧给他倒了一杯凉水,他咕咚咕咚喝了两口,才逐渐恢复正常。他气愤地说道:这个菜味道真?”,让你从这句话来预测下一个词,确实很难预测的。因为出现了长期依赖,预测结果要依赖于很长时间之前的信息。
理解RNN梯度消失和弥散以及LSTM为什么能解决:
https://blog.csdn.net/hx14301009/article/details/80401227
为了改善循环神经网络的长程依赖问题,引入门控机制来控制信息的累积速度,介绍两种基于门控的循环神经网络:长短期记忆网络和门控循环单元网络
LSTM
长短期记忆(Long Short-Term Memory,LSTM)网络是循环神经网络的一个变体,可以有效地解决简单循环神经网络的梯度爆炸或消失问题。

对于在LSTM中,引入了更新门和遗忘门,将GRU的6用更新门代替,7由遗忘门代替。
其中最常用的版本里,还用到了“窥视孔链接”,其意思是:不仅取决于上一时刻的激活值和这一时刻的输入,还取决于上一个记忆细胞的值。也就是用到了三个门。
技术细节:比如有个100维的向量,有一个100维的隐藏的记忆细胞单元,然后比如第50个记忆细胞的元素只会影响第50个元素对应的那个门,所以关系是一对一的,于是并不是任意这100维的记忆细胞值可以影响所有的门元素。相反的,第一个上时刻记忆细胞的元素只能影响门的第一个元素,第二个元素影响对应的第二个元素,如此类推。
GRU
引入c(记忆细胞,提供对于前文信息的保存),通过计算门τ(τ的值固定在0-1之间)的值来确定何时使用记忆细胞(常用τ=0,使用旧的c值;τ=1,使用新的c值)
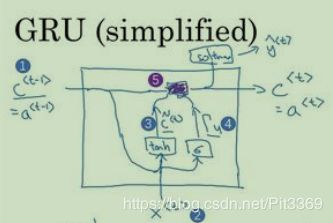
输入:1(上一时刻记忆细胞值)、3(新的候选记忆细胞值)、4(门值)
根据门值τ,来得到这个时刻记忆细胞值的值
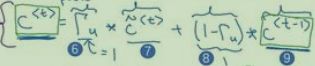
二者选取:???
GRU 的优点是这是个更加简单的模型,所以更容易创建一个更大的网络,而且它只有两个门,在计算性上也运行得更快,然后它可以扩大模型的规模。但是 LSTM 更加强大和灵活,因为它有三个门而不是两个。
如果你想选一个使用,我认为 LSTM 在历史进程上是个更优先的选择,所以如果你必须选一个,我感觉今天大部分的人还是会把 LSTM 作为默认的选择来尝试。
虽然我认为最近几年 GRU 获得了很多支持,而且我感觉越来越多的团队也正在使用 GRU,因为它更加简单,而且还效果还不错,它更容易适应规模更加大的问题。