C++避坑指南

导语:如果,将编程语言比作武功秘籍,C++无异于《九阴真经》。《九阴真经》威力强大、博大精深,经中所载内功、轻功、拳、掌、腿、刀法、剑法、杖法、鞭法、指爪、点穴密技、疗伤法门、闭气神功、移魂大法等等,无所不包,C++亦如是。
C++跟《九阴真经》一样,如果使用不当,很容易落得跟周芷若、欧阳锋、梅超风等一样走火入魔。这篇文章总结了在学习C++过程中容易走火入魔的一些知识点。为了避免篇幅浪费,太常见的误区(如指针和数组、重载、覆盖、隐藏等)在本文没有列出,文中的知识点也没有前后依赖关系,各个知识点基本是互相独立,并没有做什么铺垫,开门见山直接进入正文。
目录
1 函数声明和对象定义
2 静态对象初始化顺序
3 类型转换
3.1 隐式转换
3.2 显示转换
4 inline内联
5 名称查找
5.1 受限名称查找
5.2 非受限名称查找
6 智能指针
6.1 std::auto_ptr
6.2 std::shared_ptr
6.3 std::unique_ptr
7 lambda表达式
对象定义写成空的初始化列表时,会被解析成一个函数声明。可以采用代码中的几种方法定义一个对象。
//这是一个函数声明
//不是一个对象定义
string foo();
//函数声明
string foo(void);
//对象定义几种方法
string foo;
string foo{ };//c++11
string *foo = new string;
string *foo = new string();
string *foo = new string{ };//c++11(左滑可以查看全部代码,下同)
在同一个编译单元中,静态对象的初始化次序与其定义顺序保持一致。对于作用域为多个编译单元的静态对象,不能保证其初始化次序。如下代码中,在x.cpp和y.cpp分别定义了变量x和y,并且双方互相依赖。
//x.cpp
extern int y;
int x = y + 1;x.cpp中使用变量y来初始化x
//y.cpp
extern int x;
int y = x + 1;y.cpp中使变量x来初始化y
//main.cpp
extern int x;
extern int y;
int main()
{
cout << "x = " << x << endl;
cout << "y = " << y << endl;
return 0;
}如果初始化顺序不一样,两次执行的结果输出不一样,如下所示:
g++ main.cpp x.cpp y.cpp
./a.out
x = 1
y = 2g++ main.cpp y.cpp x.cpp
./a.out
x = 2
y = 1如果我们需要指定依赖关系,比如y依赖x进行初始化,可以利用这样一个特性来实现:函数内部的静态对象在函数第一次调用时初始化,且只被初始化一次。使用该方法,访问静态对象的唯一途径就是调用该函数。改写后代码如下所示:
//x.h
extern int &getX();
//x.cpp
int &getX()
{
static int x;
return x;
}getX()函数返回x对象
//y.h
extern int &getY();
//y.cpp
#include "x.h"
int &getY()
{
static int y = getX() + 1;
return y;
}y对象使用x对象进行初始化
//main.cpp
int main()
{
cout << "x = " << getX() << endl;
cout << "y = " << getY() << endl;
return 0;
}打印x和y值。通过这种方式,就保证了x和y的初始化顺序。
g++ main.cpp x.cpp y.cpp
./a.out
x = 0
y = 1g++ main.cpp y.cpp x.cpp
./a.out
x = 0
y = 1这里只描述自定义类的类型转换,不涉及如算数运算的类型自动提升等。
3.1 隐式转换
C++自定义类型在以下两种情况会发生隐式转换:
1) 类构造函数只有一个参数或除第一个参数外其他参数有默认值;
2) 类实现了operator type()函数;
class Integer
{
public:
Integer() : m_value(0) { }
//int --> Integer
Integer(int value) : m_value(value)
{
cout << "Integer(int)" << endl;
}
//Integer --> int
operator int()
{
cout << "operator int()" << endl;
return m_value;
}
private:
int m_value;
};上面定义了一个Integer类,Integer(int)构造函数可以将int隐式转换为Integer类型。operator int()函数可以将Integer类型隐式转换为int。从下面代码和输出中可以看出确实发生了隐式的类型转换。
int main()
{
Integer value1;
value1 = 10;
cout << "value1=" << value1 << endl;
cout << "*******************" << endl;
int value2 = value1;
cout << "value2=" << value2 << endl;
return 0;
}output:
Integer(int)
operator int()
value1=10
*******************
operator int()
value2=10
隐式类型转换在某些场景中确实比较方便,如:
a、运算符重载中的转换,如可以方便的使Integer类型和内置int类型进行运算
const Integer operator+(const Ingeter &lhs, const Ingeter &rhs)
{
return Integer(lhs.m_value + rhs.m_value);
}
Integer value = 10;
Integer sum = value + 20;b、条件和逻辑运算符中的转换,如可以使智能指针像原生裸指针一样进行条件判断
