R语言中的数据挖掘算法
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
——百度百科
由于R语言可以很好地进行统计计算等工作,提供了一系列对聚类、分类算法实现的包,所以对于数据挖掘等工作有很大的帮助。
一、基于密度的DBSCAN算法
在进行调用DBSCAN算法的接口之前,需要使用命令安装依赖库,命令如下:
install.packages("fpc", dependencies = TRUE)
在R语言的fpc包中提供了实现DBSCAN聚类算法并进行可视化的函数,如下:
dbscan(data, eps, MinPts, scale, method, seeds, showplot, countmode)
data:进行聚类的数据(可以是原始数据矩阵,也可以是一个距离矩阵);
eps:密度(扫描半径);
MinPts:最小包含点数;
scale:是否对data标准化(T/F);
mehtod:三个可选参数如下,
raw:将data视为原始数据,并避免计算距离矩阵(保存存储器,也可以是慢);
dist:将data视为距离矩阵(比较快,但内存价格昂贵);
hybrid:计算部分距离矩阵(适度的内存需求,非常快);
seeds:T/F;
showplot:是否画聚类结果图(三个可选参数:0,不画:1,每次迭代画;2,每次子迭代画);
countmode:NULL或者一个用于报告进度的向量。
样例代码如下:
new1 <- c(0,5183.328938,11420.98223,21320.32421,16989.59236,14899.47468,18480.556186,10386.55199,9236.277226,10180.589785)
new2 <- c(5183.328938,0,12360.82514,22350.72344,16893.23695,20657.25945,11074.88822,11074.88822,9924.613457,9591.926128)
new3 <- c(11420.98223,12360.82514,0,2090.117679,21019.15289,21105.79131,12360.82514,12360.82514,12360.82514,11031.75103)
new4 <- c(21320.32421,22350.72344,2090.117679,0,21019.15289,21105.79131,12360.82514,12360.82514,13603.98286,12071.69154)
new5 <- c(16989.59236,16893.23695,21019.15289,21019.15289,0,5183.328938,17945.32085,15775.28119,20562.67213,20268.02825)
new6 <- c(14899.47468,20657.25945,21105.79131,21105.79131,5183.328938,0,21674.62059,21674.62059,16989.59236,16694.94848)
new7 <- c(18480.556186,11074.88822,12360.82514,12360.82514,17945.32085,21674.62059,0,5576.559036,11954.7204,13959.63176)
new8 <- c(10386.55199,11074.88822,12360.82514,12360.82514,15775.28119,21674.62059,5576.559036,0,11954.7204,13959.63176)
new9 <- c(9236.277226,9924.613457,12360.82514,13603.98286,20562.67213,16989.59236,11954.7204,11954.7204,0,6782.135558)
new10 <- c(10180.589785,9591.926128,11031.75103,12071.69154,20268.02825,16694.94848,13959.63176,13959.63176,6782.135558,0)
X <- rbind(new1,new2,new3,new4,new5,new6,new7,new8,new9,new10)
#X <- scale(X) #标准化
X #距离矩阵
Y <- as.dist(X)
#Y
par(bg="white")
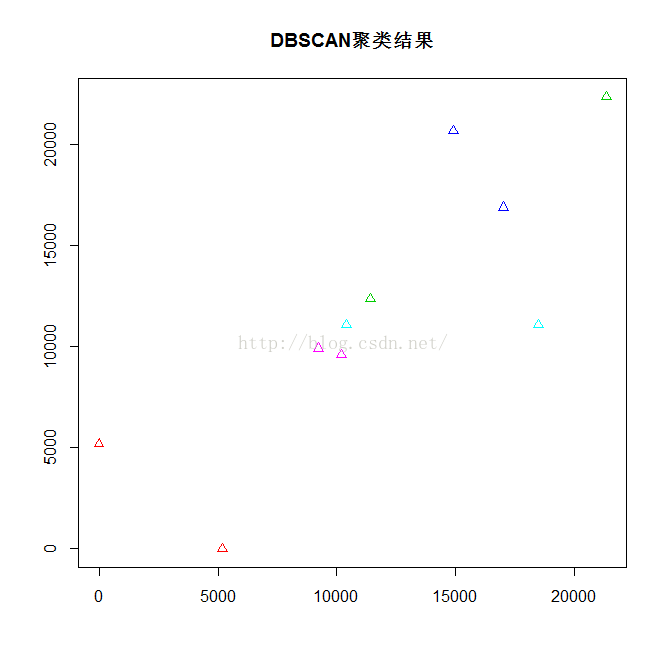
model <- dbscan(X,MinPts=2,eps=7000,scale=F,showplot=2,method="dist")
model
plot(model,X,main="DBSCAN聚类结果",ylab="",xlab="")
二、层次聚类(hierarchicalclustering)
在R语言中提供了hcluster(data,method)函数进行层次聚类,具体参数不再详细分析。
样例代码如下:
new1 <- c(0,5183.328938,11420.98223,11420.98223,16989.59236,14899.47468,8480.556186,10386.55199,9236.277226,8180.589785)
new2 <- c(5183.328938,0,12360.82514,12360.82514,16893.23695,20657.25945,11074.88822,11074.88822,9924.613457,9591.926128)
new3 <- c(11420.98223,12360.82514,0,2090.117679,21019.15289,21105.79131,12360.82514,12360.82514,12360.82514,11031.75103)
new4 <- c(11420.98223,12360.82514,2090.117679,0,21019.15289,21105.79131,12360.82514,12360.82514,13603.98286,12071.69154)
new5 <- c(16989.59236,16893.23695,21019.15289,21019.15289,0,5183.328938,17945.32085,15775.28119,20562.67213,20268.02825)
new6 <- c(14899.47468,20657.25945,21105.79131,21105.79131,5183.328938,0,21674.62059,21674.62059,16989.59236,16694.94848)
new7 <- c(8480.556186,11074.88822,12360.82514,12360.82514,17945.32085,21674.62059,0,5576.559036,11954.7204,13959.63176)
new8 <- c(10386.55199,11074.88822,12360.82514,12360.82514,15775.28119,21674.62059,5576.559036,0,11954.7204,13959.63176)
new9 <- c(9236.277226,9924.613457,12360.82514,13603.98286,20562.67213,16989.59236,11954.7204,11954.7204,0,6782.135558)
new10 <- c(8180.589785,9591.926128,11031.75103,12071.69154,20268.02825,16694.94848,13959.63176,13959.63176,6782.135558,0)
X <- rbind(new1,new2,new3,new4,new5,new6,new7,new8,new9,new10)
Y <- as.dist(X)
Y
out.hclust <- hclust(Y,"single") #最短距离法
cbind(hc1$merge,hc1$height)
rownames(S)=paste("new",1:10,"")
plclust(out.hclust,sub="",xlab="",ylab="",main="层次聚类结果图") #对结果画图
#rect.hclust(out.hclust,k=5) #用矩形画出分为5类的区域
out.id=cutree(out.hclust,k=5) #得到分为5类的数值
out.id
更多细节:
https://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Clustering/Density-Based_Clustering
https://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Clustering/Hierarchical_Clustering