Apache Spark渐进式学习教程(十):Spark Streaming简介和系统架构
目录
一,Spark Streaming简介
二,Spark Streaming 系统架构
三,动态负载均衡
四,容错性
五,实时性、扩展性与吞吐量
一,Spark Streaming简介
Spark Streaming 是 Spark 核心 API 的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。Spark Streaming 支持从多种数据源获取数据,包括 Kafka、Flume、Twitter、ZeroMQ、Kinesis 以及 TCP Sockets。从数据源获取数据之后,可以使用诸如 map、reduce、join 和 window 等高级函数进行复杂算法的处理,最后还可以将处理结果存储到文件系统、数据库和现场仪表盘中。
在 Spark 统一环境的基础上,可以使用 Spark 的其他子框架,如机器学习、图计算等,对流数据进行处理。Spark Streaming 处理的数据流如图 1 所示。

图 1 Spark Streaming处理的数据流示意
与 Spark 的其他子框架一样,Spark Streaming 也是基于核心 Spark 的。Spark Streaming 在内部的处理机制是,接收实时的输入数据流,并根据一定的时间间隔(如 1 秒)拆分成一批批的数据,然后通过 Spark Engine 处理这些批数据,最终得到处理后的一批批结果数据。它的工作原理如图 2 所示。

图 2 Spark Streaming 原理示意
Spark Streaming 支持一个高层的抽象,叫作离散流(DiscretizedStream)或者 DStream,它代表连续的数据流。
DStream 既可以利用根据 Kafka、Flume 和 Kinesis 等数据源获取的输入数据流来创建,也可以在其他 DStream 的基础上通过高阶函数获得。
在内部,DStream 是由一系列 RDD 组成的。一批数据在 Spark 内核中对应一个 RDD 实例。因此,对应流数据的 DStream 可以看成是一组 RDD,即 RDD 的一个序列。也就是说,在流数据分成一批一批后,会通过一个先进先出的队列,Spark Engine 从该队列中依次取出一个个批数据,并把批数据封装成一个 RDD,然后再进行处理。
下面对 Spark Streaming 的一些常用术语进行说明。
| 名称 | 说明 |
|---|---|
| 离散流(Discretized Stream)或 DStream | Spark Streaming 对内部持续的实时数据流的抽象描述,即处理的一个实时数据流,在 Spark Streaming 中对应于一个 DStream 实例。 |
| 时间片或批处理时间间隔(BatchInterval) | 拆分流数据的时间单元,一般为 500 毫秒或 1 秒。 |
| 批数据(BatchData) | 一个时间片内所包含的流数据,表示成一个 RDD。 |
| 窗口(Window) | 一个时间段。系统支持对一个窗口内的数据进行计算 |
| 窗口长度(Window Length) | 一个窗口所覆盖的流数据的时间长度,必须是批处理时间间隔的倍数。 |
| 滑动步长(Sliding Interval) | 前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数。 |
| Input DStream | 一个 Input DStream 是一个特殊的 DStream。 |
二,Spark Streaming 系统架构
Spark Streaming 引入了一个新结构,即 DStream,它可以直接使用 Spark Engine 中丰富的库,并且拥有优秀的故障容错机制。
传统流处理采用的是一次处理一条记录的方式,而 Spark Streaming 采用的是将流数据进行离散化处理,使之能够进行秒级以下的微型批处理。同时,Spark Streaming 的 Receiver 并行接收数据,将数据缓存至 Spark 工作结点的内存中。
经过延迟优化后,Spark Engine 对短任务(几十毫秒)能够进行批处理,并且可将结果输出至别的系统中。Spark Streaming 的系统架构如图 2 所示。
值得注意的是,与传统连续算子模型不同,传统模型是静态分配给一个结点进行计算的,而 Spark Task 可基于数据的来源及可用资源情况动态分配给工作结点。这能够更好地实现流处理所需要的两个特性:负载均衡与快速故障恢复。此外,Executor 除了可以处理 Task 外,还可以将数据存在 cache 或者 HDFS 上。
