Spark Streaming 初见
本文内容是对 Spark Streaming 官方文档的总结,用一个简单的例子来入门 Spark Streaming。
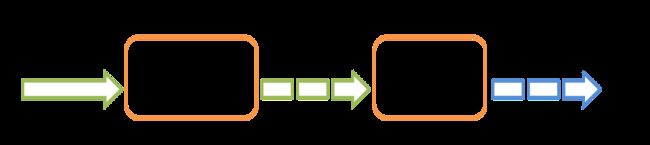
Spark Streaming 是用来处理实时流数据的,所以必然有一个输入和一个输出:

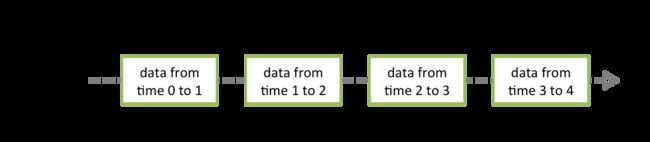
Spark Streaming 的内部实现其实还是 Spark core,将接收到的实时流数据分成一个一个很小的批数据进行处理:
Spark Streaming 基本的数据结构是 DStream(discretized stream),这是一个连续的数据流,其底层是 RDD 的集合。
先上个栗子
在我们正式讲解 Spark Streaming 的细节之前,先通过一个简单的栗子来明白它到底是怎么工作的。我们要计算接收到的文本中相同单词出现的次数,数据源是一个 TCP 端口,Spark Streaming 通过监听这个端口来获取数据。
首先我们可以使用 Netcat 创建这个 TCP 数据源,这是大部分类 Unix 系统中都会有的一个小工具,在终端直接输入下面的命令:
$ nc -lk 9999然后开始写 Spark Streaming 程序,引入下面 SBT:
"org.apache.spark" %% "spark-streaming" % 2.3.1,第一步我们需要创建一个 StreamingContext,它是所有 streaming 程序的入口。这里我们创建了一个名称是 NetworkWordCount,有两个运行线程(一个用于启动监听,一个用于数据处理),批次间隔是 1 秒的本地 StreamingContext。
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))然后我们可以从 TCP 源创建一个 DStream,指定其主机名和端口号:
// Create a DStream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)通过空格把文本切割成多个单词:
// Split each line into words
val words = lines.flatMap(_.split(" "))之后我们对单词计数并打印出来:
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()上面就是实时流转换的流程,只有启动以后这些转换才会实际执行:
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminateOK,上面就是 Streaming 处理的代码,现在我们执行这个程序,然后在 TCP 数据源终端那输入一些内容:
# TERMINAL 1:
# Running Netcat
$ nc -lk 9999
哈哈 哈哈 哈哈 呵呵 呵呵 嘿嘿程序输出结果如下:
(哈哈,3)
(呵呵,2)
(嘿嘿,1)以上程序在本地 IntelliJ IDEA 就可以运行,源码见 Spark Streaming Word Count
基本概念
SBT
想要写自己的 Spark Streaming 程序,首先将下面内容加入 SBT:
"org.apache.spark" %% "spark-streaming_2.11" % "2.3.1"如果还需要从 Kafka、Flume 或者 AWS Kinesis 中接收数据,还需要加入与之相关的包,例如对于 Kinesis,需要在 SBT 中加入以下内容:
"org.apache.spark" %% "spark-streaming-kinesis-asl_2.11" % "2.3.1"初始化 StreamingContext
可以通过 SparkConf 创建一个 StreamingContext 对象:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))appName 是显示在集群上的应用名称,master 是 Spark、Mesos 或 YARN 集群的 URL,或者是 local[*]。当运行在集群上时,我们实际上很少把 master 硬编码到程序代码中,而是在执行 spark-submit 把它作为一个参数输入。但是在本地或者单元测试时,我们可以写入 local[*] 使 Spark Streaming 运行在本地。注意创建 StreamingContext 其内部还是创建了一个 SparkContext,我们可以通过 ssc.sparkContext 访问到。
