HDFS离线分析FsImage元数据
概观
HDFS是Hadoop的一部分,它具有下载当前名称节点快照的命令。我们可以通过Spark加载图像或对其进行数据摄取,以使其进入Hive以分析数据并验证它如何使用HDFS。
HDFS文件系统元数据存储在名为“FsImage”的文件中。我们在此快照中包含:
- 整个文件系统命名空间。
- 地图,块和文件复制。
- 配额,ACLS等属性
我必须解决的问题如下:
- 运行该命令以下载映像并生成XML文件。
- 实现Spark作业以处理并将数据保存在Hive表中。
- 使用Hive SQL分析一些数据并使用GnuPlot绘制数据。
1.生成HDFS FsImage
FSImage可以生成CSV,XML或分布式格式的图像,在我的情况下,我必须评估块和ACLS ; 因为它们是数组类型的字段,所以它们不能以CSV格式工作。你可以在这里看到更多细节:
- Hadoop Hdfs图像查看器
要生成图像,请检查名称节点中的位置:
hdfs getconf -confKey dfs.namenode.name.dir
现在让我们下载图片/tmp。就我而言,正在分析的文件大小为35 GB:
hdfs dfsadmin -fetchImage / tmp
现在需要将其转换为可读格式,在本例中为XML:
hdfs oiv -p XML -i / tmp / fsimage_0000000000000103292 -o fsimage.xml
1.1将文件加载到Spark中并将其保存到Hive表中
我使用Databricks库进行XML,并且它很容易加载,因为它已经将数据转换为数据框。您可以在此处查看所有详细信息:https://github.com/databricks/spark-xml。
我的Hive表的结构如下:
使用分析;
CREATE EXTERNAL TABLE如果不是 EXISTS分析.fsimage_hdfs
(
id string COMMENT '唯一标识号。' ,
type string COMMENT '数据类型:目录或文件,链接等......',
name string COMMENT '目录或文件的名称..',
复制字符串COMMENT '复制号。' ,
mtime string评论'修改日期'。,
atime string评论'上次访问的日期'。,
preferredblocksize string COMMENT '使用的块的大小。' ,
权限字符串COMMENT '使用的权限,用户,组(Unix权限)。' ,
acls string COMMENT '访问权限:用户和组。' ,
阻止字符串COMMENT '大小块',
storagepolicyid string COMMENT '访问策略的ID号。' ,
nsquota string COMMENT '配额名称,如果-1被禁用。' ,
dsquota string COMMENT '空间可用并评估用户/组,如果-1被禁用。' ,
fileunderconstruction string COMMENT '文件或目录仍处于构建/复制状态。' ,
path string COMMENT '文件或目录的路径。'
)
PARTITIONED BY(odate string,cluster string)
行格式SERDE'parquet.hive.serde.ParquetHiveSerDe '
作为 INPUTFORMAT 存储'parquet.hive.DeprecatedParquetInputFormat'
OUTPUTFORMAT'palam.hive.DeprecatedParquetOutputFormat '
LOCATION '/ powerhorse / bicudo / analyze / fsimage_hdfs' ;
在这种情况下,由于还有其他要分析的集群,因此使用ISO标准摄取日和集群名称创建了一个分区。
使用spark-xml库,ut非常容易在文件中创建解析器,读取,修改和保存数据。这是一个加载XML数据的简单示例:
val df = sparkSession。sqlContext。读
。格式(“com.databricks.spark.xml”)
。选项(“rowTag”,“inode”)
。选项(“nullValue”,“”)
。load(pathFsImage)
我还创建了一些示例代码,您可以运行并使用您的映像进行测试:https://github.com/edersoncorbari/scala-lab
1.2使用GnuPlot分析信息和绘图
在这些分析中,我使用SQL和GnuPlot来查看数据。其他一些有趣的工具是:
- https://github.com/paypal/NNAnalytics
- https://github.com/vegas-viz/Vegas
