微服务架构系列一:关键技术与原理研究

导语:人不为己,天诛地灭这个成语中的“为”念作wéi,阳平二声,是“修养,修为”的意思。成语的意思是:如果人不修身,那么就会为天地所不容。本意并不是经常被很多人曲解的人如果不为自己着想,那么就会为天地所不容。以此为引,本文本着Stay Hungry, Stay Foolish的精神,利用闲暇时间,抛开平时工作中的常用组件,追本溯源,尽可能从源头去思考、分析、发现,结合过去的一些经验做了一点微服务架构相关的调研和简单实践,以能在日常工作中对内部组件更好的理解和使用。由于时间和水平有限,文中一些地方难免有纰漏,欢迎大家留言指正和补充建议,衷心感谢。
前言
系统架构设计是系统构建过程中的非常关键的一部分,决定着系统的稳定性、鲁棒性、扩展性等一系列问题,定义了在系统内部,如何根据技术、业务和组织及可扩展性、可维护性和灵活性等一系列因素,把系统划分成不同的组成部件,并使这些部件相互协作为用户提供某种特定的服务。不过伴随着业务的不断发展,功能的持续增加,传统单块架构对应的沟通、管理、协调等成本越来越高,出现了维护成本增加,交付周期长,新人培养久,技术选型成本高,水平和垂直扩展性差,组建全功能团队难等一系列问题。为解决传统系统架构面临的问题,随着领域驱动设计,持续交付技术,虚拟化技术,小型自治团队组建,基础设施智能化自动化,大型集群系统设计等技术和实践的发展,微服务应运而生。微服务作为一种分布式系统解决方案,聚焦细粒度服务使用的推动。不同的微服务协同工作,每个服务都有自己的生命周期。由于微服务主要围绕业务领域构建模型,而且整合了过去十多年来的新概念和新技术,因此可以避免由传统的分层架构引发的很多问题及陷阱,具有很大的研究价值和实用意义。
本文通过阅读众多相关文献和专著以及相关技术官方网站的在线文档和开源社区优秀博客,从微服务的单一职责、自治性、领域驱动设计等设计原则开始,研究了其相关技术栈,包括容器虚拟化技术,服务发现技术,通信机制技术,持续集成、交付、部署等。其中较为详细的介绍了提供高可用分布式键值存储及服务发现等功能的Etcd的使用及原理,RESTful API、Thrift RPC、gRPC等同步通信技术的对比以及异步通信中高性能分布式消息队列Kafka的使用和原理等。 在以上研究基础上,重点调研了谷歌能够管理容器化应用和服务及进行自动化扩缩容的开源框架Kubernetes的架构原理,包括服务API,控制管理器,调度器,Kubelet,Kube-Proxy,DNS等核心技术以及GUI,日志与监控等组件,并重点分析了框架的安全依赖,包括认证,授权,准入控制等相关技术。并在云上和本机搭建了Kubernetes高可用集群及相关组件,作为微服务实践和密码强度评测实验的基础架构。
依托Kubernetes集群,本文进行了以基于机器学习的密码强度检测为核心的微服务实践,之所以选择这个实验载体而没有选择常见的支付、评论、画像、push等业务载体是因为之前应用微服务架构的实际生产环境应用场景是在“K歌厅”(一种像电话亭一样的微型KTV包厢,目前市面主要有三家:全民k歌自助店,友唱·全民k歌,咪哒唱吧minik)大致流程是用户通过公众号或小程序扫VOD二维码码进行支付,web前端经过SLB调用前端机PHP“胶水”层,胶水层经过IngressController调用K8S集群中的golang相关微服务,包括支付,开房,PUSH,短信等相关微服务,其中支付服务会把结果写到kafka,消费者服务消费后通过长连接微服务把相关结果再推送给VOD,这个场景由于多了VOD(K歌厅终端相关设备,除了音响相关设备,一般由一块显示屏,一个点歌屏组成,有的还有广告屏+提示板)较普通移动应用——人和APP及服务端交互相比相对复杂,不太好表述,最终抽象出关于密码强度评测的一个简单事例。同时因为在云计算和大数据迅猛发展的今天,机器学习被越来越多的应用到各行各业中,但是它的微服务化工程落地相对少见和困难,同时密码强度评测技术作为安全领域的重要组成部分也亟需使用机器学习等新技术去更新换代,而这些技术背后的底层服务和业务服务也将随着微服务的发展,业务本身规模的发展以及组织架构的需要而逐步微服务化,从而相辅相成发挥更大的效能,以此选例也求有所提高和突破。
绪论
1. 研究背景和意义
系统架构设计阐述了在系统内部,如何根据技术、业务和组织及可扩展性、可维护性和灵活性等一系列因素,把软统划分成不同的组成部件,并使这些部件相互协作为用户提供某种特定的服务的相关技术,是系统构建过程中非常关键的一部分,好的架构决定了系统的稳定性、鲁棒性尤其是可扩展性等一系列问题,这也佐证了为什么系统架构设计一直以来都是IT领域经久不衰的话题之一。
1.1传统架构
随着面向对象和设计模式的发展,从功能实现及代码组织的角度,依据职责划分产生了经典的MVC框架,MVC模式最早在1979年由Trygve Reenskaug提出[1],是Xerox PARC(施乐帕罗奥多研究中心)在20世纪下页为程序语言Smalltalk发明的一种软件架构,MVC是模型(Model),视图(View),控制器(Controller)的缩写,其中模型聚焦数据访问及存储,视图聚焦数据显示和用户交互,控制器聚焦业务处理。每一层都有具体的职责和分工,这降低了层与层之间的耦合度,这便是软件架构的经典模式,又被称为三层架构。三层架构将系统进行了逻辑分层,但是在物理上最终会运行在同一进程中,所以三层架构又被称为单块架构。
虽然三层架构解决了代码间调用复杂、职责不清的问题,甚至在一定程度上解决了企业内部根据技能调配人员的难题,而且其易于开发、易于测试、易于部署和易于水平伸缩等特性也提高了生产效率。但是随着应用功能的多样化复杂化及技术团队的不断壮大,其对应的沟通、协调和管理等成本也越来越高,出现了维护成本增加,交付周期长,新人培养久,技术选型成本高,水平和垂直扩展性差,组建全功能团队难等一系列问题。
随着业务的不断发展,功能的持续增加,三层逻辑架构设计中的单块架构已很难满足业务快速变化的要求:一方面,代码的可维护性、可扩展性和灵活性在不断降低;而另一方面,系统的测试成本、构建成本和维护成本又在显著增加。随着项目的不断发展和产品规模的不断扩大,单块架构应用的改造甚至重构势在必行。为解决这些问题,SOA(Service Oriented Architecture,一种面向服务的架构)出现了,顾名思义它有两个核心:一是服务,二是架构。SOA架构中包含多个服务,服务之间通过互相配合来完成一系列功能。一个服务通常以独立的形式存在于操作系统中,服务与服务之间不再通过进程内调用方式进行通信,而是改为网络调用,甚至当服务需要方Client和服务提供方Server都部署在同一机器时,也是通过网络调用完成请求和响应。SOA相对于传统单块架构的优势和特点是服务化,松耦合,灵活的架构,支持敏捷等。
SOA最早由Gartner在1996年提出,2002年12月,Gartner再次提出SOA是“现代应用开发领域中最重要的课题”[2]。不过虽然面向服务的架构SOA的理论和实践方面已经研究了十多年[3],但是由于给SOA下定义的组织机构太多,没有一个统一的标准,而且加之用SOA概念包装已有或推出各种产品解决方案厂商的一定程度上的误导和其本身的抽象性及广义性,导致在很长一段时间内人们对于SOA都存在着不同的认知和理解。所以尽管大家做了很多努力和尝试,但终究无法在如何做好SOA这件事情上达成一致的方法论。除了不同角色的参与人员很难把它作为一个整体进行统筹外,在实施SOA过程中还会有各种各样的别的问题:比如通信机制及协议的制定,服务粒度的确定和边界的划分,各种中间件的选择等。而且现实问题是现有的SOA解决方案并不能有效的防止服务之间的过度耦合而且很难把应用程序的大小控制在合理的范围内,所以对于单块架构发展到一定规模遇到的问题同样不可避免。
不管是经典三层架构还是面向服务的架构SOA或是从面向资源的ROA还是其它衍生品,在传统架构下,随着产品的发展,软件的迭代,代码间的逻辑会越来越复杂,代码也越来越多,时间久了代码库就会变得非常庞大,以至于在修改逻辑或者增加新功能时想定位在什么地方做修改都很困难。尽管大家都想在巨大的代码库中做到模块化,但实际上模块之间的界限很难确定,而且更不好处理的是,相似功能的代码在代码库中随处可见,使得修改旧逻辑和增加新功能变得更加异常复杂。而且随着组织架构的变大,参与人员的变多,这一问题将会变得更加棘手。
1.2 微服务架构
随着领域驱动设计,按需虚拟化,持续交付,小型自治团队,基础设施自动化,大型集群系统等技术和实践的发展以及为解决传统架构的痛点,微服务应运而生。微服务是一种分布式的系统解决方案,着力推动细粒度的服务的使用,不同的微服务协同工作,每个服务都有自己的生命周期。由于微服务主要围绕业务领域构建模型,所以可以避免由传统的分层架构引发的很多问题。微服务整合了过去十年来的新概念和新技术,因此得以避开许多面喜爱那个服务的架构中的陷阱[4]。
微服务的由来:
2011年5月,在威尼斯附近的软件架构师小组首次提及了“Microservice”一词,以描述参会者中的许多人在近期探索研究的许多架构风格。
2012年3月,来自ThoughtWorks 的James Lewis 在克拉科夫33rd Degree 会议上的[5]中就此做了相关的案例研究报告,几乎同一时间Fred George也做了与之相同的工作。
来自Netflix的Adrian Cockcroft把这种方法称为“细粒度SOA”,并认为这是一套在Web规模下具有开创意义的架构类型。Joe Walnes,Dan North,Evan Botcher和Graham Tackley也在这篇文章中对此作出了评论。
2012年5月,之前首次提及微服务的软件架构师小组最终决议,以“microservice”为最合适的架构名称。
2014年,Martin Fowler 和James Lewis 共同提出微服务的概念。在 Martin Fowler的博客中,他将微服务的定义概括如下:简而言之,微服务架构是将单个应用程序开发为一组小型服务的方法,每个应用程序运行在自己的进程中,并通过轻量级的通讯机制进行通信,通常是基于HTTP资源的API。这些服务是围绕业务功能构建的,并可以通过全自动部署机制独立部署。这些服务应该尽可能少的采用集中式管理,并根据所需,使用不同的编程语言和数据存储[6]。
相对于传统架构,微服务架构有一系列好处:技术异构更容易,新技术应用更自由,架构与组织架构相互促进相互优化,更好的建设和锻炼团队,扩展容易,部署简单(更新和回滚),高重用性,高弹性,替换陈旧组件更容易等等。