我们也可以通过一个已存在的 SparkContext 对象创建 StreamingContext 对象:
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))当定义好 context 以后,还需要进行下面的步骤:
- 通过创建输入
DStreams来定义数据源 - 定义一系列 Streaming 的转化和行动操作
- 使用
streamingContext.start()开始接收和处理数据 - 使用
streamingContext.awaitTermination()等待进程的停止(人为或者某些异常导致) - 进程也可以通过
streamingContext.stop()人为停止
注意以下几点:
- 一旦 context 开始以后,就不能建立或者添加新的 streaming 操作了
- context 停止以后不能再重启
- 同一时间一个 JVM 内只能有一个活跃的 StreamingContext
streamingContext.stop()同时也会把 SparkContext 停止,可以通过设置该方法中参数stopSparkContext为 false 来避免- SparkContext 可以用来多次创建 StreamingContext,只要保证在新的 StreamingContext 建立之前停掉旧的
离散流(DStreams)
DStream 是 Spark Streaming 的基本抽象,它代表连续的数据流,不管是源数据还是经过转换处理后的数据。本质上它是一系列 RDD,每一个 DStream 都是确定间隔大小的 RDD 集合,如下图所示。
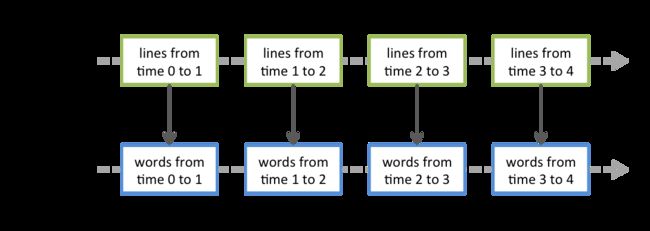
Streaming 做的转换操作也都是基于 RDD:
输入流和接收器
当在本地执行 Spark Streaming 程序时,不要使用 local 或者 local[1] 作为 master 的 URL,因为这样就只有一个线程。但是一个 Streaming 程序可能需要两个线程,一个用于接收输入流,一个用于处理数据。当然有接收器的才需要相应的线程来支持,如 Kafka、Flume 等,对于 HDFS 就不需要接收器,也就不需要另开线程。
对于文件系统(HDFS,S3 等),可以使用如下方式创建 DStream:
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)对于简单的文本文件,下面这种方式更加简单:
streamingContext.textFileStream(dataDirectory)那么 Spark Streaming 如何监控文件系统中的目录呢?
可以直接监控一个目录,例如 hdfs://namenode:8040/logs/,这个目录下的所有文件(注意不能包含多级目录)都能被处理。也可以使用正则匹配如 hdfs://namenode:8040/logs/2016-*,注意这个正则匹配是指符合这个规则的目录而不是文件,例如有个目录是 hdfs://namenode:8040/logs/2016-08-12,那么这个目录下的所有文件都能被监控到。了解了这个规则以后,我们还可以通过改目录名的方式把其下面的文件加入到监控中。而且注意所有的文件都应该保持相同的数据格式,监控一个文件是监控它的修改时间而非创建时间,只有文件的修改时间在 Spark Streaming 执行的时间窗口之内,这个文件才会被处理,所以我们可以通过调用 FileSystem.setTimes() 来人为设置文件的修改时间从而使其可以被处理。
不过 Spark Streaming 直接监控对象存储系统中的目录还是有一些坑,可能会造成丢数据的问题,原因这里给出了详解:using-object-stores-as-a-source-of-data,所以一般还是使用 Flume 监控目录比较好。
除了上面所说的文件流创建 DStream, 还可以通过接收器接收来自 Kafka、Flume 或 Kinesis 这些第三方组件的数据,由于这些组件各自有其对应的版本,所以可能会有版本依赖冲突的问题,Spark 就把这部分拆分出来作为专门的 Jar 包,所以对应到不同的第三方组件,我们需要引入不同的包。
总结
本文是 Spark Streaming 的入门篇,通过一个简单的例子讲解了如何写 streaming 应用,并且介绍了 streaming 基本的数据结构 DStream,后面会介绍更多详细内容。