template
class AutoPtr
{
public:
operator bool() const { return m_ptr; }
private:
T *m_ptr;
};
AutoPtr ptr(new int(10));
if(ptr)
{
//do something
} 隐式类型转换在带来便利性的同时也带来了一些坑,如下所示:
template
class Array
{
public:
Array(int size);
const T &operator[] (int index);
friend bool operator==(const Array &lhs, const Array &rhs);
};
Array arr1(10);
Array arr2(10);
if(arr1 == arr2[0])
{
//do something
} 构造函数隐式转换带来的坑。上述代码定义了一个Array类,并重载了operator==运算符。本意是想比较两个数组,但是if(arr1 == arr2)误写成了f(arr1 == arr2[0]),编译器不会抱怨,arr2[0]会转换成一个临时Array对象然后进行比较。
class String
{
public:
String(const char *str);
operator const char* () const{ return m_data; }
private:
char *m_data;
};
const char *strcat(const char *str1, const char *str2)
{
String str(str1);
str.append(str2);
return str;
}operator type()带来的坑。上述String类存在到const char *的隐式转换,strcat函数返回时String隐身转换成const char *,而String对象已经被销毁,返回的const char *指向无效的内存区域。这也是std::string不提提供const char *隐式转换而专门提供了c_str()函数显示转换的原因。
3.2 显示转换
正是由于隐式转换存在的坑,C++提供explicit关键字来阻止隐式转换,只能进行显示转换,分别作用域构造函数和operator(),如下所示:
1) explicit Ctor(const type &);
2) explicit operator type();
class Integer
{
public:
Integer() : m_value(0) { }
//int --> Integer
explicit Integer(int value) : m_value(value)
{
cout << "Integer(int)" << endl;
}
//Integer --> int
explicit operator int()
{
cout << "operator int()" << endl;
return m_value;
}
private:
int m_value;
};用explicit改写Integer类后,需要进行显示转换才能与int进行运算,如下:
int main()
{
Integer value1;
//value1 = 10; //compile error
value1 = static_cast(10);
cout << "value1=" << (int)value1 << endl;
//int value2 = value1; //compile error
int value2 = static_cast(value1);
cout << "value2=" << value2 << endl;
return 0;
} 为了保持易用性,C++11中explicit operator type()在条件运算中,可以进行隐式转换,这就是为什么C++中的智能指针如shared_ptr的operator bool()加了explicit还能直接进行条件判断的原因。下面代码来自shared_ptr源码。
explicit operator bool() const _NOEXCEPT
{ // test if shared_ptr object owns a resource
return (get() != nullptr);
}内联类似于宏定义,在调用处直接展开被调函数,以此来代替函数调用,在消除宏定义的缺点的同时又保留了其优点。内联有以下几个主要特点:
a、内联可以发生在任何时机,包括编译期、链接期、运行时等;
b、编译器很无情,即使你加了inline,它也可能拒绝你的inline;
c、编译器很多情,即使你没有加inline,它也可能帮你实施inline;
d、不合理的inline会导致代码臃肿。
使用内联时,需要注意以下几个方面的误区:
1)inline函数需显示定义,不能仅在声明时使用inline。类内实现的成员函数是inline的。
inline int add(int, int);
int add(int x, int y) //no inline
{
return x + y;
}
class Calculator
{
public:
static int add(int x, int y) //inline
{
return x + y;
}
static int sub(int x, int y);
};
int Calculator::sub(int x, int y) //no inline
{
return x - y;
}2)通过函数指针对inline函数进行调用时,编译器有可能不实施inline
inline int add(int x, int y)
{
return x + y;
}
//定义函数指针
int (*pfun)(int, int) = add;
add(3, 5); //实施inline
pfun(3, 5); //通过函数指针调用,可能无法inline3)编译器可能会拒绝内联虚函数,但可以静态确定的虚函数对象,多数编译器可以inline
class Animal
{
public:
virtual void walk() = 0;
};
clas Penguin : public Animal
{
public:
virtual void walk(){ }
}
Animal *p1 = new Penguin();
p1->walk(); //大多数编译器无法inline
Penguin *p2 = new Penguin();
p2->walk(); //大多数编译器可以inline4)inline函数有局部静态变量时,可能无法内联
inline void report(int code)
{
static int counter = 0;
doReport(code, ++counter);
}
report(-9998);//可能无法inline5)直接递归无法inline,应转换成迭代或者尾递归。下面分别以递归和迭代实现了二分查找。
template
inline int recursionSearch(const vector &vec, const T &val, int low, int high)
{
if(low > high) return -1;
int mid = (low + high) / 2;
if(val < vec[mid])
{
return recursionSearch(vec, val, low, mid - 1);
}
else if(val > vec[mid])
{
return recursionSearch(vec, val, mid + 1, high);
}
else
{
return mid;
}
} 二分查找的递归方式实现。
template
inline int iterationSearch(const vector &vec, const T &val)
{
int low = 0;
int high = vec.size() - 1;
while(low <= high)
{
int mid = (low + high) / 2;
if(val < vec[mid])
{
high = mid -1;
}
else if(val > vec[mid])
{
low = mid +1;
}
else
{
return mid;
}
}
return -1;
} 二分查找的迭代方式实现。
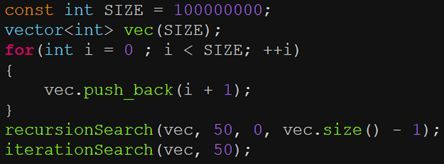
分别调用二分查找的递归和迭代实现,开启-O1优化,通过查看汇编代码和nm查看可执行文件可执行文件符号,只看到了递归版本的call指令和函数名符号,说明递归版本没有内联,而迭代版本实施了内联展开。
6)构造函数和析构函数可能无法inline,即使函数体很简单
class Student : public Person
{
public:
Student() { };
virtual ~Student() { }
private:
School m_school;
};
Student::Student()
{
try
{
Person::Person(); //构造基类成分
}
catch(...)
{
throw;
}
try
{
m_school.School::School();//构造m_school;
}
catch(...)
{
Person::~Person();
throw;
}
}表面上构造函数定义为空且是inline,但编译器实际会生成如右侧的伪代码来构造基类成分和成员变量,从而不一定能实施inline。
C++中名称主要分为以下几类:
a) 受限型名称:使用作用域运算符(::)或成员访问运算符(.和->)修饰的名称。
如:::std、std::sort、penguin.name、this->foo等。
b) 非受限型名称:除了受限型名称之外的名称。
如:name、foo
c) 依赖型名称:依赖于形参的名称。
如:vector
d) 非依赖型名称:不属于依赖型名称的名称。
如:vector
5.1 受限名称查找
受限名称查找是在一个受限作用域进行的,查找作用域由限定的构造对象决定,如果查找作用域是类,则查找范围可以到达基类。
class B
{
public:
int m_i;
};
class D : public B
{
}
void foo(D *pd)
{
pd->m_i = 0; //查找作用域到达基类B,即 B::m_i;
}5.2 非受限名称查找
5.2.1 普通查找:由内向外逐层查找,存在继承体系时,先查找该类,然后查找基类作用域,最后才逐层查找外围作用域
extern string name; //(1)
string getName(const string &name) //(2)
{
if(name.empty())
{
string name = "DefaultName"; //(3)
return getName(name); //引用name(3)
}
return name/*引用name(2)*/ + ::name/*引用name(1)*/;
}5.2.2 ADL(argument-dependent lookup)查找:又称koenig查找,由C++标准委员会Andrew Koenig定义了该规则——如果名称后面的括号里提供了一个或多个类类型的实参,那么在名称查找时,ADL将会查找实参关联的类和命名空间。
namespace ns
{
class C{ };
void foo(const C &c)
{
cout << "foo(const C &)" << endl;
}
}
int main()
{
ns::C c;
foo(c);
return 0;
}根据类型C的实参c,ADL查找到C的命名空间ns,找到了foo的定义。
了解了ADL,现在来看个例子,下面代码定义了一个Integer类和重载了operator<运算符,并进行一个序列排序。
namespace ns
{
class Integer
{
public:
explicit Integer(int value) : m_value(value){ }
int m_value = 0;
};
}
bool operator<(const Integer &lhs, const Integer &rhs)