总而言之,微服务就是一些协同工作的小而自治的服务,它在技术决策上给了我们极大的自由度,使我们能够更快的响应日趋严峻的挑战和一些不可避免的问题。而且微服务有很多好处,它的很多架构思想也同样适用于各种分布式系统,相对于分布式系统或者面向服务的架构,微服务甚至更胜一筹,它可以把这些好处推向极致。
2. 本文研究内容
传统架构的发展及微服务架构的由来,微服务关键技术研究和实践,Kubernetes的架构和原理剖析,基于机器学习的应用程序在Kubernetes集群的部署编排,基于机器学习的密码强度评测微服务等。
3. 本文组织结构
第一章介绍了研究的背景和意义,具体讲述了传统架构的发展以及存在的问题和微服务架构的由来,并列举了比较有代表性的国内外的发展研究现状;第二章讲述了微服务架构设计的关键,主要从设计原则,容器技术,服务发现,通信机制,持续集成等几方面展开论述;第三章以谷歌Kubernetes为框架基础,以实际的组件进一步讲述了重要的微服务架构原理;第四章从原理分析,业务建模,一步步实现基于机器学习的密码强度评测服务;第五章针对第四章实现的服务,搭建相关环境并部署编排服务和进行相关验证;第六章对论文整体进行了概括和总结,并对微服务架构设计的未来进行了展望。
微服务架构设计的关键技术研究
1. 设计原则
1.1 单一职责
对于伴随着功能越来越多带来的代码库越来越大而导致的一系列问题最好的解决方式就是通过抽象层或者模块划分来保证代码的内聚性。单一职责原则对内聚性做了很好的阐述,正如Robert C. Martian在其专著《敏捷软件开发》中对单一职责的描述:把因为相同原因而变化的东西聚合到一起,而把因为不同原因而变化的东西分离开来[7]。
微服务通过业务的边界来划分独立服务的边界,应用这一理念,就可以很好地明确某个功能的代码在哪,而且微服务的功能专注于某些业务逻辑以及在某个边界之内,这样也同时避免了传统架构中因代码库过大而产生的一系列问题。当然对于服务多小才是小的也就是服务粒度划分问题,不同的人有不同的见解,团队架构、安全因素、技术难题、迭代速度等这些考量都可能成为服务划分的依据。我们需要注意的是,服务被划分的越小,独立性越明显的同时随之而来的管理越多的服务就会越复杂,所以不管什么方式都需要做到具体情况具体分析和适度。
1.2 自治性
每个微服务都是一个个的独立个体,可以独立部署在PAAS(Platform As A Service,平台即服务)上,也可以作为一个独立的进程存在。微服务之间均通过网络调用进行通信,这在加强服务间的隔离性的同时还降低了耦合。对于如何更好地解耦,也就是避免一旦出现问题,不至于波及部分服务甚至所有服务不可用,有一个黄金法则,也就是“是否能够修改一个服务并将对其部署,而不影响其它任何服务”。也就是需要我们通过正确的建模和合理的暴露API来让服务本身要做到充分的自治。
1.3 领域驱动设计
领域驱动设计主要专注于如何对现实世界的领域进行建模。世界著名软件建模专家Eric Evans在其专著《领域驱动设计——软件核心复杂性应对之道》中引入了新的概念限界上下文(Bounded context):一个给定的领域都含有多个限界上下文,每个限界上下文中的模型分成两部分,一部分需要与外部通信,另一部分则不需要。每个限界上下文都有明确的接口,该接口决定了暴露哪些模型给其它的限界上下文[8]。
领域逻辑告诉我们对于模块和服务的划分应该遵循共享特定的模型,而不是共享内部表示这个原则,这样就可以做到松耦合。而松耦合可以保证可以独立的修改及部署单个服务而不需要修改系统的其它部分,这是微服务设计中最重要的一点。除此之外通过共享模型和隐藏模型我们可以更加清楚的识别领域边界,更好地隐藏边界内部实现细节,而边界内部是高相关性的业务,以此做到了高内聚,这样可以避免对多处相关地方做修改和同时发布多个相关微服务而带来的不可控和风险,同时能更快速的交付。
2. 容器虚拟化技术
容器虚拟化技术是一种更底层的基础设施,甚至可能会颠覆以虚拟化技术为核心的IAAS(Infrastructure as a Service,即基础设施即服务)。容器像一个集装箱一样把软件封在一个盒子里,然后用传统的标准化方法把软件部署在服务器,而不需要关注软件本身的实现细节。容器技术是比DDD和微服务更加具体化的东西。
2.1 Docker发展简介
说到容器虚拟化技术,很快会联想到Docker,Docker作为一个开源应用容器引擎,最初是由dotCloud公司创始人Solomon Hykes在法国时发起的一个公司内部的项目,是基于dotCloud公司多年的云服务技术的以一次革新,在2013年以Apache2.0授权协议开源头,开始在Github上维护其主要代码[9][10]。Docker项目加入了Linux基金会,并成立推动开放容器联盟(OCI),经过近几年的快速发展已经成为了很多公司的标配,某种程度上也成为了容器虚拟化技术的代名词。
同传统虚拟化技术相比,Docker具有更高的性能和效率:1)更快速的交付和部署:开发者可以基于并引用各种标准镜像来构建自己特定功能的镜像,完成后镜像后,运维人员可以直接应用这个镜像进行部署;2)更轻松的迁移和扩展:Docker容器可以在包括物理机、虚拟机、公有云、私有云、混合云等各种平台上运行,跨平台支持能力非常强;3)更简单的管理和维护:基于Docker容器的镜像支持以增量的方式更新和分发,而且支持版本号操作,这些特性都为管理和维护提供了很大的便利[11]。
2.2 Docker结构介绍
Docker官方的引擎组件图很好地展示Docker的组件:Docker的核心底层是一个守护进程(Docker Daemon),对外提供RESTful接口(REST API)和命令行(Client Cli)交互,然后就是镜像和装载镜像的容器以及用于通信的网络和存储数据的数据卷,如图2-1。
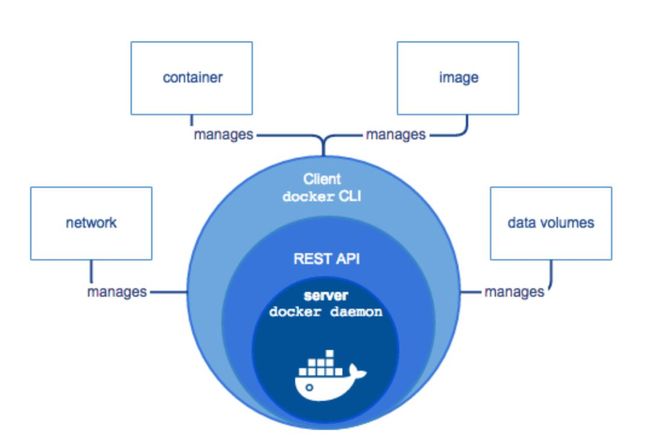
图2-1 Docker引擎组件
有了上述组件,当我们想运行一个容器时,首选需要获取镜像,获取镜像有两种方式,一种是从指定的本地镜像库或网上镜像库中拉取容器所需的镜像;另一种是根据镜像构建文件(Dockerfile)用命令构建,有了镜像后进行创建容器,然后分配联合文件系统并挂载一个用以记录修改容器操作的层(这个读写层可以被提交以更新镜像,如果不作提交重新启动后会被消除)之后分配网络桥接接口并设置IP地址,最后运行指定的程序并捕获应用程序的日志相关信息。相关流程如图2-2所示[9]。
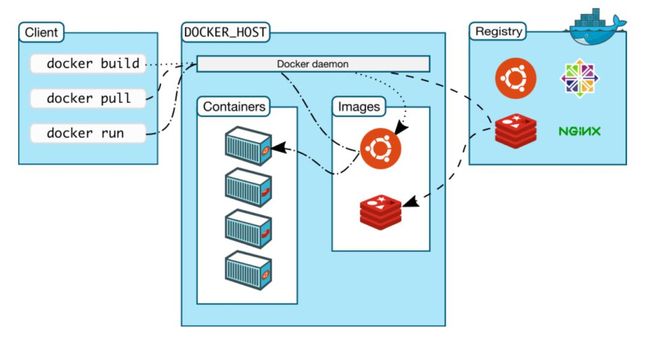
图2-2 Docker运行流程
2.3 Docker底层实现
概括的说Docker是比传统虚拟机更轻量的“虚拟机”,通过守护进程与主操作系统进行通信并为各个容器分配资源。与传统虚拟机包括整个操作系统不同,docker共享系统内核,仅包含应用本身和必要依赖,所以在节省大量的磁盘空间及其它系统资源的同时启动更快,性能更接近原生,系统支持量更大,且单机能实现支持上千容器。
具体来看,Docker通过Linux 命名空间(Namespaces)、控制组(Control Group)和联合文件系统(Union File System)三大技术支撑了其核心实现。
1)命名空间:通过Linux命名空间为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法(进程相关的命名空间,还会设置与用户、网络、IPC 以及 UTS 相关的命名空间),Docker 实现了不同容器间的隔离,Docker 容器内任意进程都对宿主机器的进程无感知,这一点让不同容器看起来就像运行在多台不同的物理机上一样,更安全的同时也更具灵活性;
2)控制组:通过CGroup实现宿主机器上物理资源的隔离,诸如 CPU、内存、磁盘 I/O 和网络带宽等的隔离。用文件系统来实现的CGroup中,一个子系统就是一个资源控制器(比如/sys/fs/cgroup/cpuset/cpuset.cpus文件中的参数能运行在CPU哪些核心上作选择限制),一个任务就是一个系统的进程(tasks文件中每个参数都是一个进程ID),CGroup是一组按照某种标准划分的进程,所有的资源控制都是以 CGroup 作为单位实现的,控制组之间有层级关系,默认子控制组会继承上一级父控制组的参数,系统管理员可以利用Cgroup为多个容器合理的分配资源并且可以避免出现多个容器互相抢占资源的问题;
3)联合文件系统:UnionFS 是Linux操作系统中用于把多个文件系统联合到同一个挂载点的文件系统服务。而 AUFS 即 Advanced UnionFS,顾名思义就是 UnionFS 的升级版,它能够提供更优秀的性能和效率,它解决了镜像相关的问题。Docker中每一个镜像都是由一系列只读层组成,Dockerfile中每一个命令都会在已有的层上创建一个新层。每一个容器其实等于镜像加上一个可读写的层,这样同一个镜像就可以对应多个容器[9]。
2.4 Docker网络模式
Host模式:此方式容器将不会得到独立的网络命名空间,而是与宿主机共享一个网络命名空间,容器不会虚拟自己的网卡和配置IP,会直接使用宿主机的IP和端口,也就是说不需要任何NAT转换,如果容器对网络传输效率要求较高则可以首选,当然此模式下其它的资源,诸如文件系统,进程列表等还是和宿主机隔离的。
None模式:通过此模式创建出来的容器拥有自己的网络命名空间,除了lo没有任何网卡,这样的意义是可以做到安全隔离,当然用户也可以自行创建网卡、IP、路由等网络配置,根据自我需要实现更加灵活复杂的网络。
Bridge模式:此模式下是Docker的默认方式,启动时如果不指定Net参数,Docker服务会创建一个docker0网桥,它上面有一个docker0内部接口,在内核层连通了其它网卡,而主机上的每一个容器,docker0会从其所在子网中为容器分配一个IP,并设置容器的默认网关为docker0的IP,同时Docker会在主机上创建一堆虚拟网卡Veth pair设备,Docker将虚拟网卡的一端放在容器中作为容器网卡,也就是eth0,另一端放在主机中,以vethxxx这样的名字命名,并将此网络设备加入到docker0的网桥中,这使得主机上的所有容器通过docker0网桥连在了一个二层网络中。网络拓扑如图2-3所示。
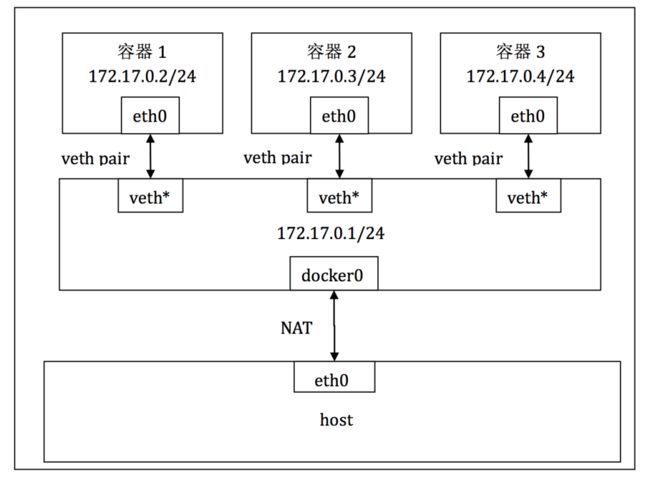
图2-3 Docker网络拓扑图