继续我们的工作批量数据,我们现在可以做一些分析。使用群集中最常用的复制值生成直方图:
SELECT cast(hist .x AS int)AS x,
cast(hist .y AS bigint)y
从
(SELECT histogram_numeric(cast(复制AS DOUBLE),40)AS T0
FROM analyze .fsimage_hdfs
WHERE dataingestao = '2019-01-27'
AND CLUSTER = 'SEMANTIX_NORTH'
AND preferredblocksize <> '')
T1 LATERAL VIEW爆炸(T0)explosion_table AS hist;
您可以使用GnuPlot制作几种类型的图形,请在此处查看更多示例:GnuPlot演示。您需要在直方图中复制输出并将其放在示例文件replication.dat中:
Replication_XReplication_Y
129
13
277975
212602
247204
2139973
217612
224402
3170164
37461229
311038655
31443494
31910188
109267
106492
101719
101207
101318
现在复制下面的代码并运行:
#!的/ usr / bin中/ gnuplot的
重启
明确
设置数据文件分隔符“\ t”
设置终端PNG大小1024,768
设置输出“histogram-replication.png”
设置标题“复制集群 - Semantix North”
设置 xlabel “(X)”
设置 ylabel “(Y)”
设置键顶部左水平autotitle columnhead外
情节'复制.d'你1:2 w冲动lw 10
生成的数据如下所示:

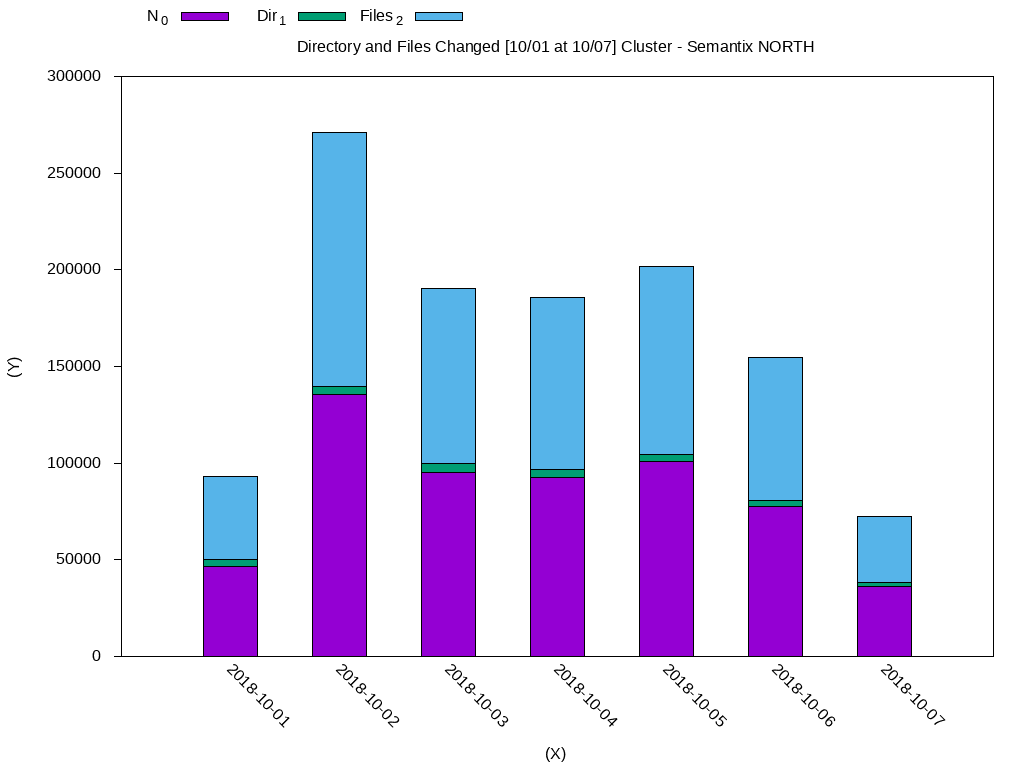
在这种情况下,大多数数据都使用复制块3.我们可以进行另一次分析,以检查在一周内修改的文件。下面,我使用weekly-changes.dat文件标准化了直方图的输出:
DateN_0Dir_1Files_2
2018-10-0146588.03579.043009.0
2018-10-02135548.04230.0131318.0
2018-10-0395226.04600.090626.0
2018-10-0492728.04128.088600.0
2018-10-05100969.03527.097442.0
2018-10-0677346.03455.073891.0
2018-10-0736326.01711.034615.0
使用GnuPlot:
#!的/ usr / bin中/ gnuplot的
重启
明确
设置数据文件分隔符“\ t”
设置终端PNG大小1024,768
设置输出“histogram-weekly-changes.png”
设置标题“目录和文件已更改[10/01 at 10/07] Cluster - Semantix NORTH”
设置 xlabel “(X)”
设置 ylabel “(Y)”
设置键顶部左水平autotitle columnhead外
设置 xtic旋转-45比例0
将 ytics 设置为nomirror
设置样式填充实线边框-1
设置 boxwidth 0 .5相对
设置样式数据直方图
设置样式直方图rowstacked
使用2:xtic(1)ti col,' u 3 ti col ''' u 4 ti col 绘制'weekly-changes.dat'
生成的数据如下所示:
我将留下一些可能有用的其他查询:
- 将Unix时间戳转换为ISO。
SELECT date_format(from_unixtime(cast(mtime / 1000 AS bigint)),'yyyy-MM-dd')
来自 fsimage_hdfs LIMIT 10 ;
- 检查所用块的大小并将字节转换为GB。
SELECT权限,
count(1)AS totalfiles,
轮(总和(铸造(preferredblocksize AS DOUBLE))/ 1024/1024/1024,2)AS sizegb
FROM fsimage_hdfs
在哪里 odate = '2019-01-22'
和 `cluster` = 'SEMANTIX_NORTH'
GROUP BY权限限制 10 ;
- 在特定日期修改的文件。
SELECT count(*)FROM fsimage_hdfs WHERE odate = '2018-12-22'
和 `cluster` = 'SEMANTIX_NORTH'
AND date_format(from_unixtime(cast(mtime / 1000 AS bigint)),
'yyyy-MM-dd')= '2019-01-22' ;