Spark Streaming 中的流数据就是 Spark 的弹性分布式数据集(RDD),是 Spark 中容错数据集的一个基本抽象。正是如此,这些流数据才能使用 Spark 的任意指令与库。
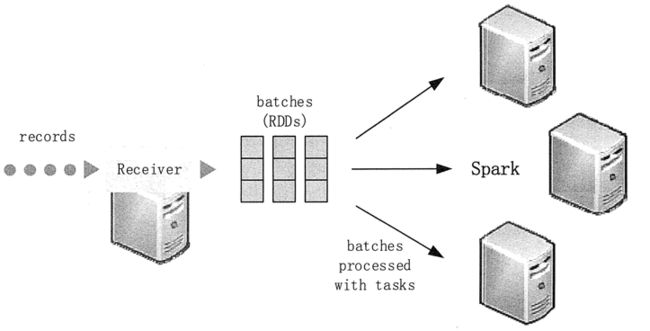
图 2 Spark Streaming 系统架构
Spark Streaming 是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是 Spark Core。
Spark Streaming 首先把输入数据按照批段大小(如 1 秒)分成一段一段的数据(DStream),并把每一段数据都转换成 Spark 中的 RDD,然后将 Spark Streaming 中对 DStream 的 Transformation 操作变为 Spark 中对 RDD 的 Transformation 操作,并将操作的中间结果保存在内存中。
整个流式计算根据业务的需求可以对中间的结果进行叠加,或者存储到外部设备。图 3 显示了 Spark Streaming 的整个计算流程。
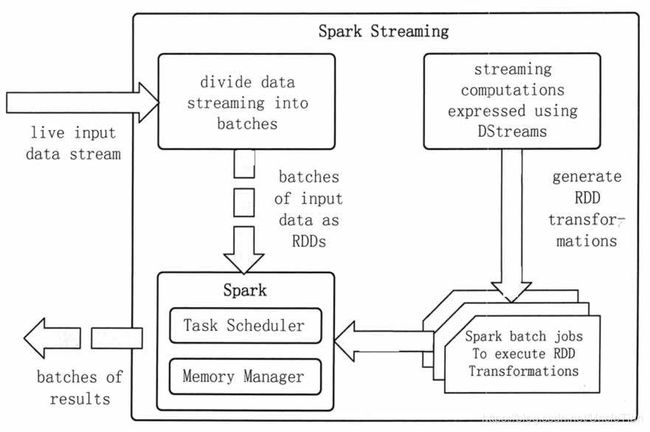
图 3 Spark Streaming计算流程
三,动态负载均衡
Spark 系统将数据划分为小批量,允许对资源进行细粒度分配。
传统的流处理系统采用静态方式分配任务给结点,如果其中的一个分区的计算比别的分区更密集,那么该结点的处理将会遇到性能瓶颈,同时将会减缓管道处理。而在 Spark Streaming 中,作业任务将会动态地平衡分配给各个结点,一些结点会处理数量较少且耗时较长的任务,别的结点将会处理数量更多且耗时更短的任务。
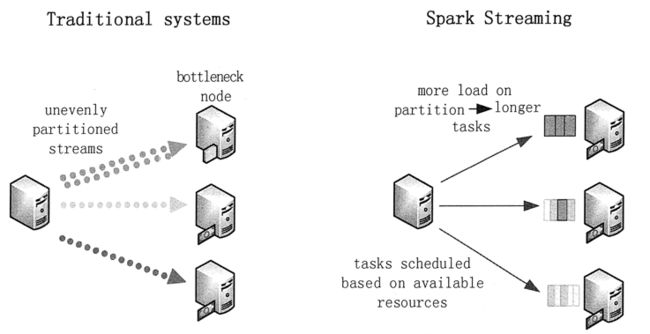
静态和动态负载均衡的对比如图 4 所示。
四,容错性
对于流式计算来说,容错性至关重要。首先来介绍 Spark 中 RDD 的容错机制。每一个 RDD 都是一个不可变的分布式可重算的数据集,其记录着确定性的操作血缘关系,所以只要输入数据是可容错的,则任意一个 RDD 的分区都可以利用原始输入数据通过转换操作而重新计算来得到。
对于 Spark Streaming 来说,其 RDD 的血缘关系如图 5 所示,图中的每一个椭圆形表示一个 RDD,椭圆形中的每个圆形代表一个 RDD 中的一个 Partition,图中的每一列的多个 RDD 表示一个 DStream,而每一行最后一个 RDD 则表示每一个 Batch Size 所产生的中间结果 RDD。
我们可以看到,图 5 中的每一个 RDD 都是通过血缘相连接的,RDD 中任意的 Partition 出错,都可以并行地在其他机器上将缺失的 Partition 计算出来。这个容错恢复方式比连续计算模型的效率更高。
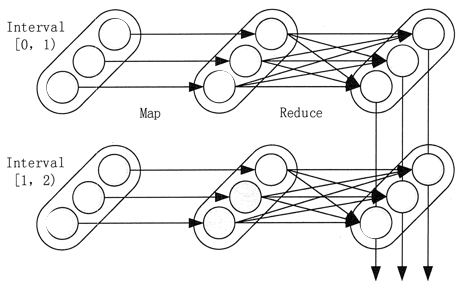
图 5 Spark Streaming中RDD的血缘关系图
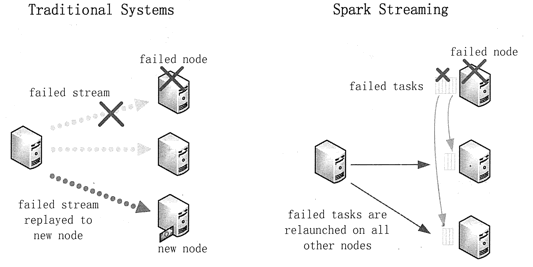
在结点故障的案例中,传统系统会在别的结点上重启失败的连续算子。为了重新计算丢失的信息,不得不重新运行一遍先前的数据流处理过程。此时,只有一个结点能够处理重新计算,并且整个管道将无法继续进行工作,直至新的结点信息已经恢复到故障前的状态。
在 Spark Streaming 中,计算将被拆分成多个小的任务,保证能在任何地方运行而又不影响合并后结果的正确性。因此,失败的任务可以同时重新在集群结点上并行处理,从而均匀地分布在所有重新计算情况下的众多结点中,这样相比于传统方法能够更快地从故障中恢复过来。两种故障恢复方式的比较如图 6 所示。
五,实时性、扩展性与吞吐量
Spark Streaming 将流式计算分解成多个 Spark Job,对于每一段数据的处理都会经过 Spark DAG 的图分解过程及 Spark 的任务集的调度过程。
对于目前版本的 Spark Streaming 而言,其最小的批次大小的选取为 0.5~2 秒,所以 Spark Streaming 能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
Spark 目前在 EC2 上已能够线性扩展到 100 个结点(每个结点 4Core),可以以数秒的延迟处理 6GB/秒的数据量,吞吐量可达 60MB 条记录/秒。
图 7 是利用 WordCount 和 Grep 两个用例所做的测试,在 Grep 这个测试中,Spark Streaming 中的每个结点的吞吐量是 670KB 条记录/秒,而 Storm 中的每个结点的吞吐量是 115KB 条记录/秒。

图 7 Spark Streaming 与 Storm 吞吐量比较
转载请注明出处。
本文参考:https://www.t9vg.com/archives/649