User-defined模式:除了host、none、bridge这三个自动创建的网络,用户也可以根据需要自己创建网络,目前docker提供了三种网络驱动:bridge、overlay和macvlan。其中brigde和前面的bridge网络模式类似;后两种是为了支持容器跨主机通信,overlay可以帮助用户创建基于VxLan的overlay网络,VxLan可以将二层数据封装到UDP进行传输,提供与VLAN相同但更强的扩展性和灵活性的以太网二层服务;macvlan是本质一种网卡虚拟化技术,允许一个物理网卡配置多个Mac地址(interface),此方式最大优点是不需要创建Linux bridge直接通过以太interface连接到物理网络以达到高性能。
3. 服务发现
什么是服务发现(Service Discovery),HIGHOPS中的文章《服务发现:六问四专家》中是这么定义的:服务发现跟踪记录大规模分布式系统中的所有服务,使其可以被人们和其它服务发现,DNS就是一个简单的例子,当然复杂的服务发现需要有更多的功能,比如储存服务的元数据,健康监控,多种查询和实时间更新等。当然不同的上下文环境诸如网络网络设备发现,零配置网络(Rendezvous )发现和 SOA 发现等具有不同的服务发现含义,不过不论是哪一种场景,服务发现都应该提供一种协调机制来发布自己以及在零配置情况下查找其它服务[12]。简单说服务发现就是获取服务地址的服务,复杂的服务提供了多种服务接口和端口,当应用程序需要访问这个服务时,如何确定它的服务地址呢?此时,就需要服务发现了。
3.1 三大关键功能
1)高可用:服务元数据存储是服务发现的基础,而数据一致性又是保证服务一致性的关键,而且数据一致性大多依赖分布式算法,同时分布式系统中也要求多数机器可用,所以高可用是必须的功能之一。
2)服务注册:服务实例要想被其它服务知道,必须通过自己或者其它管理组件把服务地址相关元数据存储,同样的当服务地址变化时需要更新,服务停止时需要销毁,这一系列操作也就是服务注册。
3)服务查询:复杂的服务提供了多种服务接口和端口,部署环境也比较复杂,一旦服务组件通过服务注册存储了大量信息后,它就需要提供接口给其它组件或服务进行复杂的查询,比如通过固定的目录获取动态的IP地址等。
3.2 常用方式介绍
1)DNS:我们非常熟悉且最简单的一种方式,跟域名和IP映射的原理类似,我们可以将服务域名名称和一到多个机器IP进行关联或者是一个负载均衡器(指向服负载均衡好处是可以避免失效DNS条目问题)。DNS的服务发现方式最大的优点就是它是一种大家熟知的标准形式,技术支持性好。缺点就是当服务节点的启动和销毁变得更加动态时DNS更新条目很难做到高可用和实时性。
2)Zookeeper:最开始是作为Hadoop项目的一部分,基于Paxos算法的ZAB协议,它的应用场景非常广泛,包括配置管理,分布式锁,服务间数据同步,领导人选举,消息队列以及命名空间等。类似于其它分布式系统,它依赖于集群中的运行的大量节点,通常至少是三台,以提供高可用的服务。借助于其核心提供的用于储存信息的分层命名空间,我们可以在此中增删改查新的节点以实现储存服务位置的功能。除此外还可以对节点添加监控功能,以便节点改变时可以得到通知。作为服务发现主要优点是成熟、健壮以及丰富的特性和客户端库,缺点是复杂性高导致维护成本太高,而且采用Java以及相当数量的依赖使其资源占用率过高。
3)Consul:是强一致性的数据存储,使用Gossip形成动态集群(原生数据中心Gossip系统,不仅能在同一集群中的各个节点上工作,而且还能跨数据中心进行工作)。支持配置管理,服务发现以及一种键值存储,也具备类似zookeeper的服务节点检查功能。主要优点是支持DNS SRV发现服务,这增强了与其它系统的交互性。除此外Consul还支持RESTful HTTP接口,这使集成不同技术栈变得更容易。
4)Doozerd:是比较新的服务发现解决方案,与 ZooKeeper 具有相似的架构和功能,因此可以与 ZooKeeper 互换使用。
5)Eureka:如果需要实现一个 AP( Availability and Partition )系统, Eureka 是一个很好的选择,因为在出现网络分区时,Eureka 选择可用性,而不是一致性。
6)Etcd:采用RESTFul HTTP协议的键值对存储系统,基于Raft算法实现分布式,具有可用于服务发现的分层配置系统。主要优点是,容易部署,设置和使用,有非常好的文档支持。缺点是实现服务发现需要与第三方工具结合。常与Etcd组合使用的工具是Registrator和Confd,Registrator通过检查容器在线或停止来完成相关服务数据的注册和更新,Confd作为轻量级的配置管理工具通过储存在Etcd中的数据来保持配置文件的最新状态。
3.3 Etcd优点及Raft算法
随着把Etcd以组件形式作为高可用强一致性的服务发现存储仓库的Coreos和Kubernetes等项目在开源社区的发展,Etcd受到越来越多的关注[13]。Etcd作为分布式系统中最关键的数据的分布式可靠键值存储系统,主要关注于:简单,定义明确的面向用户的API(gRPC),支持HTTP协议的PUT/GET/DELETE操作;安全,支持可选客户端证书认证的TLS;快速:每秒10,000次写入速度;可靠,使用Raft算法充分实现分布式[14]。Etcd实现高可用的基础是Raft算法,类似于Zookeeper的基于的Paxos的简化版Zab协议,也是用于保证分布式环境下多节点数据一致性。相比在过去十年中占主导地位的Paxos算法,Raft算法更简单更好理解,且更容易在系统中进行实现。
Raft是一种基于Leader选举的算法,所有节点在Leader,Follower和Candidate三个角色之间切换。选举过程中,在初始的所有Follower中任意一个的随机Timer时间到后,此Follower就会变为Candidate同时向其它节点发送Requestvote请求,如果同一时间存在若干个Candidate,Follower们采取先来先投票的策略,同时也会遵循Log匹配原则(Log Matching Property),简单说就是通过对比选举周期以及日志索引来确定当前需要被投票的Candidate是否具有赞同票的前提——相比自己拥有更全更新的数据,如果超过半数Follower把赞同票投给一个Candidate,此时这个Candidate就会变成Leader,其它未竞选成功的Candidate会重新变为Follower,选举完成后Leader和Follower通过心跳检测维持相互的状态,如果发生超时那么新的一轮选举又会开始,如此往复。新数据提交过程中,Leader扮演分布式事务中的协调者,采用二阶段(Two-Phase Commit)提交,Leader先更新日志然后广播给Follower,等大多数Follower节点返回成功后,Leader开始第二阶段提交同时广播Follower给以持久化数据;这两阶段中如果任意一个阶段都有超过半数的Follower返回False或者无返回,那么这个分布式事务是不成功的,此过程虽然没有回滚操作,但是由于数据不会真正在多数节点上提交,数据会在之后的过程中被覆盖掉。数据同步过程中,由于新一届Leader选举出来后,虽然选举过程保证了Leader的数据是最新的,但是Follower中可能存在数据不一致的情况,所以需要一个补偿机制来把Leader数据同步给Follower以纠正数据,而这种机制正是借助于心跳请求——Entries为空的请求特殊格式AppendentriesRPC,当Follower收到来自Leader的心跳时,会做一致性判断,由于Leader给每一个追随者维护了一个将要发送给该Follower的下一条日志条目的索引Nextindex(当一个Leader开始掌权时,它会将Nextindex初始化为它自己的最新日志条目索引数加1),如果一个Follower的日志和Leader的不一致,Appendentries RPC时会返回失败,在失败之后,Leader会将Nextindex递减然后重试Appendentries RPC,如此几个来回,经过不断协商判断,最终Leader维护的Nextindex会达到一个和Follower日志一致的地方,这时Appendentries RPC会返回成功,Follower中冲突的日志条目都被移除了,并且添加所缺少的Leader的日志条目,不一致检查完毕从而日志就一致了。
总之Raft 算法不论在教学方面还是实际实现方面都比 Paxos 和其他算法更出众,比其它算法也更加简单和更好理解,而且拥有许多开源实现并被许多公司支持使用,除此之外它的安全性也已经被证明,最重要的它的效率相比其它算法也更加具有竞争力[15]。
4. 通信机制
微服务架构本质上还是分布式系统,而且相比传统的分布式系统,由于服务粒度更小,数据更多元化,交互会更复杂甚至需要经常夸节点,这使得网络成为微服务架构中又一重要问题。不管是同步通信机制还是异步通信机制,各种组件以及服务边界的通信都要根据实际情况来选择合适的机制。当然不管是何种方式,在分布式网络环境中我们都应该知道网络是不可靠的,所以在制定通信机制时可能需要额外的考虑容错和弹性等问题。
4.1 REST和RESTful
REST( Resource Representational State Transfer,表现层状态转移),通俗解释就是资源在网络中以某种表现形式进行状态转移,资源即数据;某种表现形式诸如JSON,XML,JEPG等;状态变化通常通过HTTP动词诸如GET、POST、PUT、DELETE等来实现,REST出自卡内基梅隆大学Roy Fielding的博士毕业论文[16]。
REST有很多优点,当然无规矩不成方圆,有它的优点也有它的原则:首先,客户端服务器分离,这样的好处是操作简单,同时提高了客户端的简洁和服务端的性能,而且可以让服务器和客户端分别优化和改进;其次,无状态,也就是客户端每个请求独立且要包含服务端需要的所有信息,这样的好处是可以单独查看每个请求,可见性高且更容易故障恢复,还能降低服务端资源使用;第三,可缓存,服务器返回信息时,必须被标记是否可以进行缓存,如果可以进行缓存,客户端可能会复用历史信息发送请求,这样可以减少交互次数和提升速度;第四,系统分层,组件之间透明,这样降低了耦合和系统复杂性,提高了可扩展性;第五,统一接口,提高交互可见性和可单独改进组件;最后,支持按需实现代码,这可以提高可扩展性[17]。
满足上述约束和原则的应用程序或设计风格就是 RESTful,REST并没有规定底层需要支持什么协议,但是最常用的是HTTP,因为HTTP的动词方法能够很好的和资源一起使用,所以REST就是通过使用HTTP协议和uri利用客户端和服务端对资源进行CRUD(Create/Read/Update/Delete)增删改查操作。通过这种风格设计的应用程序HTTP接口也就是RESTful HTTP API是现在Web架构中的常用方法,可以作为在微服务中解决集成问题的RPC替代方案。