{
return lhs.m_value < rhs.m_value;
}
int main()
{
using ns::Integer;
std::vector v = {Integer(1), Integer(5), Integer(1), Integer(10)};
std::sort(v.begin(), v.end());
for(auto const &item : v)
{
std::cout << item.m_value << " ";
}
std::cout << std::endl;
return 0;
} 上面的代码输出什么? 1 1 5 10吗。上面的代码无法编译通过,提示如下错误
/usr/include/c++/4.8.2/bits/stl_heap.h:235:35:
错误:no match for ‘operator<’
(operand types are ‘ns::Integer’ and ‘ns::Integer’)
if (*(__first + __secondChild) < *(__first + (__secondChild - 1)))operator<明明在全局作用于有定义,为什么找不到匹配的函数?前面的代码片段,应用ADL在ns内找不到自定义的operator<的定义,接着编译器从最近的作用域std内开始向外查找,编译器在std内找到了operator<的定义,于是停止查找。定义域全局作用域的operator<被隐藏了,即名字隐藏。名字隐藏同样可以发生在基类和子类中。好的实践:定义一个类时,应当将其相关的接口(包括自由函数)也放入到与类相同的命名空间中。
namespace ns
{
class Integer
{
public:
explicit Integer(int value) : m_value(value){ }
int m_value = 0;
};
bool operator<(const Integer &lhs, const Integer &rhs)
{
return lhs.m_value < rhs.m_value;
}
}把operator<定义移到ns命名空间后运行结果正常

再来看一个名称查找的例子。
template
struct B
{
typedef int T;
};
template
struct D1 : B
{
T m_value;
};
int main()
{
int value = 10;
D1 d1;
d1.m_value = &value;
cout << *d1.m_value << endl;
return 0;
} 这段代码编译时提示如下错误,我们用int *实例化D1的模板参数并给m_value赋值,编译器提示无法将int *转换成int类型,也就是m_value被实例化成了int而不是int *。

我们将代码改动一下,将D2继承B
template
struct B
{
typedef int T;
};
template
struct D2 : B
{
T m_value;
};
int main()
{
int value = 10;
D2 d2;
d2.m_value = &value;
cout << *d2.m_value << endl;
return 0;
} 
D1和D2唯一的区别就是D1继承自B
二阶段查找(two-phase lookup):首次看到模板定义的时候,进行第一次查找非依赖型名称。当实例化模板的时候,进行第二次查找依赖型名称。
D1中查找T时,基类B
D2中查找T时,基类B
6 智能指针
6.1 std::auto_ptr
std::auto_ptr是C++98智能指针实现,复制auto_ptr时会转移所有权给目标对象,导致原对象会被修改,因此不具备真正的复制语义,不能将其放置到标准容器中。auto_ptr在c++11中已经被标明弃用,在c++17中被移除。
auto_ptr ap1(new string("foo"));
auto_ptr ap2 = ap1;
//内存访问错误,ap1管理的指针已经被置位空
string str(*ap1);
auto_ptr ap3(new string("bar"));
vector> ptrList;
//ap2和ap3被复制进容器后其管理的指针对象为空
//违反标准c++容器复制语义
ptrList.push_back(ap2);
ptrList.push_back(ap3); 6.2 std::shared_ptr
std::shared_ptr采用引用计数共享指针指向对象所有权的智能指针,支持复制语义。每次发生复制行为时会递增引用计数,当引用计数递减至0时其管理的对象资源会被释放。但shared_ptr也存在以下几个应用方面的陷阱。
1)勿通过传递裸指针构造share_ptr
{
string *strPtr = new string("dummy");
shared_ptr sp1(strPtr);
shared_ptr sp2(strPtr);
} 这段代码通过一个裸指针构造了两个shared_ptr,这两个shared_ptr有着各自不同的引用计数,导致原始指针被释放两次,引发未定义行为。
2)勿直接将this指针构造shared_ptr对象
class Object
{
public:
shared_ptr这段代码使用同一个this指针构造了两个没有关系的shared_ptr,在离开作用域时导致重复析构问题,和1)是一个道理。当希望安全的将this指针托管到shared_ptr时,目标对象类需要继承std::enable_shared_from_this
class Object : public std::enable_shared_from_this3)请勿直接使用shared_ptr互相循环引用,如实在需要请将任意一方改为weak_ptr。
struct You;
struct I
{
shared_ptr you;
~I() { cout << "i jump" << endl; }
};
struct You
{
shared_ptr me;
~You() { cout << "you jump" << endl; }
};
int main()
{
