机器学习中样本数据预处理
特征缩放
X_norm=(X-X_min)/(X_max-X_min )
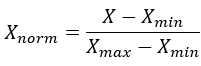
lambda x: (x - x.min()) / (x.max() - x.min())特征标准化
Gaussian with zero mean and unit variance. z=(x-μ)/σ

numeric_feats = all_X.dtypes[all_X.dtypes != "object"].index
all_X[numeric_feats] = all_X[numeric_feats].apply(lambda x: (x - x.mean())
/ (x.std()))类别特征预处理:
不能将类别特征简单表示为数字,因为模型会将类别解释成有序,实际上类别是任意排列的,这里可以用One-hot编码方式来表示。这样估计器将每个具有m个可能值的分类特征转换成m个二元特征,只有一个有效。
>>> enc = preprocessing.OneHotEncoder()
>>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
OneHotEncoder(categorical_features='all', dtype=<... 'numpy.float64'>,
handle_unknown='error', n_values='auto', sparse=True)
>>> enc.transform([[0, 1, 3]]).toarray()
array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])>>> from sklearn.feature_extraction import DictVectorizer
>>> vec = DictVectorizer()
>>> vec.fit_transform(measurements).toarray()or
all_X = pd.get_dummies(all_X, dummy_na=True)
all_X = all_X.fillna(all_X.mean())构造多项式特征
考虑到输入数据的非线性特征,往往会增加模型的复杂性。一种简单而常用的方法是多项式特征,它可以得到特征的高阶和交互项。它在PolynomialFeatures中实现
>>> import numpy as np
>>> from sklearn.preprocessing import PolynomialFeatures
>>> X = np.arange(6).reshape(3, 2)
>>> X
array([[0, 1],
[2, 3],
[4, 5]])
>>> poly = PolynomialFeatures(2)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])注意:当使用多项式核函数时,多项式特征隐式地用于核方法(例如,sklearn.svm.SVC,sklearn.decomposition.KernelPCA)。
标签编码
- Label binarization
创建多分类标签(LabelBinarizer())
>>> from sklearn import preprocessing
>>> lb = preprocessing.LabelBinarizer()
>>> lb.fit([1, 2, 6, 4, 2])
LabelBinarizer(neg_label=0, pos_label=1, sparse_output=False)
>>> lb.classes_
array([1, 2, 4, 6])
>>> lb.transform([1, 6])
array([[1, 0, 0, 0],
[0, 0, 0, 1]])如果一个实例有多个标签(MultiLabelBinarizer())
>>> lb = preprocessing.MultiLabelBinarizer()
>>> lb.fit_transform([(1, 2), (3,)])
array([[1, 1, 0],
[0, 0, 1]])
>>> lb.classes_
array([1, 2, 3])- Label encoding
标签规范化,将标签转化为0 ~ n_classes-1
>>> from sklearn import preprocessing
>>> le = preprocessing.LabelEncoder()
>>> le.fit([1, 2, 2, 6])
LabelEncoder()
>>> le.classes_
array([1, 2, 6])
>>> le.transform([1, 1, 2, 6])
array([0, 0, 1, 2])
>>> le.inverse_transform([0, 0, 1, 2])
array([1, 1, 2, 6])http://scikit-learn.org/stable/modules/preprocessing_targets.html#preprocessing-targets
缺失值和不平衡样本单独讨论,见其他两篇Blog
机器学习中样本缺失值的处理方法
机器学习中样本比例不平衡的处理方法
文本处理单独讨论,见Blog:
机器学习中的文本处理
http://scikit-learn.org/stable/