4.2 从Thrift到gRPC
RPC(Remote Procedure Call)远程过程调用是一种是典型的计算机同步通信协议。此协议允许计算机程序跨机器调用,其核心思想是隐藏远程调用的复杂,也就是通过把网络通讯抽象为远程过程调用,使得调用远程程序就像调用本地子程序一样。这样开发者就不再需要去关注网络编程细节,从而可以聚焦业务逻辑本身以提高工作效率。本质上RPC是一种进程间通信,只不过是两个不同物理机上进程之间的通信。RPC是一种C/S架构的服务模型,Server端提供接口供Client调用,为了降低了技术的耦合,常用Thrift、gRPC来在实现,这两种方式支持不同的语言之间协作交互,让异构系统更简单。
Thrift是由Facebook开发的远程服务调用框架是对IDL(Interface Definition Language,描述性语言)的一种具体实现,采用接口描述语言定义并创建服务,支持跨语言开发,它所包含的的代码生成引擎可以在多种主流语言诸如C++,Java,Python,PHP,RubyErlang,Perl,C#等创建基于二进制格式传输的无缝服务,相对于XML和JSON体积更小,对于高,并发、大数据量和多语言环境更有优势[18]。我们在一开始的微服务架构研究实践的同步通信机制中除了应用基于HTTP协议的RESTful API就是应用Thrift实现PRC来进行远程调用,具体的做法是通过PHP实现基于HTTP的RESTful API来作为接入层来连结客户端(包括手机端APP、Web端、PC端APP等)和微服务(主要做数据交互,当然也包括基础设施,诸如短信服务,支付服务等等)。也就是具体端的调用是通过HTTP访问Web Server(Nginx),然后转发到PHP-fpm,PHP内部通过Thrift去调用微服务。后来之所以不用Thrift了而选择Protocol buffer,主要是因为Thrift不同版本之间虽然兼容但是自动生成的代码变化太大,不利于代码追踪,而且有时候会导致适配语言的特殊修改失效,比如空对象抛异常的问题;而且Thrift相关技术文档很少,包括中文和英文的要彻底的理解和熟练的运用Thrift只能读源码,学习成本比较高。而Protocol Buffer作为谷歌提供的也是基于二进制的语言中立的,平台无关的,可扩展的序列化结构化的开源序列化框架[19]。在序列化和反序列化速度、大小等很多方面的都比Thrift更好[20]。而gPRC就是默认基于Protocol Buffer的。
gRPC默认使用Protocol Buffer作为其IDL和其底层基础消息交换格式,具体来说,就是基于指定可以远程调用的方法和参数及返回类型的服务定义,也就是proto文件定义,在服务端使用Protocol Buffer的编译器protoc和某种语言gRPC插件来生成服务端代码以及用于填充,序列化和检索消息类型的常规Protocol buffer代码,并用此语言实现此服务接口,然后通过绑定指定端口并运行gRPC的服务来等待客户端调用和处理相关逻辑并返回协议定义格式的对应数据;在客户端同样用Protocol Buffer编译器Protoc根据Proto文件描述和对应客户端语言的gRPC插件生成客户端代码以及用于填充,序列化和检索消息类型的常规Protocol buffer代码,然后去调用服务端和处理相关逻辑并接收协议定义格式的数据。如图2-4[21]展示了不同语言的服务端和客户端通过基于Protobuf协议的gRPC进行的远程调用。在后续的第五章的试验中,我们会分别通过PHP的客户端和Golang客户端通过gRPC去调用Python实现的密码评测服务端。此外,最新的Google API将配备其接口的gRPC版本,这意味着可以借助gRPC轻松的将谷歌应用程序构建到一些服务中,而且在最新的Proto3中会有更多的新功能和支持更多的语言,相信gRPC会越来越通用。
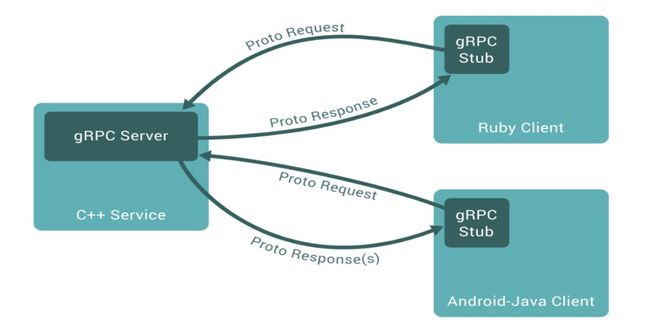
图2-4 gRPC服务端客户端交互流程
4.3 消息队列之Kafka
消息队列是分布式系统中异步通信常用的组件,可以用来解耦异构系统或不同服务之间的耦合从而提高可用性和保障最终一致,也可以将传统的串行业务进行并行处理从而提高吞吐量和降低响应时间,除此外还可以用来进行流量削峰以实现高性能可伸缩架构,当然保证消息顺序作为队列的天然特性也是用途之一。常用消息队列有ActiveMQ,RabbitMQ,Kafka,除此外还有Activemq的下一代产品更快更强健的Apollo,以及阿里开源的支撑多次双十一活动的Rocketmq,甚至我们非常熟悉的内存数据库Redis也可以基于发布和订阅做简单的消息队列。
在技术选型时,我采用的是Kafka——Linkedin在2010年12开源后由Apache软件基金会开发的通过Scala和Java编写的分布式的,支持分区的,多副本的基于Zookeeper协调的消息系统,主要是三方面原因:
第一:Kafka作为分布式系统,易于扩展;支持组(Group)的概念能比较灵活的实现消息队列功能或分发订阅,且当某个节点故障时时能自动负载容错;无论发布的消息是否被消费都会被持久化一定时间,这也是区别于大部分传统消息队列的优点;当然其提供消息持久化能力的时间复杂度为O(1)的效率,以及对TB级以上数据也依然能够保证常数时间复杂度的访问性能。轻松支持数百万的消息高吞吐量[22]等高性能是非常适合大规模分布式软件架构及微服务架构选型的。
第二,Kinkedin 大规模应用实践的保障,Linkedin团队还做了个实验研究,对比Kafka与Apache Activemq V5.4和Rabbitmq V2.4的性能,实验结果表明,无论是消息生产和消息消费,Kafka都显示出明显的性能优势,当然这得益于Kafka更高效的存储格式及传输模式,包括批量发送消息,无需待代理确认消息,无缓存设计及Zero-Copy和Sendfile技术等[23]。
第三,其它消息队列的局限性,比如Rabbitmq因为是基于Erlang编写的消息队列,由于Erlang语言本身的限制,二次开发成本比较高;类似的基于AMQP协议的ActiveMQ封装起来也不是很容易,并且并发性不够好。
下面较详细介绍一下Kafka基本概念和核心原理,分区(Partition)是Kafka的并行的基本单元,一个主题(Topic可以理解为一个消息队列的名称)可以分为多个分区,每个分区都是一个有序队列,不同分区只能在不同代理(一台Kafka服务器就是一个Broker一般称为代理)上,分区的每条消息都会被分配一个有序的ID(Offset),消息发送到哪个分区上有两种基本策略,分别是Key Hash 和Round Robin,另外Kafka只保证一个分区中的消息顺序发给消费者(Consumer),不保证一个Topic的整体也就是多个分区的顺序;一个分区可以有多个副本,Kafka在0.8版本后提供了副本(Replication)机制来提高可用性可靠性以保证代理的故障转移,当然约束条件是主题的分区副本不能大于代理数量,引入副本后,如果同一个分区有多个副本,副本之间会选出一个领导者(Leader)与生产者(Producer)和消费者交互,鉴于此,为了更好地负载均衡和容灾时依然能负载均衡,副本分配有三个原则:
1)在所有代理之间平均分配副本
2)对分配给特定代理的分区的副本分布在其它代理上
3)如果所有代理都有机架(Rack)信息,则尽可能将每个分区的分本分配到不同的机架
这部分设计非常巧妙,通过阅读源码,得知具体的做法是:在一开始通过从位于Zookeeper存放的代理列表元数据随机选择一个代理作为初始副本索引(firstReplicaIndex)分配第一个分区的第一个副本,然后依次顺序移位代理列表存放其它分区的第一个副本(每个分区的这第一个副本作为此分区的首选副本会在开始当选leader),每个分区的其它副本机架感知函数assignReplicasToBrokersRackAware在第一轮分配时会根据代理列表大小随机下一个副本索引(nextReplicaShift),之后每轮循完一轮代理列表会把下一个副本索引加1,这样做的好处是使不同分区组合不同的代理以更好的均匀分配副本,使可靠性更高,当然剩余的具体副本索引(replicaIndex)选择依据了下面的算法,因为前面已经分配了分区的第一个副本,所以剩余副本索引的基础偏移量范围是即从0到最大代理数减去1,即
shift = 1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1)(firstReplicaIndex + shift)% nBrokers[24][25]。
根据上述算法做了一个简单的实验,如图所示,创建了一个topic名字为“III”的主题,12个分区,4个备份,我们可以看到,在第一次分配分区0的第一个备份时随机选择了初始副本索引3(代理brokerid为1003),依据上述公式可以算得下一个副本索引的初始值是1,利用docker-compose创建Kafka集群,代入公式可以算得三轮分配如下图2-5 。
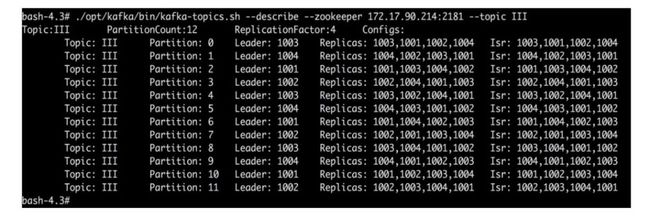
图2-5 docker-compose创建的Kafka集群分区备份实验结果
如图画2-6,三个生产者,两个Groupa一个消费者,Groupb三个消费者,三个Broker,三个Topic,其中Topic 1为一个分区无备份,Topic 2 两个分区两个备份,Topic 3三个分区三个备份,红色的备份代表Leader,右面的Zookeeper集群用来存放集群的元数据,包括Broker的存活消息,每个分区的Leader消息等。
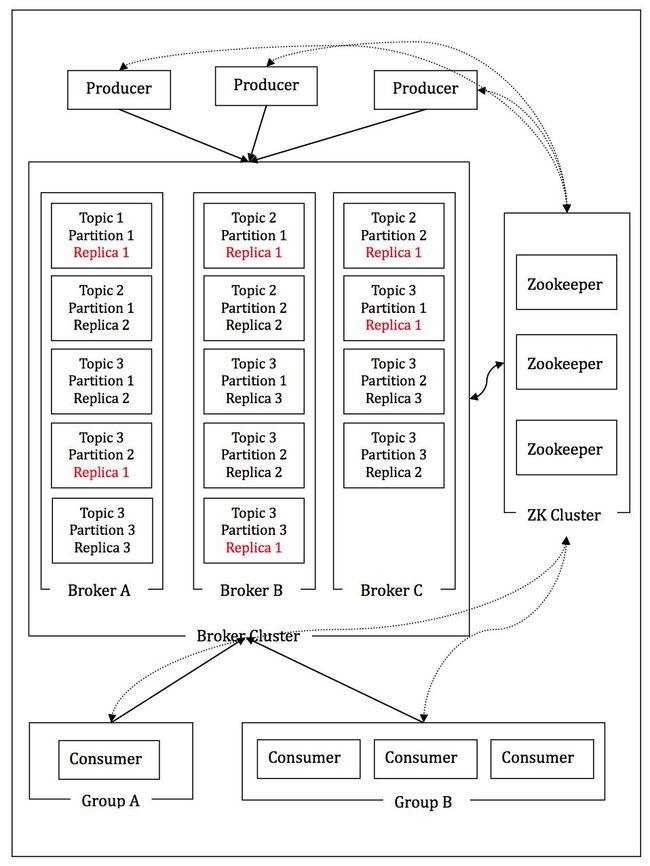
图2-6 Kafka网络拓扑架构图
对于Kafka的安装除了传统的一个Broker一个物理主机的安装方式,在容器时代借助Docker Compose或者借助能够简单的完成将应用从 Docker Swarm 到Kubernetes 的转换过程的kcompose可以轻松构建三个节点的高可用Kafka集群。
5. 持续集成