shared_ptr i(new I());
shared_ptr you(new You());
i->you = you;
you->me = i;
return 0;
} 
代码运行结果,没有看到打印任何内容,析构函数没有被调用。最终你我都没有jump,完美的结局。但是现实就是这么残酷,C++的世界不允许他们不jump,需要将其中一个shared_ptr改为weak_ptr后资源才能正常释放。
struct You
{
weak_ptr me;//现在是weak_ptr
~You() { cout << "you jump" << endl; }
};
int main()
{
shared_ptr i(new I());
shared_ptr you(new You());
i->you = you;
you->me = i;
return 0;
} 
4)优先使用make_shared而非直接构造shared_ptr。make_shared主要有以下几个优点:
a、可以使用auto自动类型推导。
shared_ptr
auto sp = make_shared
b、减少内存管理器调用次数。shared_ptr的内存结构如下图所示,包含了两个指针:一个指向其所指的对象,一个指向控制块内存。
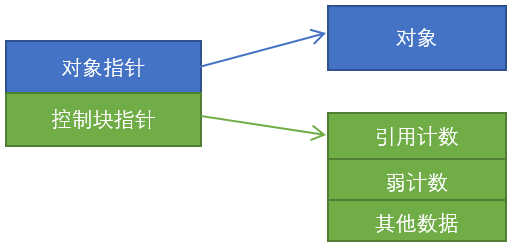
shared_ptr 这条语句会调用两次内存管理器,一次用于创建Object对象,一次用于创建控制块。如果使用make_shared会一次性分配内存同时保存Object和控制块。
c、防止内存泄漏。
class Handler;
string getData();
int handle(shared_ptr sp, const string &data);
//调用handle
handle(shared_ptr(new Handler()), getData()); 这段代码可能发生内存泄漏。一般情况下,这段代码的调用顺序如下:
new Handler() ① 在堆上创建Handler对象
shared_ptr() ②创建shared_ptr
getData() ③调用getData()函数
但是编译器可能不按照上述①②③的顺序来生成调用代码。可能产生①③②的顺序,此时如果③getData()产生异常,而new Handler对象指针还没有托管到shared_ptr中,于是内存泄漏发生。使用make_shared可以避免这个问题。
handle(make_shared(), getData()); 这条语句在运行期,make_shared和getData肯定有一个会先调用。如果make_shared先调用,在getData被调用前动态分配的Hander对象已经被安全的存储在返回的shared_ptr对象中,接着即使getData产生了异常shared_ptr析构函数也能正常释放Handler指针对象。如果getData先调用并产生了异常,make_shared则不会被调用。
但是make_shared并不是万能的,如不能指定自定义删除器,此时可以先创建shared_ptr对象再传递到函数中。
shared_ptr sp(new Handler());
handle(sp, getData()); 6.3 std::unique_ptr
std::unique_ptr是独占型智能指针,仅支持移动语义,不支持复制。默认情况下,unique_ptr有着几乎和裸指针一样的内存开销和指令开销,可以替代使用裸指针低开销的场景。
1)与shared_ptr不同,unique_ptr可以直接指向一个数组,因为unique_ptr对T[]类型进行了特化。如果shared_ptr指向一个数组,需要显示指定删除器。
unique_ptr ptr(new T[10]);
//显示指定数组删除器
shared_ptr ptr(new T[10], [](T *p){delete[] p;}); 2)与shared_ptr不同,unique_ptr指定删除器时需要显示指定删除器的类型。
shared_ptr pf(fopen("data.txt", "w"), ::fclose);
//显示指定数组删除器类型
unique_ptr pf(fopen("data.txt", "w"), ::fclose);
unique_ptr> pf(fopen("data.txt", "w"), ::fclose); 1)捕获了变量的lambda表达式无法转换为函数指针。
using FunPtr = void(*)(int *);
FunPtr ptr1 = [](int *p) { delete p; };
FunPtr ptr2 = [&](int *p) { delete p; };//错误
2)对于按值捕获的变量,其值在捕获的时候就已经确定了(被复制到lambda闭包中)。而对于按引用捕获的变量,其传递的值等于lamdba调用时的值。
int a = 10;
auto valLambda = [a] { return a + 10; };
auto refLambda = [&a] { return a + 10; };
cout << "valLambda result:" << valLambda() << endl; //20
cout << "refLambda result:" << refLambda() << endl; //20
a += 10;
cout << "valLambda result:" << valLambda() << endl; //20
cout << "refLambda result:" << refLambda() << endl; //303)默认情况下,lambda无法修改按值捕获的变量。如果需要修改,需要使用mutable显示修饰。这其实也好理解,lambda会被编译器转换成operator() const的函数对象。
auto mutableLambda = [a]() mutable { return a += 10; };4)lambda无法捕捉静态存储的变量。
static int a = 10;
auto valLambda = [a] { return a + 10; }; //错误
