论文浅尝 | 提取计数量词丰富知识库
OpenKG 祝各位读者新年快乐!

论文标题:Enriching Knowledge Bases with Counting Quantifiers
论文链接:https://link.springer.com/content/pdf/10.1007%2F978-3-030-00671-6_11.pdf
发表会议:ISWC 2018
论文源码:https://github.com/paramitamirza/CINEX
摘要
信息抽取通常关注于抽取可辨识实体之间的关系,例如 <Monterey, locatedIn,California>。但是,除了说明具体实体之间的关系,文本中也经常含有计数信息,表明与某个实体有特定关系的对象的数量,而未提及具体对象本身,例如“California is divided into 58counties”。这种计数量词可用于诸如查询应答,知识库管理等任务,但被先前的工作忽略了。本文开发了第一个完整的从文本中提取计数信息的系统 CINEX,将知识库中的事实计数作为训练种子,采用远程监督的方法抽取文本中的计数信息。实验表明,在人工评估的 5 个关系上,CINEX 的平均抽取精度达到了 60%。在大规模实验上,对于 Wikidata 的 110 种不同关系,CINEX 能够断言 250 万事实的存在,比这些关系现有的 Wikidata 事实多 28%。
概念
本文用SPO形式的计数语句(Counting Statement)来描述知识库中的计数信息,主要关注对于一个给定的SP对,参数O的数量。计数语句的形式化表示为:,其中,S 是 subject,P 是 predicate,n 是一个自然数(包括 0)。例如,语句 “President Garfield has 7 children” 将表示成
![]()
方法
CINEX的目标是解决文本中计数量词的抽取问题,问题定义如下:

CINEX 将知识库中已有的事实计数作为种子,采用远程监督的方法抽取文本中的技术信息。远程监督作为知识库信息抽取的主要方法,也是解决本文问题的一种相当自然的方法。不过,用远程监督解决计数信息抽取,需要解决以下几点挑战:
种子质量:与通常意义下的 SPO 事实抽取不同,本场景下知识库的不完备不仅会导致训练种子数量的减少,还会导致系统地低估实际事实的数量。例如:知识库只知道特朗普的 3 个孩子,而实际上特朗普有5个,这会导致系统奖励“owns three golf resorts”这样的模式,而惩罚“his five children”。
数据的稀疏性:对于很多关系,文本表达计数信息的方式相当稀疏且高度倾斜。例如,一般人的children很少被提及;对于音乐家来说,赢得的第一个格莱美奖通常比之后的获奖更多被提及,因此对“他/她的第一个奖项”的模式会被给予过度的重视。还有,音乐乐队的成员数量通常约为 4,这使得很难学习到乐队成员数量非常大或非常小的模式。
语言多样性:计数信息可以用各种语言形式表达,如冠词(“has a child”),基数词(“has five children”),序数词(“her third husband”),表数量的名词短语(‘twins’,‘quartet’),表存在与否的副词(‘never’,‘without’)。
CINEX针对上述挑战给出了对应的解决方法:对于挑战 1,CINEX 通过将数量的匹配条件放宽到比知识库事实计数更高的值,同时将训练种子限制于知识库中信息更完备的流行实体来处理。对于挑战 2,CINEX 使用信息熵来度量 numbers,过滤掉不提供信息的 numbers。对于挑战3,CINEX 通过仔细整合中间结果来处理。Fig.2 给出了 CINEX 系统的框架,系统将整体任务分为两个阶段:
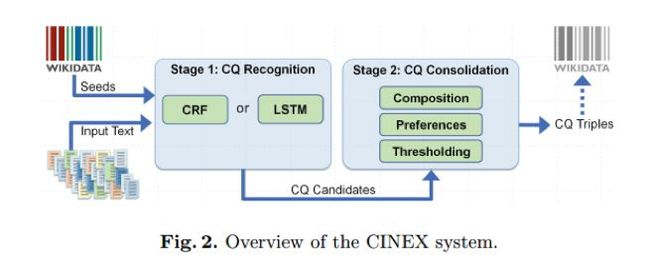
(1)计数量词的识别
CINEX将其建模为序列标注问题,对每一个句子操作并且针对每一个谓词P单独学习。首先通过检测文本中指示计数信息的术语(基数,序数和数值项等)预处理输入的句子,再用CRF++模型以及bidirectional LSTM-CRF模型为每个感兴趣的谓词P学习一个序列标注模型,用于计数量词的识别。
(2)计数量词的合并
将第一阶段识别出的多个表示计数或者组合信息的中间结果,合并为对象数量的单个预测。整合算法如下:
对需要组合的计数信息求和,可信度得分设为被组合信息中最高的值。
选择每一种计数信息的预测结果。对于基数词和数值项,选择高于设定阈值的计数信息中可信度得分最高的;对于序数词,不论可信度得分如何,总是选择可信度得分最高的。
根据计数信息类型排序,根据如下顺序选择最终结果。
![]()
实例
(1)计数量词的识别
给定句子“Jolie brought her twins , one daughter and three adoptedchildren to the gala”,计数量词识别阶段预处理以及序列标注的结果如下:
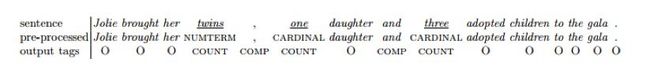
(2)计数量词的合并
给定SP对<AngelinaJolie, hasChild>,计数量词的识别结果如下:

整合算法第1步会合并句子中的计数信息0.3和0.5,将其相加得到0.5,句子中的计数信息0.1和0.2将相加得到0.2。第2步0.5被选为可信度得分最高的基数词,0.8被选为可信度得分最高的数值项,0.5被选为排序最高的序数词。第3步,根据排序偏好以及设置的可信度阈值,基数词0.5或0.8将被作为最终预测结果。
实验
(1)数据集:Wikidata(知识库),Wikipedia(文本)
(2)实验结果
从Table 2. 可知,计数量词的识别基于特征的CRF模型效果最好,神经网络模型容易过拟合。同时,CINEX-CRF也是在整合和端到端任务中识别计数信息性能最佳的系统。

对于各种类型的计数术语,由Table 4. 的实验结果可知,考虑数值项和冠词有利于改善覆盖率,考虑组合计数信息以及除基数词之外的其它类型术语,有利于提高准确性和覆盖率。
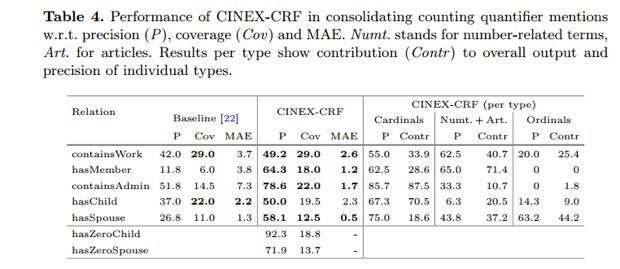
对于Wikidata的110种关系,CINEX抽取了851K计数量词事实,断言了250万事实的存在,比这些关系现有的Wikidata事实多了28.3%。
论文笔记整理:曹二梅,南京大学硕士生,研究方向为知识图谱、知识融合。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。