传统部署单块系统的流程大家都很熟悉了,无非是各种形式的文件同步,比如利用类似数据镜像备份工具Rsync的增量文件同步,或是针对不同操作系统构建不同操作系统安装包等。但是在众多相互依赖的微服务架构中,部署就相对复杂了,因为这涉及持续集成(Continuous Integration)和持续交付(Continuous Delivery)以及持续部署(Continuous Deployment)相关技术,包括自动化构建,自动化测试,自动化部署等过程,通过相应工具的支持整个过程可以做到可视化,可重复,可回溯。
5.1 科学集成构建微服务
持续集成的主要作用是保证新提交的代码与已有代码进行集成,从而使应用程序保持最新以及所有开发测试等相关人员保持同步,一般情况下持续集成会验证代码的有效性,包括静态检查,编译检查,单元测试等以产生可正常运行的构建物。所谓构建物可以理解为在部署阶段可以被反复利用的软件集成包。构建物大致可以分为平台特定构建物,操作系统构建物,镜像构建物。常见的平台特定构建物,比如Java应用平台的Jar包或War包;操作系统构建物,比如对于Debian而言的Deb包,Centos而言的Rpm包;镜像构建物,比如构建Docker容器的镜像。几种不同的构建物的区别通过名称来看显而易见,无特定平台依赖和操作系统依赖的只是依赖轻量级虚拟化技术和容器技术的镜像构建物无疑是持续集成微服务构建物的首选。
如何科学的生成构建物是一个值得思考的问题,这涉及到代码库和持续集成构建等一系列问题。根据本章的第一部分微服务设计原则中提到的自治性原则,最科学的方式是给每一个微服务一个代码库同时对应一个单独的持续集成构建,当然这是最理想的方式,但是在项目初期这样操作未免过于复杂和不方便集中管理,所以一般采取的操作是一个代码库的不同目录对应一个持续集成构建,比如在第接下来的第五章的实验中就是用版本控制工具Git的服务端钩子技术,通过区分不同目录以构建相应的服务,这样降低了复杂性同时避免了一个代码库一个构建下的小改动全部构建的情况。
5.2 构建流水线持续交付及部署
持续交付是持续集成的下一阶段,用来校验构建物是否达到了部署到生产环境的要求,通俗来讲这一阶段进行一系列的测试,可以大致分为集成测试,用户行为测试,性能测试等。一般情况下这个过程会分解为多个阶段,不同阶段针对性做一些特定操作,把不同阶段进行规整从而得到构建流水线,构建流水线除了让每一步更清晰还可以更好地跟踪构建物的质量,而且每完成一个阶段,也可以量化的知道离最终发布的差距,从而有的放矢。需要注意的是,一般情况下不同测试阶段的构建物应该保证唯一,这样更能够保证最终生产环境部署版本的有效性及避免问题交叉,当然对于不同阶段涉及不同环境的测试诸如测试环境,预发布环境,生产环境等可以通过加载不同配置文件来达到预期目的。
持续交付与持续集成和持续部署是密不可分的,可谓承上启下,持续交付有很多卓越之处,它不但保证了构建物所依赖的代码和配置等都在版本控制中,重要的是有了持续交付可以使测试更快更好地反馈及进行,从而使开发更容易,部署更高效。
一般而言持续集成,持续交付,持续部署等是需要自动化支持的,为什么要自动化,因为如果纯粹使用人工方式而没有自动化技术参与,当服务器的数量翻倍时,很明显一个工作人员的工作量也会翻倍,而且持续集成本身要求迭代更快速,如果没有自动化的实施持续集成反而会使整体效率更低,但是反过来,如果让服务器控制和服务部署等工作自动化,那么显然工作量不会因服务器数量增多而线性增加了[26]。这极大的提高和优化了生产力,尤其是面对微服务架构下大量的服务自动化更有必要。最重要的是,据调查研究显示,持续集成可以有效的提高软件质量和避免缺陷[27]。
5.3 持续集成引擎Jenkins
说到持续集成,交付,部署自动化,很容易联想到Jenkins,如同Jenkins官网的介绍一般:可以建立任何规模的伟大事情,作为领先的开源自动化服务,它拥有数百个插件来为构建和部署以及自动化提供支持;安装也非常方便,可以通过本地系统软件包或Docker镜像安装,甚至可以通过任何安装了Java运行时环境(JRE)的计算机独立运行[28]。图2-7是本文在实验时利用Docker镜像安装的开始页面截图,可以看到默认推荐安装了21款插件,其中不乏有版本控制,邮件,目录等相关操作的优秀插件。
图 2-7 Jenkins开始页面默认安装插件图
基于Kubernetes微服务架构原理和组件研究
Kubernetes是谷歌十几年来大规模应用容器技术的经验积累和升华的成果基于Borg的开源版,一个全新的基于Docker容器技术的分布式集群管理领先方案,为容器化的应用提供了资源调度,部署运行,服务发现,扩容缩容,滚动升级,健康监控等一系列功能[29]。之所以选择谷歌的Kubernetes作为容器的集群化和调度工具即编排工具,是对比和实践了其它同类产品之后的选择,主要是基于Marathon的Apache Mesos和Docker Swarm Mode 。
Mesos的初衷是为了建立一个高效可扩展的系统,并且这个系统能够支持多样化的各种框架,Mesos本身并不负责调度而是委派授权。通常的做法是借助实现了调度的框架,比如支持原生Docker 的Marathon。但是由于Mesos的调度方式是两级调度,采用了悲观的并发控制,相比于Kubenertes的乐观策略的共享状态调度在资源分配的并发控制的速度上不占优势[30],尤其面对微服务架构下的大规模集群管理的多高并发场景中的多并发资源分配情形更是略显不足。而Docker Swarm Mode是继Docker的独立编排器Docker Swarm之后的内置集群管理器,通过docker swarm init 和docker swarm join可以轻松构建Swarm集群。这是一种轻量的容器编排工具。但是正是由于Docker Swarm太轻量级,导致很多功能不完善,比如它不能很好的处理节点失败问题,正因如此,在实际的生产环境中,一般不太推荐使用[31]。
整体而言,除了学习成本更高,学习路线更陡峭外,Kubernetes无论是在架构还是功能上都要更好,尤其是集群管理方面很强大,图3-1是Kubernetes的架构图[32],可以对Kubernetes有一个整体的认知。
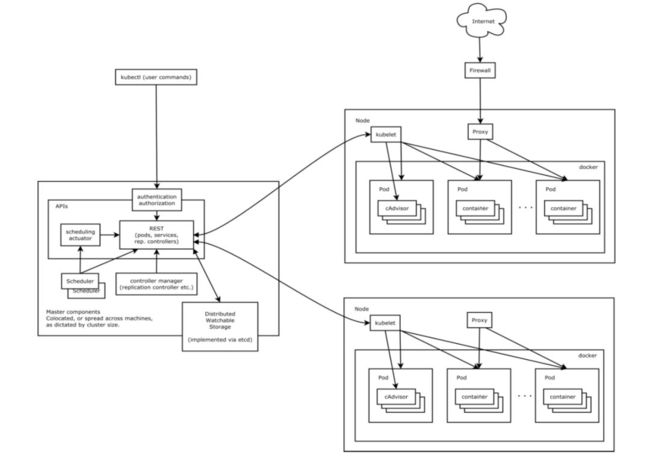
图3-1 Kubernetes整体架构图
1. Master基础组件
Master基础组件是指在Kubernetes集群中起管理控制功能的组件,主要是接口服务,控制管理器,调度器。
1.1 API接口组件
Kube-apiServer是Kubernetes核心组件之一,提供了管理Kubernetes集群的REST API,包括认证,授权,准入控制等安全校验,通过操作保存在Etcd中的元数据提供集群状态等相关管理。apiServer支持同时提供HTTPS API和HTTP API,HTTPS默认监听端口6443,通过--secure-port配置,HTTP默认监听端口8080通过--unsecure-port配置,HTTP API是非安全接口,没有认证和授权检查,在新的版本中已经默认关闭。当然实际操作中更多的是通过命令行交互模式也就是kubectl来访问apiServer;除此外可以通过Kubernetes的支持的不同语言的客户端库请求;还可以通过/swaggerapi可以查看Swagger API,/swagger.json查看OpenAPI,当然更直观清晰的是设置--enable-swagger-ui=true后通过/swagger-ui访问Swagger UI——为REST APIs 定义的一个标准的语言无关的接口文档,如图3-2所示。
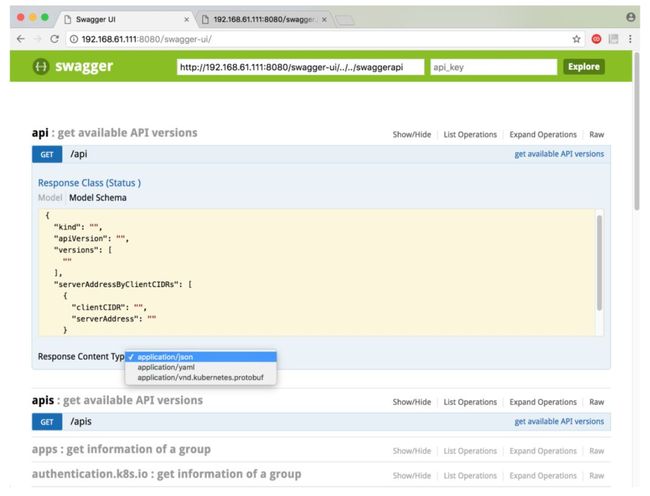
图3-2 Kubernetes的Server API的Swagger UI
1.2 管理控制器
Kube-controller-manager管理控制器由诸如Replication Controller,Node Controller,Deployment Controller等等一系列控制器组成,通过apiServer监看整个集群的状态以保证集群处于预期的工作状态,通过--cluster-cidr 指定集群中 Pod 的 CIDR,该网段在各节点间必须通过Flannel保证路由可达;多Master节点时,可以通过配置参数--leader-elect为true来选举多台机器组成的Master 集群中的哪一个Kube-controller-manager来作为Leader。
1.3 调度器
Kube-scheduler作为调度器,负责分配调度Kubernetes中基本的管理,创建,计划的单位Pod到集群内的节点上。调度器监听Kube-apiServer把未分配节点的Pod根据调度策略为其分配节点,Pod是一组紧密关联的共享IPC、Network和UTS Namespace的容器集合,容器在Docker章节已经提到了,作为传统虚拟机的替代品,容器可以协助开发人员更容易的构建、部署和实例化应用,常被应用于微服务。调度器调度时会充分考虑诸如资源高效利用,优先级调度,指定节点调度等诸多因素,而且在调度时对于磁盘紧张的节点不会被调度,对于内存吃紧的节点未限制内存使用或者内存限制使用较高的Pod不会被调度到该节点上,甚至为了保证Pods的正常运行当其处于异常时会被调度器重新调度。
2. Node 节点组件
2.1 Kubelet
在Kubernetes集群中每个Node节点都会启动一个Kubelet进程序用以处理Master节点下发到本节点的任务——管理Pod以及其中的容器,每个Kubelet进程会在Kube-apiServer上注册节点信息,并定期向Master节点汇报本机点资源,通过集成的cAdvisor为容器用户提供对运行容器资源使用情况和性能特征的监控。除此之外Kubelet在10248端口通过两类探针来监听容器的健康状态:1)LivenessProbe探针检测到容器不健康时Kubelet将删除该容器,并根据容器的重启策略做对应处理;2)ReadinessProbe探针通过判断容器是否启动完及准备接收请求来修改Pod对应的状态,如果检测到失败,Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的IP地址的Endpoint条目[29]。
2.2 Kube-proxy
