Spark RDD计算机制剖析
通用的分布式计算框架,为了降低学习和使用门槛,便于用户直观理解,一般会尽量简化上层API抽象(姑且定义为逻辑层),RDD之于Spark就是最核心的逻辑层抽象。然而,当你深入框架内部Runtime实现(对应来说就是物理层),通常会进入另一个世界,透过现象看本质,豁然开朗。对Spark RDD来说莫不如此,下面让我们来看看它在物理层的另一面。
首先,我们来回顾下RDD在逻辑层的表象,无非这几点,了解Spark的人都很清楚:
- RDD字面理解Resilient Distributed Dataset,指的是利用分布式内存资源来存储的数据集
- RDD是immutable的,每一次transform都会生成新的RDD
- 一个job的所有RDD,会根据是否需要做shuffle,被划分到不同的stage
- RDD计算是lazy方式,只有action才会触发job产生,transform只会记录元数据与依赖关系
- 如果一个RDD计算出错,会根据依赖关系从上游RDD经过重新计算来自动恢复
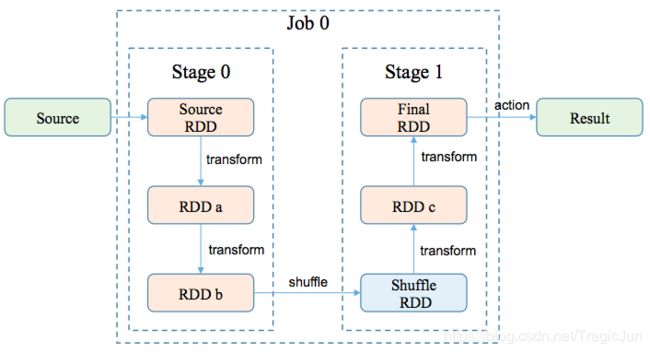
然而,如果你仔细思考下逻辑层视角的理解,很容易会发出以下两点疑问:
- 既然每次transform都需要生成新的RDD,那么一个job中很可能会产生大量的RDD。而如果每个RDD都需要占有内存资源,是不是很快就会吃掉所有内存?
- 一个stage内部的多个RDD计算是串行的吗,如果是,岂不是要多次的遍历原始或中间RDD的数据,导致计算资源开销太大?
要解答以上抛出的两点疑问,停留在逻辑层是不够了,需要进入物理层来理解RDD内部计算机制。这里从两个角度来剖析——第一,RDD计算是怎样调度起来的;第二,RDD计算是怎样执行的。
RDD计算调度
上文提到过,RDD计算是lazy方式,只有action才会触发计算job产生。实际上,所有的RDD.action最终都会指向DAGScheduler.runJob()。作为job调度的入口,它的方法签名为:
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
...): Unit =
这里我们关心的是前两个参数:rdd为触发action的Final RDD;func为作用在Final RDD上的计算函数,执行func(Final RDD)就产生了最终结果。
runJob()会通过event-driven的方式触发handleJobSubmitted()来真正处理调度流程,其主要工作有两点:
- 调用createResultStage()构建Final Stage,实际上它还会递归构建上游整个的stage链
- 调用submitStage()提交Final Stage,实际上它会递归检查上游stage是否已经提交:如果没有提交,则递归调用提交上游stage;如果已经提交,则为该stage生成task并提交。
小结:不管是构建还是提交,虽然入口触发都是Final Stage,但通过递归的反向遍历手法,实际效果是上游stage优先于下游被提交了。
接下来的重点为stage构建与提交task(Final RDD有多少partition就会有多少个task),核心函数为submitMissingTasks(),其主要工作有三点:
- 根据stage类型构建task:如果是FinalStage,则构建ResultTask;如果是ShuffleMapStage,则构建ShuffleMapTask
- 调用TaskScheduler.submitTasks()提交所有构建的task
- 调用submitWaitingChildStages()提交该stage下游的stage
至此,RDD计算被正式调度起来了。
RDD计算执行
在计算调度描述中有提到,ShuffleMapTask和ResultTask是计算的真正执行者,只有FinalStage才对应ResultTask,否则都是ShuffleMapTask。这两个task具体怎么计算RDD呢?我们可以去看它们的runTask()实现,抽取出核心点其实就那么几行代码:
ShuffleMapTask
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
ResultTask
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](...)
func(context, rdd.iterator(partition, context))
以上代码很好理解:ShuffleMapTask将RDD计算结果写入shuffle系统,而ResultTask则是将计算结果作为参数输入给action对应的计算函数,最终得出job返回的结果。这里的重点是rdd.iterator(),可以看到它才是触发RDD计算的真正入口。
其实,RDD.iterator()只是RDD.compute()的包装,会它判断RDD是否做来cache或checkpoint,如果有其一就无需重复计算,直接读取即可。为了简化讨论,这里我们假定RDD都没有cache或checkpoint。
我们来看RDD.iterator()和RDD.compute()的方法签名:
final def iterator(split: Partition, context: TaskContext): Iterator[T]
def compute(split: Partition, context: TaskContext): Iterator[T]
有没有注意到,它的返回类型是iterator,而不是collection类型。如果对scala比较熟悉,可能应该知道怎么回事了。我们最后来看两段代码:
MapPartitionsRDD.compute()
注意到firstParent.iterator()作为参数传递给计算函数f,而f是由MapPartitionsRDD构造函数传入的。
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
RDD.map()和RDD.filter()
都是实例化一个MapPartitionsRDD,给的计算函数f输出分别是iter.map()和iter.filter()。
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}
结合以上代码,我们可以得出,逻辑层定义的rdd.filter().map(),在物理层执行时是iter.filter().map()这样的iterator级联,其中iter是source RDD.compute()返回的。在scala中,iterator级联是不产生intermediate collection的,最终触发计算时也只需要遍历一次原始collection。
最后,根据以上分析,可以给出下面结论(前提是RDD没有做任何cache):
RDD计算不产生collection,只输出iterator,RDD链计算实际上是以iterator级联的形式来实现的,RDD数据不需要被完整存储,也不需要多次遍历原始或中间RDD数据。只有ShuffleMapTask对应的shuffle子系统会存储一份完整的RDD数据。