SVM算法实例解析及应用
SVM简介
Support Vector Machine (SVM) 是一个监督学习算法,既可以用于分类(主要)也可以用于回归问题。SVM算法中,我们
将数据绘制在n维空间中(n代表数据的特征数),然后查找可以将数据分成两类的超平面。支持向量指的是观察的样本在n为空间中的坐标,SVM是将样本分成两类的最佳超平面。
SVM的作用机制
上面的简介告诉我们的是SVM是通过超平面将两类样本分开,本部分主要讲解如何将两类样本分开。以下举几个粒子:
情境1: 更好的分开两类样本的超平面,如下图中的平面B

情境2: 选取能最大化支持向量和超平面距离的超平面,如下图的平面C(原因是鲁棒性更强)
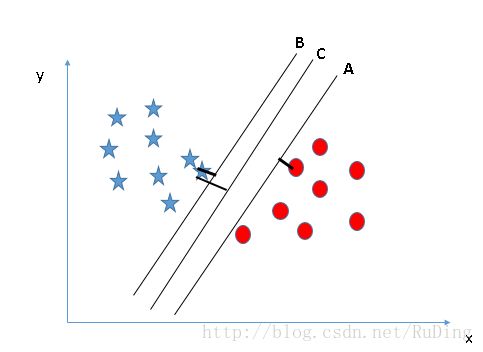
情境3: 在情境1和情境2矛盾时,SVM会优先选择分类正确,即SVM偏好分类正确大于更大的margin,如下图SVM会选择超平面A

情境4: 当某类存在异常值无法通过线性超平面将两类样本区分开时,SVM可以通过忽略异常值而寻找到超平面(soSVM对异常值具有鲁棒性)
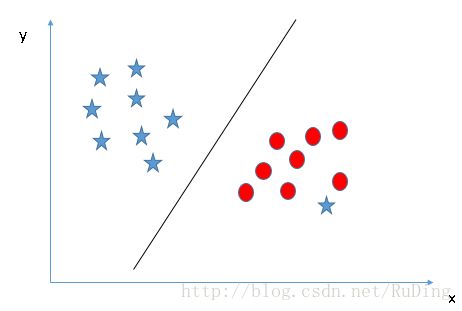
情境5: 某些情况下,SVM并不能找到一个线性超平面去划分两个类,如下图所示:

SVM的解决方案是:增加额外的特征,比如增加 z=x2+y2 作为一个新的特征,增加特征后的数据如下图所示:

以上的转变基于以下两点:
1. 所有的Z值都是正数;
2. 在原始的图中,红色点离x和y轴更近,z值相对较小;星相对较远会有较大的z值。
在两类样本中找一个线性超平面较为简单,但是我们是否需要手动加入类似于z的特征从而获得线性超平面,SVM有一个j技术叫核函数,核函数具有将低维数据转化成高维数据的作用,从而具有将线性不可分问题转化为线性可分问题的作用。
SVM应用
如果用Python的话,scikit-learn是应用机器学习算法最广泛的库,SVM算法也可以通过它加以应用。
from sklearn import svm
# Create SVM classification object
model = svm.svc(kernel='linear', c=1, gamma=1)
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)SVM调参
首先看一下参数列表:
sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=0.0, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, random_state=None)
其中最重要的三个参数为: “kernel”, “gamma” and “C”。
1. kernel: 可以选择的kernel有 “linear”, “rbf”(默认),”poly” and others。其中“rbf”和“poly”适用于非线性超平面。下面举例说明线性核和非线性核在双特征鸢尾花数据上的表现。
+++ 线性kernel:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
iris = datasets.load_iris()
X = iris.data[:, :2]
y = iris.target
C = 1.0 # SVM regularization parameter
svc = svm.SVC(kernel='linear', C=1,gamma=0).fit(X, y)
# create a mesh to plot in
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1)
Z = svc.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
plt.show()
+++ 非线性kernel:rbf

党特征数较大(>1000)比较建议使用线性的kernel,因为在高维空间中,数据更容易线性可分,也可用使用RBF但需要同时做交叉验证以防止过拟合问题。
2.gamma:当Kernel一定时,gamma值越大,SVM就会倾向于越准确的划分每一个训练集里的数据,这会导致泛化误差较大和过拟合问题,如下图所示:

3.C: 错误项的惩罚参数C,用于平衡(trade off)控制平滑决策边界和训练数据分类的准确性。

具体的参数的调节我们应该通过交叉验证的结果进行调节。
SVM的优缺点
优点:
1. 对于clear margin 分类问题效果好;
2. 对高维分类问题效果好;
3. 当维度高于样本数的时候,SVM较为有效;
4. 因为最终只使用训练集中的支持向量,所以节约内存缺点
1. 当数据量较大时,训练时间会较长;
2. 当数据集的噪音过多时,表现不好;
3. SVM不直接提供结果的概率估计,它在计算时直接使用5倍交叉验证。
文章翻译自:
Understanding Support Vector Machine algorithm from examples