与Kubelet类似,Kubernetes集群的每个Node上都会运行一个Kube-proxy进程用作Service的透明代理和负载均衡器。具体是通过利用iptables的Nat转换实现的,也就是访问服务的各种请求都被iptable规则重定向到Kube-proxy监听的Service服务代理端口,Kube-proxy接收到访问请求后,对每一个TCP类型的服务,Kube-proxy都会在所属节点上创建一个SocketServer来负责接收请求,然后通过Round Robin(轮询调度算法,以轮询的方式依次将请求调度不同的Pod,即每次调度执行i =(i + 1)mod n,并选出第i个Pod作为目的服务终端)算法均匀负载到后端某个Pod的端口上。除此外可以通过sessionAffinity参数为ClientIP来指定会话,如果定义中设定了此选项,Kube-proxy收到请求时会先从本地查询是否存在来自该IP的affinityState所指向的后端Pod,如果存在且Session未超时则转发到此Pod,否则进行Round Robin负载均衡。
3. 网络模块
Kubernetes的网络通信可以分成三个网络,节点网络,容器网络,服务网络。节点网络很简单,由节点的局域网来提供;容器网络由类似Flannel的CNI(Container Network Interface)支持,除了Flannel官方还列举了Calico,Canal,Kube-router,Romanna,Weave Net等多种CNI可供选择;服务网络由集群内DNS支持。
3.1 Flannel
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,它的原理很简单:在集群每个节点上通过运行一个负责为更大的预配置地址空间中的每台主机分配子网的Flanneld的代理程序,通过使用Etcd存储分配的子网和网络配置及相关数据,并通过该程序修改Docker的启动参数“--bip”,也就网桥docker0使用的CIDR网络地址,以让集群中不同的节点上的Docker服务具有集群唯一的虚拟IP地址,最后通过UDP、VxLan等对底层数据包报文进行封装和转发以完成夸节点网络通信。举个例子,一个节点上的一个前端服务的一个Pod可以通过Flannel请求另一个节点上的一个后端服务的一个Pod,具体网络拓扑如图3-3所示。
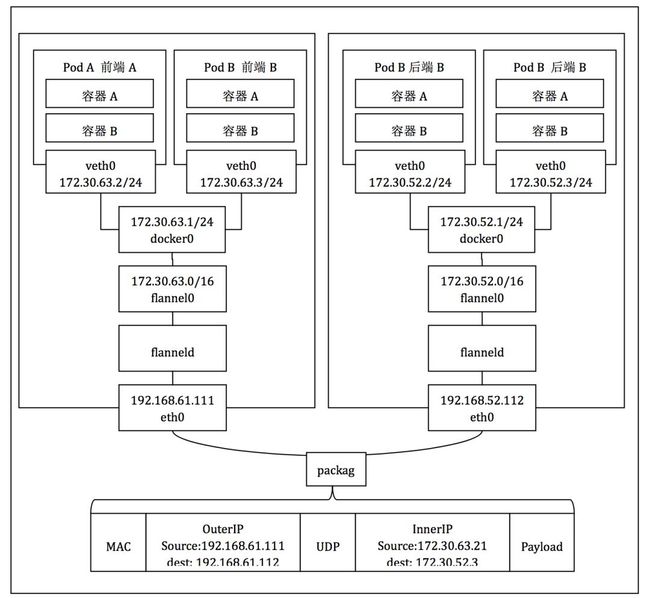
图3-3 Flannel实例网络拓扑图
3.2 DNS
在Kubernetes中,Service的引入解决了封装Pod IP及Pod的负载均衡问题,那么Service的地址如何进行服务发现呢,此时就需要DNS了。在第二章节微服务架构设计的关键技术研究的服务发现小节中也已经提到了,DNS作为我们最熟悉和简单的服务发现方式,Kubernetes就是利用了其域名和IP映射的原理,将Service的名字当做域名注册到Kube-dns中,然后在集群内部通过Service的名称就可以访问其提供的服务。
Kube-dns一般通过插件部署,会在Kubernetes集群中启动一个包含Kube-dns,Dnsmasq,Sidecar三个容器的Pod,其中Kube-dns服务于10053端口,使用树形结构在内存中保存DNS记录并通过Kubernets的 API监视Service的变化从而实时更新DNS记录,以提供给Dnsmasq查询;Dnsmasq除了DNS查询服务,还提供DNS缓存的能力,以提高查询性能;Sidecar用以DNS监控和其它两个组件的健康检查。在近期的新版本中,从Kubernetes 1.11开始,作为Kube-dns插件的替代品,CoreDNS已经实现了基于DNS的服务发现的正式发布版本。
4. 安全依赖
4.1 TLS机制
TLS(Transport Layer Security)的设计目标是构建一个安全传输层,其实在数字证书中的安全通信中,有了数字证书保障的通信已经跟TLS很接近了,TLS为了更安全,应用了更多的操作增加了加密算法的安全性。通过阅读传输层安全协议1.2版本[36]和用Wireshark工具抓包,可以对TLS的单向认证和双向认证有更详细和形象的进一步认知。
单向认证:
第一步Client Hello:客户端发起请求,以明文传输请求信息,信息包括:协议版本信息,用于后续密钥生成的客户端随机数,支持复用会话的Session ID,支持的加密套件列表,支持的压缩算法列表,支持协议与算法相关的参数及辅助信息等的扩展字段等信息。需要注意的是加密套件列表,客户端一般会把自己喜欢的加密算法放在前面。在MAC中应用版本号位63.0.3239.132的Chrome浏览器请求IP地址为的阿里云,通过Wireshark抓包数据中的加密算法列表如下:
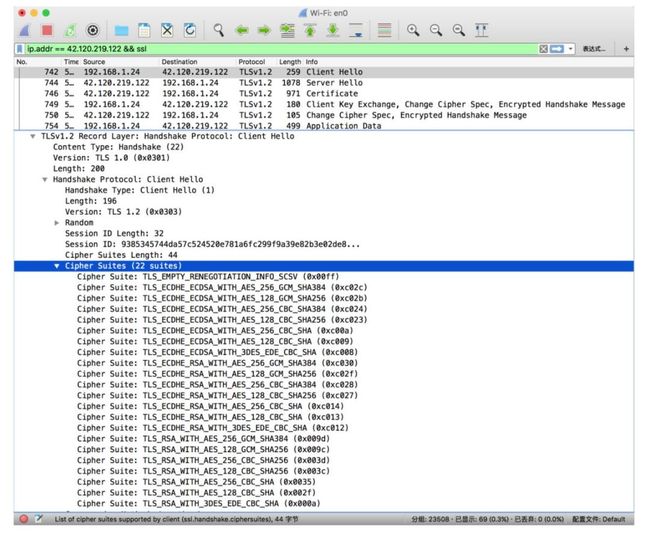
图3-5 MAC中版本号63.0.3239.132的Chrome浏览器客户端加密套件列表
如图3-5,可以看到除了特殊的用以重新协商保护请求SCSV的特殊密码套件TLS_EMPTY_RENEGOTIATION_INFO_SCSV,每种密码套件的名字里包含了四部分信息,分别是密码交换算法,数字签名认证算法,加密算法,密码衍生算法也就是hash算法,如在本次实验中,如图3-6,服务器选择的加密套件为TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,该基于TLS协议的加密套件所代表的意思是:握手期间密码通过ECDHE算法进行交换,用RSA算法进行数字签名认证,用128位GCM模式的AES对称算法加密,用SHA256进行PRF密码衍生。
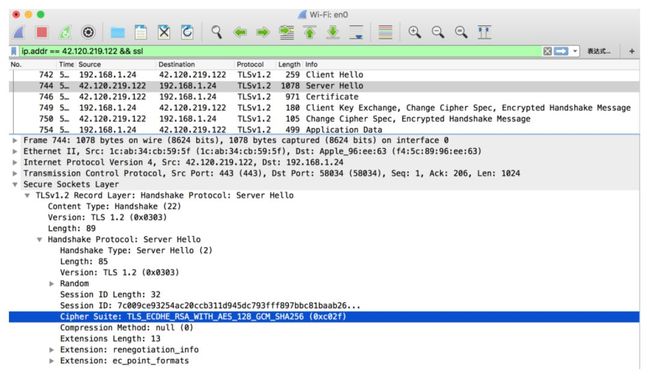
图3-6阿里云服务器Server Hello阶段返回消息
第二步Server Hello:服务端返回协商后的信息,包括协议版本,用于后续密钥协商的服务端随机数,选择的加密套件,选择的压缩算法,扩展字段等。
第三步Certificate:服务端发送自己的证书链条,用于身份验证和后续密钥交换时的加密。服务端的证书在第一个,后面的每一个证书都是前一个的签发证书。
第四步Server Key Exchange:在前面的ServerHello中,客户端和服务器已经协商好了密码套件,对于套件里面的非对称加密算法,有些需要更多的信息客户端才能生成一个可靠的密码预主密钥(Premaster Secret),比如ECDHE,而有些则不需要,比如RSA。所以这个过程不是必须的,是可选的,当然这里需要注意的是,因为客户端在利用服务端随机数和客户端随机数生成预主密钥后会利用服务端证书公钥加密发给服务端,然后服务端解密得到预主密钥再根据客户端及服务端随机数和预主密钥计算主密钥(Master Secret),所以导致RSA算法有前向不安全——私钥参与了密钥交换,安全性取决于私钥是否安全保存,也就是如果私钥泄漏,或者是利用量子计算机分解大素数或者最新的机器学习密码破解等理论可行技术进行破解得到密钥,那么就能用私钥把客户端用服务端公钥加密的密钥密文解密得到密钥明文。正是由于RSA密钥协商算法没有前向安全性,其在最新的TLS 1.3中已被废除了[37]。而ECDHE(DHE)算法属于基于椭圆曲线(简称ECC:Elliptic Curve Cryptography)的离散大对数运算困难的DH(Diffie-Hellman,是Whitefield与Martin Hellman在1976年提出了一个的密钥交换协议)类密钥交换算法,可以避免前向不安全,因为此类密钥交换算法私钥不参与密钥的协商,因为不需要传递预主密钥,而是交换DH算法需要的参数,然后各自计算预主密钥,最终计算主密钥,所以即使私钥泄漏,客户端和服务器之间加密的报文也无法被解密,而且由于ECDHE每条会话都重新计算一个密钥,故一条会话被解密后,其他会话仍然安全,这种特性也叫作完全前向保密,简称PFS(Perfect Forward Secrecy)。除此外,ECC体制相比RSA,公钥更小,性能更高,所以现在服务器一般都是应用ECDHE类密钥交换算法进行密钥交换,此步骤也从可选逐渐普遍起来。
第五步Server Hello Done:服务端通知客户端密钥协商信息发送结束,并开始等待客户端响应。
第六步Client Key Exchange:在这之前客户端首先验证服务端证书可信性,是否吊销,是否在有效期内,证书域名是否与当前域名匹配等一系列合法性,验证通过则进行下一步通信,验证失败则根据具体错误情况给出提示和操作。服务端证书验证通过后,如果是使用DH类密钥交换算法,则发给服务端可以得到相同预主密钥的DH参数,并使用证书公钥进行ServerKeyExchange消息的签名解密和校验以获取服务器端的ECDH临时公钥,生成会话所需要的预主密钥。
如果是RSA类密钥交换算法,客户端生成随机预主密钥,并且用证书公钥进行加密发给服务端,进而根据客户端随机数和服务端随机数以及预主密钥计算出主密钥。
第七步:Change Cipher Spec:客户端从现在开始发送的消息都是加密之后的。
第八步:Encrypted Handshake Message:这一步象征客户端结束消息,客户端将前面的握手消息生成校验码,再用经过协商预主密钥后计算出的主密钥及对称加密算法加密发给客服务端去解密并校验。这一步有两个目的,一是保证双方算出的主密钥相同,二是确保通信过程中的信息没有被篡改过。
第九步:Change Cipher Spec:服务端从现在开始发送的消息都是加密之后的。
第十步:Encrypted Handshake Message:和客户端的这个消息类似,服务端将前面的握手消息生成校验码,再用经过协商预主密钥后计算出的主密钥和对称加密算法加密发给客护端去解密并校验。
上述过程中全部进行完且无报错,就代表握手完成,双方都得到了相同的密码,后续数据传输就会用主密钥和协商的对称加密算法加密,从而保证通信安全。
基于RSA握手和密钥交换验证TLS/SSL握手过程时序图如图3-7所示。
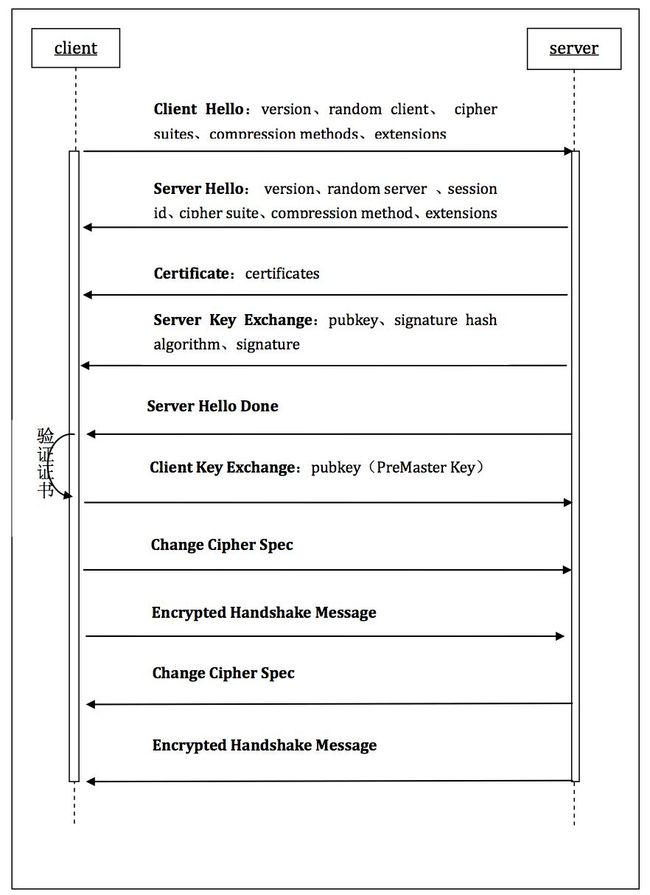
图3-7 TLS单向认证时序图
双向认证:
SSL/TLS 双向认证,也就是客户端和服务端两者之间会交换证书,区别于单向认证在握手协议,服务端在Server Hello Done之前还会发出Certificate Request以请求认证客户端身份,与之对应客户端端在Client Key Exchange之前也会发出发送自己的证书的Client Certificate消息,如无可用证书,客户端会发送一条不包含证书的Client Certificate消息,如客户端未发送任何证书,服务端将自行决定是否放弃认证客户端继续握手,或者发送一条 Fatal Handshake Failure的Alert消息然后断开连接。当然与客户端校验服务端证书类似,如果客户端的证书链的某些方面是非法的,服务器也是可以自行决定是继续握手还是终止断开。除了上面两个消息,双向认证时,客户端还会在ClientKeyExchange之后发送Certificate Verify消息,此阶段会给出使用客户端证书到这一步为止收发的所有握手消息的签名,服务器用客户端公钥解密签名,并用相同Hash算法计算校验码,以验证证书对应的私钥确实在客户端手中。整体流程见图3-8。

图3-8 TLS双向认证时序图
4.2 认证、授权、准入控制
用户可以通过kubectl命令,客户端库或REST请求访问API,Kubernetes通过一系列机制来实现集群的安全控制,普通用户和服务账户都可以被授权进行API访问,请求API时会经历认证,授权,准入控制几个阶段,如图3-9[38]所示。
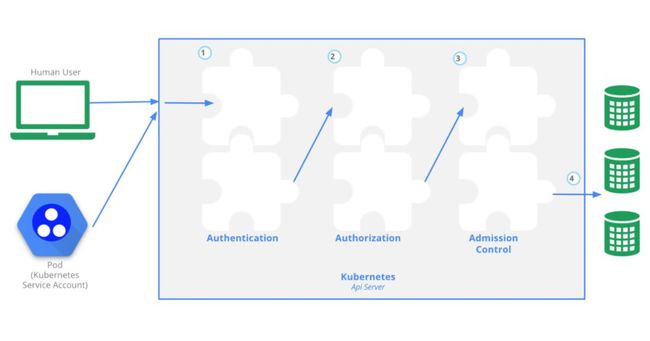
图3-9 Kubernetes 认证,授权,准入控制流程
通过图方式以达到容器隔离,最小权限原则,明确组件边界,划分用户角色及权限,允许拥有密码数据的应用在集群中安全运行等目的。
Kubernetes集群提供了很多种客户端认证方式。CA证书认证是应用比较多的方式,即通过基于CA根证书签名的双向数字证书认证。Kubectl命令行,Kubelet,Controller Manager,Scheduler都是通过CA根证书签名生成的客户端证书进行TLS双向认证的,类似用kubeadm已经生成的admin.conf,我们可以通过创建新的用户并通过kubectl config set-context配置相应上下文及集群(Cluster),用户(User),命名空间(Namespace)等参数以认证,其中Cluster包含集群地址与公钥信息,User包含用户信息和用户的证书和私钥,需要注意的是服务端获取用户信息时会通过验证证书并从证书的CN(Common name)字段获取,而不是以配置文件的明文为主,通过此方式以达到认证客户端的目的。认证通过后一般通过基于RBAC(Role Based Access,基于角色的访问控制机制)绑定创建的用户到相应的角色或新的角色之上进行新用户的授权访问。除此外Kubernetes还支持无记名令牌(Bearer Token),引导令牌,身份验证代理,HTTP基本身份验证等身份认证插件来对API请求进行身份验证。
授权作用是,决定一个用户是否有权使用Kubernetes API 做某些事情,Kubernetes 从1.6版本开始支持RBAC,从1.8版本开始进入稳定版本,并成为默认授权方式,用以替代ABAC(Attribute Based Access Control,基于属性的访问控制)。ABAC的机制是通过用户名,是否是只读请求,被访问资源类型,被访问对象所属命名空间四个基本属性来制定“访问策略对象”,比如{"user":"bob", "readonly":true, "resource":"pods", "ns":"test_namespace"}。由于ABAC在集群中比较难以管理,而且授权变更需要重启API Server,而RBAC可以通过角色和角色绑定以及集群角色和集群角色绑定很好地解决了ABAC所面临的问题。RBAC的具体是:设定一些拥有某些特定权限的角色和集群角色,通过角色绑定和集群角色绑定把角色的权限映射到用户或用户组,从而让用户或用户组继承角色在对应命名空间的角色或继承集群角色在整个集群中的权限。目前RBAC 被Kubernetes 深度集成并用它给系统组件进行授权。除了ABAC和RBAC,还可以通过配置参数AlwaysDeny拒绝所有的请求或AlwaysAllow接收所有的请求进行一些安全防护或测试等需求。
准入控制是用以在认证和授权后对请求做进一步的验证。准入控制支持同时开启多个插件,依次被调用,而且只有全部插件都通过才可以进入系统。以1.8.0版本为例,常见的准入控制插件有Initializers(可以用来给资源执行策略或者配置默认选项),NamespaceLifecycle(保证处于终止状态的命名空间不再接收新的对象创建请求,并拒绝不存在的命名空间其请求),LimitRanger(为Pod设置默认资源请求和限制),ServiceAccount(自动创建默认ServiceAccount,并保证Pod引用的ServiceAccount已经存在),NodeRestriction(限制Kubelet可访问的资源),ResourceQuota(限制Pod的请求不会超过配额)等。
5. 附件模块
5.1 EFK日志系统
日志系统很多情况下不只是微服务架构需要这种组件,在很多大型网站及高可用架构中都是不可或缺的一部分,因为日志系统扮演了很重要的统计,监控,预警等功能,当然鉴于微服务架构中网络更复杂,日志更多样,日志系统就显得尤为重要了。介绍日志系统前首先要明确日志是什么?日志就是应用程序产生的,遵循一定的格式通常是以时间戳开头的文本数据,常见的有系统日志,访问日志,安全日志,应用日志等,不同的日志存储在系统的不同地方。
什么是日志系统?简单说就是搜集各个实例中每时每刻产生的分散的各种日志进行集中管理并提供数据检索功能的系统,一般在普通检索之上又会根据一系列数据提供诊断或分析的功能,比如了解服务器状态,统计PV、UV和CPU,内存,带宽等数据。
EFK分别是Elasticsearch,Fluentd,Kibana三个组件首字母的组合,分别用来存储日志,收集日志,展示日志。Elasticsearch是一个基于Lucene 开发的实时分布式搜索分析引擎,可以让使用者以前所未有的速度和规模去探索数据,常被用作全文检索,结构化搜索,日志分析,我们熟悉的GitHub就用Elasticsearch对1300亿行代码进行查询[39]。Fluentd使用保留灵活模式的JSON进行统一日志记录,可以对日志数据进行收集,过滤,缓冲以及在多个源和目的地(统一日志记录层)上输出日志,其扩展性强,资源占用低,可靠性高,是一个强大的开源数据处理器[40]。而且相比传统的Logstash日志收集工具Fluentd的日志收集功能对容器支持的十分完备,容器中的日志可以通过Docker日志驱动直接发到作为日志采集服务的Fluentd,这也是在容器时代ELK(Elasticsearch,Logstash,Kibana)被EFK取代的原因。Kibana是一个开源的分析和可视化平台,旨在更方便的查看和展示Elasticsearch中存储的数据,它可以使用各种图表,表格轻松执行高级数据分析,而且它的基于浏览器的界面使您能够快速创建和共享动态仪表板,实时显示数据变化[41]。
5.2 Heapster
Heapster是容器集群监控和性能分析工具,它将每一个Node上的cAdvisor的数据进行汇总,然后导到数据存储后端InfluxDB中,再配合Grafana的前端进行多样化的数据可视化。
InfluxDB是一款开源的高性能的分布式时序数据库,该数据库主要用于存储涉及大量时间戳的任何用例的数据存储,他的主要特征是支持无结构——可以是任意数量的列,支持自动过期并从系统中删除不需要的数据,支持类似SQL的语法和HTTP,而且有简洁方便的WEB界面[42]。
Grafana适用于所有指标的分析平台,可以查询,可视化,提醒并了解指标,非常多样化的图表和交互让人眼前一亮,能够很好的进行数据驱动。
5.3 Dashboard
在用附件的方式安装Dashboard后,访问Dashboard最简单的方式是把Cluster-Admin这个集群角色和Kubernetes-Dashboard这个服务账户进行角色绑定完成集群管理员权限授权到Kubernetes-Dashboard上,这样Kubernetes-Dashboard就拥有了集群管理员权限,可以访问任何资源,当然这样做是不安全的。更安全的做法是创建一个serviceaccount类型的用户并授予cluster-admin集群角色权限,然后可以通过这个拥有集群管理员权限的用户的Token访问Kubernetes,如图3-10创建Admin用户并将其绑定集群管理员权限的角色使其拥有集群管理员权限然后通过kubectl -n kube-system get secret|grep admin-token获取Token值复制到如图3-11的Dashboard登录页面的Token位置登录即可。
当然更安全的方式是在创建上述Token的基础上配置类似kubectl的kubeconfig用相关证书的认证增强安全性(kubeconfig比kubectl命令行依赖的kubecofig多了token字段)。
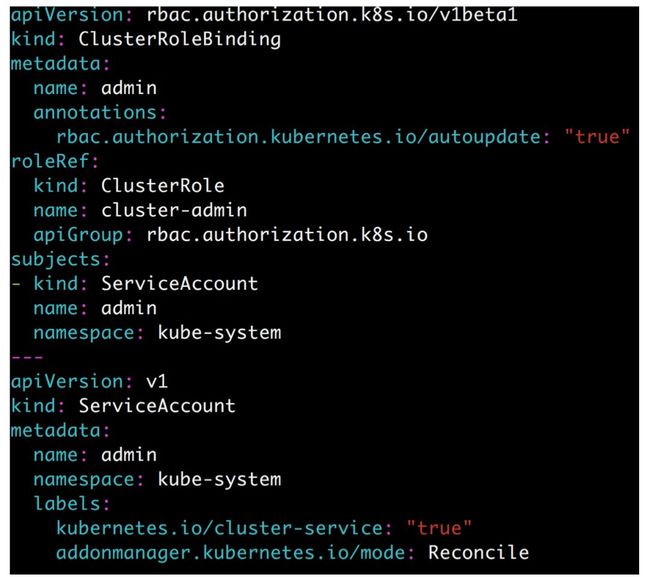
图3-10创建admin服务用户并绑定集群角色cluster-admin

图3-11 Kubernetes Dashboard 登录页面
本文论述了微服务研究的背景和意义,主要调研了传统架构的发展以及存在的问题和微服务架构的由来,然后针对微服务架构的设计原则、容器技术、服务发现、通信机制、持续集成等方面进行了分析与研究,并简单讲述了谷歌Kubernetes的相关组件和原理。
系列二依据系列一中讲述的相关技术,进行了业务原理分析和建模,然后一步步实现了基于机器学习的密码强度评测服务,搭建相关环境并部署编排服务和进行了相关验证,最后对微服务架构设计进行了总结和展望,并简单概述了后续系列的工作。系列二将于后续发布,敬请关注哦!
参考文献
[1] Reenskaug T M H. Thing-model-view-editor: an example from a planning system[C]// Xerox PARC technical note. 1979.
[2] W. Roy Schulte, Yefim V. Natis. "Service Oriented" Architectures, Part 1[J]. 1996.
[3] Rademacher F, Sachweh S, Zündorf A. Differences between Model-Driven Development of Service-Oriented and Microservice Architecture[C]// IEEE International Conference on Software Architecture Workshops. IEEE, 2017:38-45.
[4] Newman S. Building Microservices[M]. Loukides and B. MacDonald, Eds.O'Reilly Media, Inc. 2015
[5] James Lewis.Micro services: Java, the Unix Way. 33rd Degree Conference . 2012.3
[6] Martin Fowler.Microservices[EB/OL]. https://martinfowler.com/articles/microservices.html, 2014.3
[7] RobertC.Martin, MicahMartin, 马丁. 敏捷软件开发:原则、模式与实践[M]. 人民邮电出版社, 2013.
[8] Eric Evans, Domain-Driven Design:Tackling Complexcity in the Heart of Software[M], Addison-Wesley Professional, 2003.08.30
[9] Docker overview[EB/OL], https://docs.docker.com/engine/docker-overview/#the-underlying-technology.
[10] Maureen O'Gara. Ben Golub, Who Sold Gluster to Red Hat, Now Running dotCloud. SYS-CON Media. 2013.07.26
[11] 杨保华, 戴王剑, 曹亚仑. Docker技术入门与实战[M]. 机械工业出版社, 2015.
[12] Sam Newman, Nitesh Kant, Jeff Lindsay, Eberhard Wolff,6 questions TO 4 expertsonserivicediscovery [EB/OL], https://highops.com/insights/service-discovery-6-questions-to-4-experts/
[13] 孙健波,从应用场景到实现原理的全方位解读[EB/OL] http://www.infoq.com/cn/articles/etcd-interpretation-application-scenario-implement-principle
[14] corres,Distributed reliable key-value store for the most critical data of a distributed system[EB/OL] ,https://coreos.com/etcd/.
[15] Lamport L, Reed B C, Junqueira F P, et al. In Search of an Understandable Consensus Algorithm[J]. Draft of October, 2014.
[16] Fielding R T. Architectural styles and the design of network-based software architectures[M]. University of California, Irvine, 2000.
[17] Webber J, Parastatidis S, Robinson I. REST in Practice - Hypermedia and Systems Architecture.[M]. DBLP, 2010.
[18] 黄晓军, 张静, 张凯.Apache Thrift - 可伸缩的跨语言服务开发框架[EB/OL]https://www.ibm.com/developerworks/cn/java/j-lo-apachethrift/,2016.1.26.
[19] developers.google.com,What are protocol buffers[EB/OL],https://developers.google.com/protocol-buffers/docs/overview.
[20] eishay,Benchmark comparing serialization libraries on the JVM [EB/OL], https://github.com/eishay/jvm-serializers/wiki.
[21] grpc.io, What is gRPC[EB/OL], https://grpc.io/docs/guides/
[22] Jay Kreps, Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines)[EB/OL],https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
[23] Sharma A. Apache Kafka: Next Generation Distributed Messaging System[J].
[24] Apache Kafka Source Code[EB/OL], https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/admin/AdminUtils.scala
[25] Kafka Replication[EB/OL], https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Replication
[26] JezHumble, DavidFarley. 持续交付[M]. 人民邮电出版社, 2011.
[27] Duvall P, Matyas S M, Glover A. Continuous Integration: Improving Software Quality and Reducing Risk (The Addison-Wesley Signature Series)[M]. Addison-Wesley Professional, 2007.
[28] Jenkins User Documentation. https://jenkins.io/doc/
[29] 龚正,吴治辉,王伟,崔秀龙,闫健勇. Kubernetes权威指南:从Docker到Kubernetes实践全接触第二版[M]. 电子工业出版社, 2016.
[30] Schwarzkopf M, Konwinski A, Abd-El-Malek M, et al. Omega:flexible, scalable schedulers for large compute clusters[C]// ACM European Conference on Computer Systems. ACM, 2013:351-364.
[31] Usman Ismail ,Kubernetes, Mesos, and Swarm: Comparing the Rancher Orchestration Engine Options[EB/OL],http://rancher.com/comparing-rancher-orchestration-engine-options/
[32] Kubernetes Design and Architecture[EB/OL], https://github.com/kubernetes/community/blob/master/contributors/design-proposals/architecture/architecture.md
[33] Boettiger C. An introduction to Docker for reproducible research[J]. Acm Sigops Operating Systems Review, 2014, 49(1):71-79.
[34] Merkel D. Docker: lightweight Linux containers for consistent development and deployment[J]. 2014, 2014(239).
[35] Bernstein D. Containers and Cloud: From LXC to Docker to Kubernetes[J]. IEEE Cloud Computing, 2015, 1(3):81-84.
[36] Dierks T. The transport layer security (TLS) protocol version 1.2[J]. Heise Zeitschriften Verlag, 2008.
[37] Cremers C , Horvat M , Hoyland J , et al. [ACM Press the 2017 ACM SIGSAC Conference - Dallas, Texas, USA (2017.10.30-2017.11.03)] Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, - CCS \"17 - A Comprehensive Symbolic Analysis of TLS 1.3[C]// Acm Sigsac Conference. ACM, 2017:1773-1788.
[38] kubernetes.io, Controlling Access to the Kubernetes API[EB/OL]
https://kubernetes.io/docs/reference/access-authn-authz/controlling-access
[39] Gormley C, Tong Z. Elasticsearch: The Definitive Guide[M]. O'Reilly Media, Inc. 2015.
[40] fluentd.org,What is Fluentd[EB/OL],https://www.fluentd.org/architecture.
[41] elastic.co ,Kibana UserGuide[EB/OL], https://www.elastic.co/guide/en/kibana/current/introduction.html
[42] InfluxDB is the Time Series Database in the TICK Stack[EB/OL],https://www.influxdata.com/time-series-platform/influxdb/